 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling on Symmetric $α$-Stable Bandits
Jul 08, 2019
Thompson Sampling provides an efficient technique to introduce prior knowledge in the multi-armed bandit problem, along with providing remarkable empirical performance. In this paper, we revisit the Thompson Sampling algorithm under rewards drawn from symmetric $\alpha$-stable distributions, which are a class of heavy-tailed probability distributions utilized in finance and economics, in problems such as modeling stock prices and human behavior. We present an efficient framework for posterior inference, which leads to two algorithms for Thompson Sampling in this setting. We prove finite-time regret bounds for both algorithms, and demonstrate through a series of experiments the stronger performance of Thompson Sampling in this setting. With our results, we provide an exposition of symmetric $\alpha$-stable distributions in sequential decision-making, and enable sequential Bayesian inference in applications from diverse fields in finance and complex systems that operate on heavy-tailed features.
Defense Against Adversarial Images using Web-Scale Nearest-Neighbor Search
Mar 05, 2019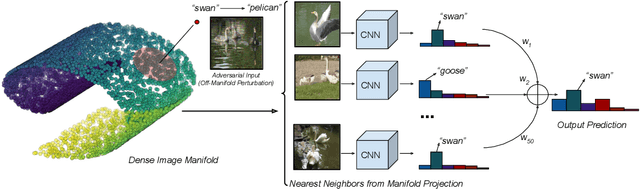


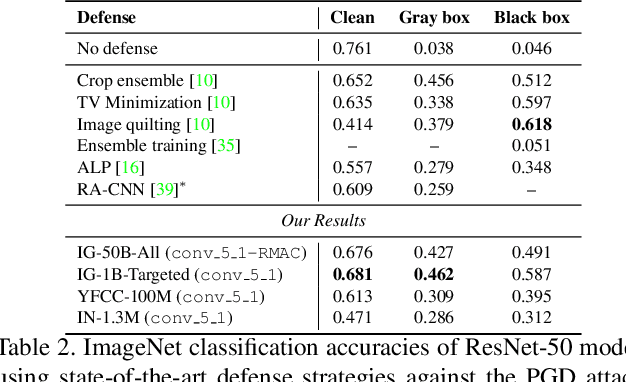
A plethora of recent work has shown that convolutional networks are not robust to adversarial images: images that are created by perturbing a sample from the data distribution as to maximize the loss on the perturbed example. In this work, we hypothesize that adversarial perturbations move the image away from the image manifold in the sense that there exists no physical process that could have produced the adversarial image. This hypothesis suggests that a successful defense mechanism against adversarial images should aim to project the images back onto the image manifold. We study such defense mechanisms, which approximate the projection onto the unknown image manifold by a nearest-neighbor search against a web-scale image database containing tens of billions of images. Empirical evaluations of this defense strategy on ImageNet suggest that it is very effective in attack settings in which the adversary does not have access to the image database. We also propose two novel attack methods to break nearest-neighbor defenses, and demonstrate conditions under which nearest-neighbor defense fails. We perform a series of ablation experiments, which suggest that there is a trade-off between robustness and accuracy in our defenses, that a large image database (with hundreds of millions of images) is crucial to get good performance, and that careful construction the image database is important to be robust against attacks tailored to circumvent our defenses.
Communication Topologies Between Learning Agents in Deep Reinforcement Learning
Feb 16, 2019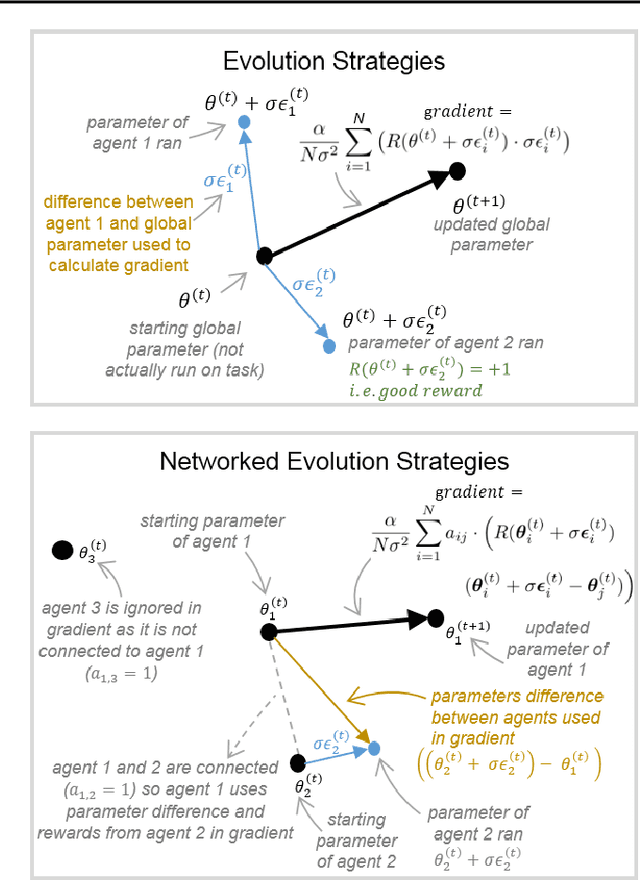

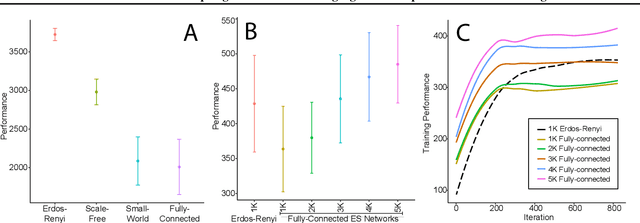
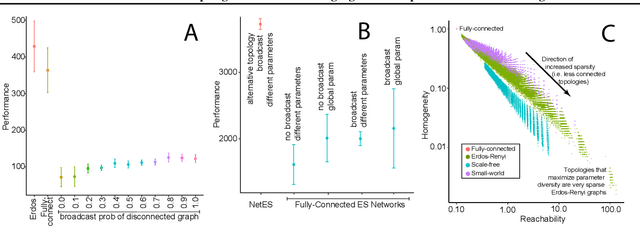
A common technique to improve speed and robustness of learning in deep reinforcement learning (DRL) and many other machine learning algorithms is to run multiple learning agents in parallel. A neglected component in the development of these algorithms has been how best to arrange the learning agents involved to better facilitate distributed search. Here we draw upon results from the networked optimization and collective intelligence literatures suggesting that arranging learning agents in less than fully connected topologies (the implicit way agents are commonly arranged in) can improve learning. We explore the relative performance of four popular families of graphs and observe that one such family (Erdos-Renyi random graphs) empirically outperforms the standard fully-connected communication topology across several DRL benchmark tasks. We observe that 1000 learning agents arranged in an Erdos-Renyi graph can perform as well as 3000 agents arranged in the standard fully-connected topology, showing the large learning improvement possible when carefully designing the topology over which agents communicate. We complement these empirical results with a preliminary theoretical investigation of why less than fully connected topologies can perform better. Overall, our work suggests that distributed machine learning algorithms could be made more efficient if the communication topology between learning agents was optimized.
Evaluating Generative Adversarial Networks on Explicitly Parameterized Distributions
Dec 27, 2018
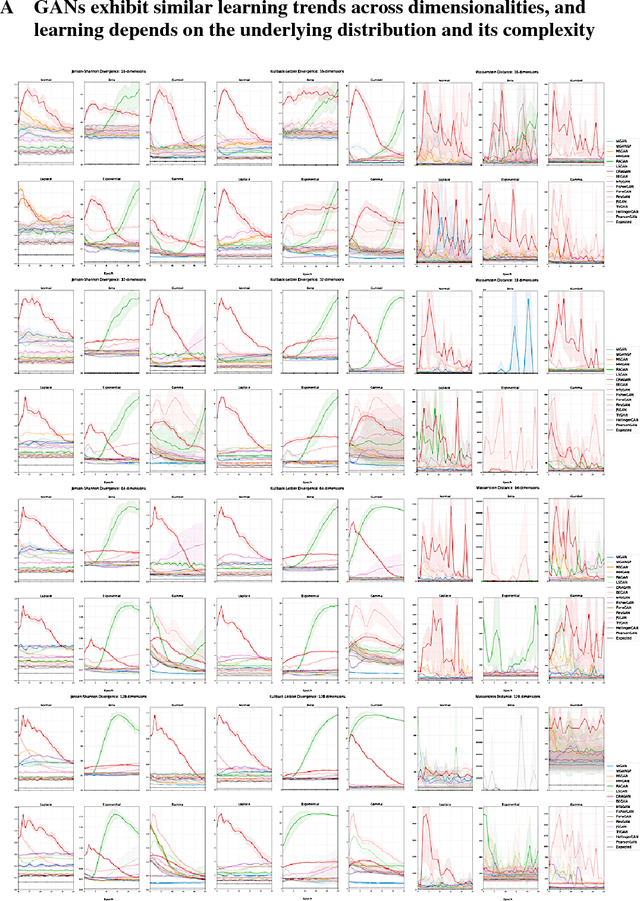
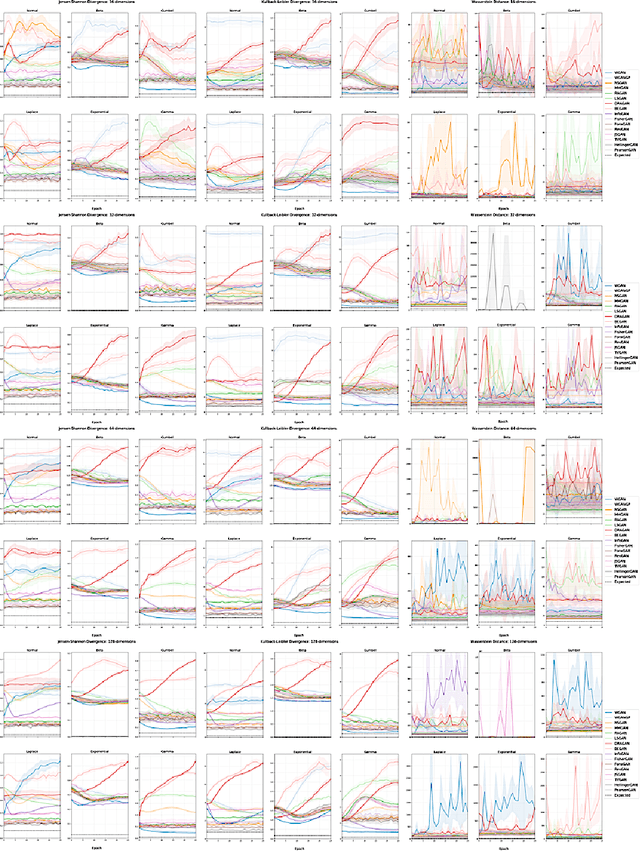
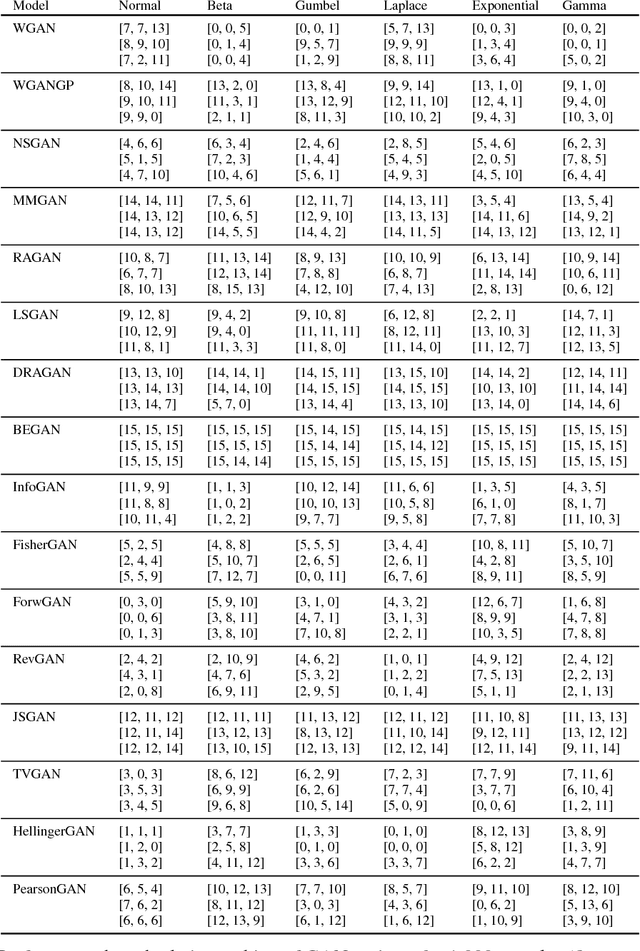
The true distribution parameterizations of commonly used image datasets are inaccessible. Rather than designing metrics for feature spaces with unknown characteristics, we propose to measure GAN performance by evaluating on explicitly parameterized, synthetic data distributions. As a case study, we examine the performance of 16 GAN variants on six multivariate distributions of varying dimensionalities and training set sizes. In this learning environment, we observe that: GANs exhibit similar performance trends across dimensionalities; learning depends on the underlying distribution and its complexity; the number of training samples can have a large impact on performance; evaluation and relative comparisons are metric-dependent; diverse sets of hyperparameters can produce a "best" result; and some GANs are more robust to hyperparameter changes than others. These observations both corroborate findings of previous GAN evaluation studies and make novel contributions regarding the relationship between size, complexity, and GAN performance.
No Peek: A Survey of private distributed deep learning
Dec 08, 2018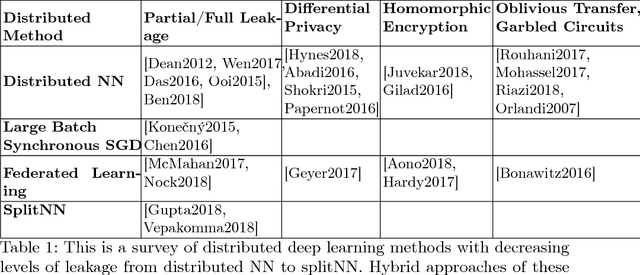
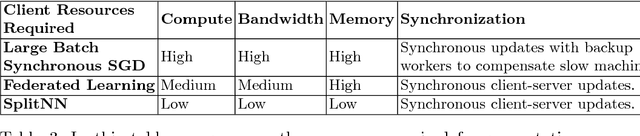
We survey distributed deep learning models for training or inference without accessing raw data from clients. These methods aim to protect confidential patterns in data while still allowing servers to train models. The distributed deep learning methods of federated learning, split learning and large batch stochastic gradient descent are compared in addition to private and secure approaches of differential privacy, homomorphic encryption, oblivious transfer and garbled circuits in the context of neural networks. We study their benefits, limitations and trade-offs with regards to computational resources, data leakage and communication efficiency and also share our anticipated future trends.
How to Organize your Deep Reinforcement Learning Agents: The Importance of Communication Topology
Nov 30, 2018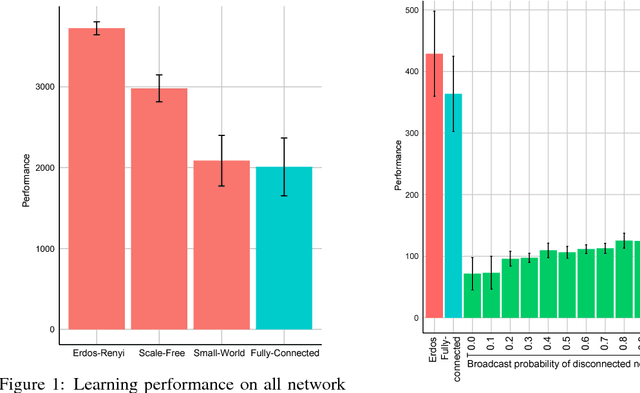

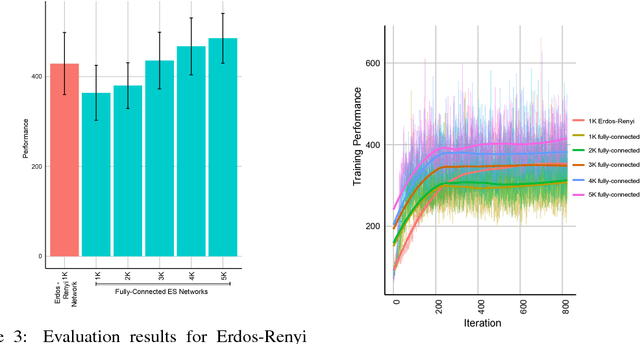
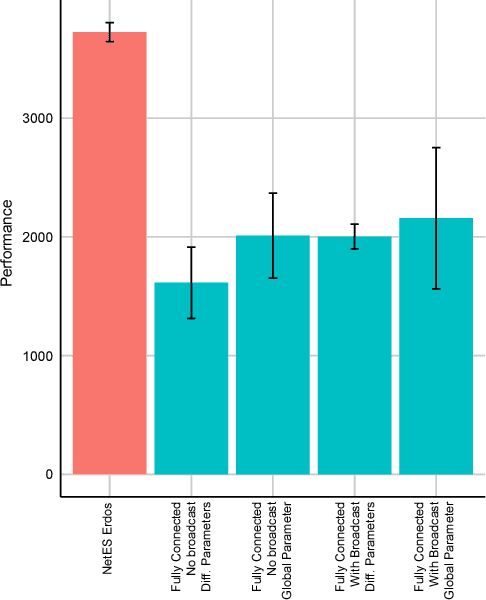
In this empirical paper, we investigate how learning agents can be arranged in more efficient communication topologies for improved learning. This is an important problem because a common technique to improve speed and robustness of learning in deep reinforcement learning and many other machine learning algorithms is to run multiple learning agents in parallel. The standard communication architecture typically involves all agents intermittently communicating with each other (fully connected topology) or with a centralized server (star topology). Unfortunately, optimizing the topology of communication over the space of all possible graphs is a hard problem, so we borrow results from the networked optimization and collective intelligence literatures which suggest that certain families of network topologies can lead to strong improvements over fully-connected networks. We start by introducing alternative network topologies to DRL benchmark tasks under the Evolution Strategies paradigm which we call Network Evolution Strategies. We explore the relative performance of the four main graph families and observe that one such family (Erdos-Renyi random graphs) empirically outperforms all other families, including the de facto fully-connected communication topologies. Additionally, the use of alternative network topologies has a multiplicative performance effect: we observe that when 1000 learning agents are arranged in a carefully designed communication topology, they can compete with 3000 agents arranged in the de facto fully-connected topology. Overall, our work suggests that distributed machine learning algorithms would learn more efficiently if the communication topology between learning agents was optimized.
Maximum-Entropy Fine-Grained Classification
Sep 20, 2018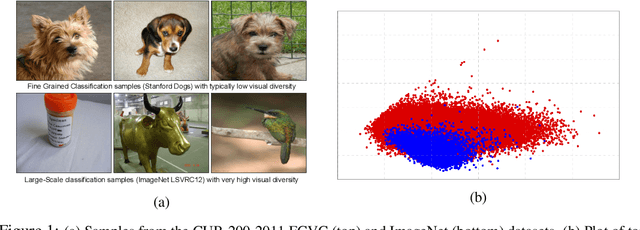
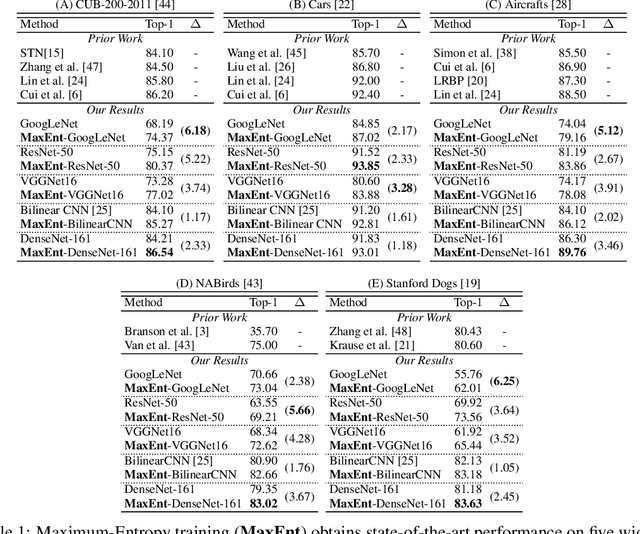
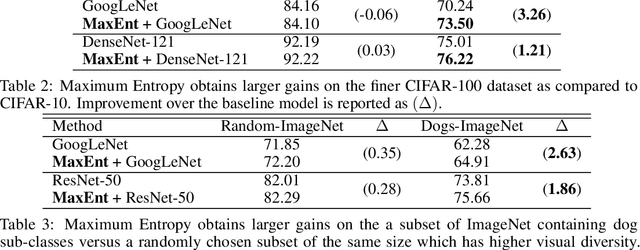
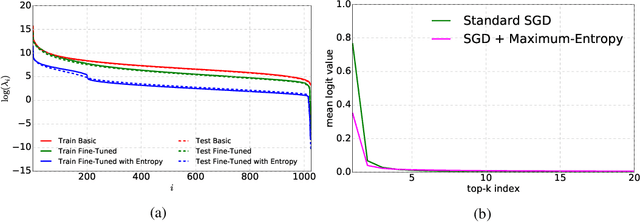
Fine-Grained Visual Classification (FGVC) is an important computer vision problem that involves small diversity within the different classes, and often requires expert annotators to collect data. Utilizing this notion of small visual diversity, we revisit Maximum-Entropy learning in the context of fine-grained classification, and provide a training routine that maximizes the entropy of the output probability distribution for training convolutional neural networks on FGVC tasks. We provide a theoretical as well as empirical justification of our approach, and achieve state-of-the-art performance across a variety of classification tasks in FGVC, that can potentially be extended to any fine-tuning task. Our method is robust to different hyperparameter values, amount of training data and amount of training label noise and can hence be a valuable tool in many similar problems.
Pairwise Confusion for Fine-Grained Visual Classification
Jul 25, 2018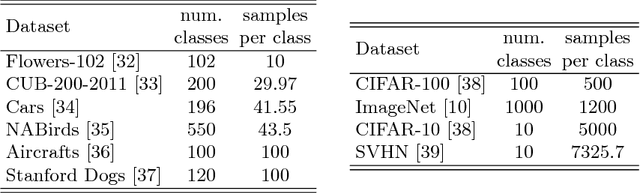
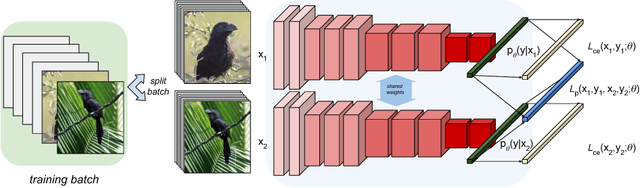
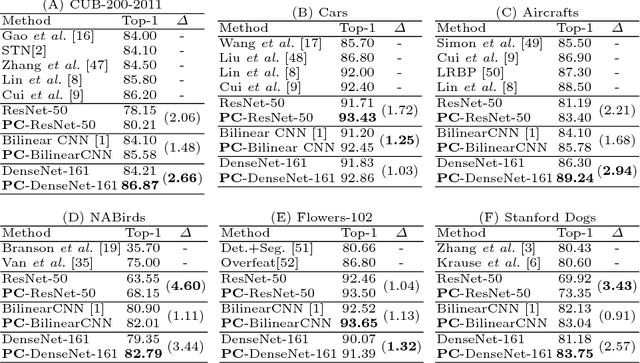
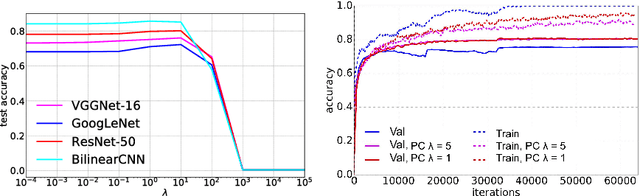
Fine-Grained Visual Classification (FGVC) datasets contain small sample sizes, along with significant intra-class variation and inter-class similarity. While prior work has addressed intra-class variation using localization and segmentation techniques, inter-class similarity may also affect feature learning and reduce classification performance. In this work, we address this problem using a novel optimization procedure for the end-to-end neural network training on FGVC tasks. Our procedure, called Pairwise Confusion (PC) reduces overfitting by intentionally {introducing confusion} in the activations. With PC regularization, we obtain state-of-the-art performance on six of the most widely-used FGVC datasets and demonstrate improved localization ability. {PC} is easy to implement, does not need excessive hyperparameter tuning during training, and does not add significant overhead during test time.
Coreset-Based Neural Network Compression
Jul 25, 2018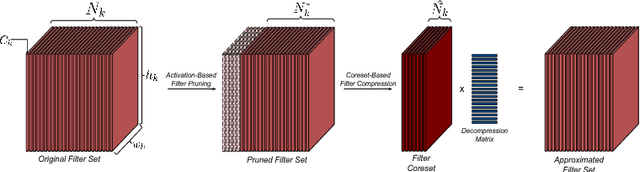
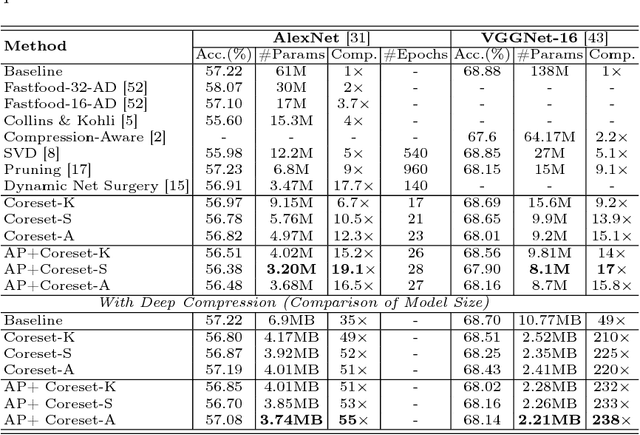
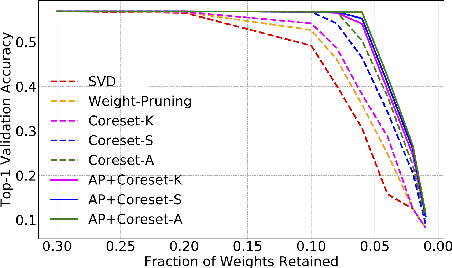
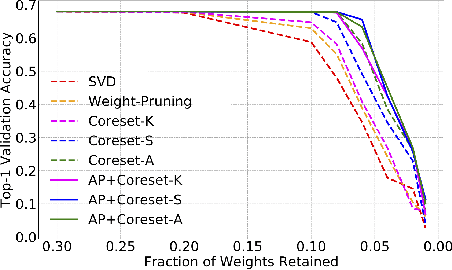
We propose a novel Convolutional Neural Network (CNN) compression algorithm based on coreset representations of filters. We exploit the redundancies extant in the space of CNN weights and neuronal activations (across samples) in order to obtain compression. Our method requires no retraining, is easy to implement, and obtains state-of-the-art compression performance across a wide variety of CNN architectures. Coupled with quantization and Huffman coding, we create networks that provide AlexNet-like accuracy, with a memory footprint that is $832\times$ smaller than the original AlexNet, while also introducing significant reductions in inference time as well. Additionally these compressed networks when fine-tuned, successfully generalize to other domains as well.
Closing the AI Knowledge Gap
Mar 20, 2018
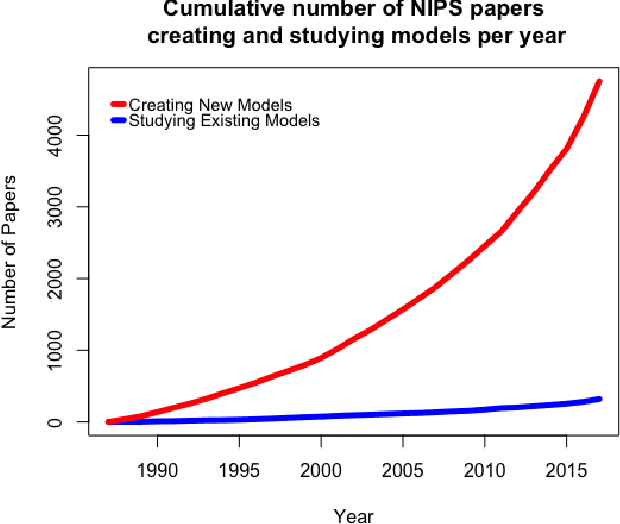
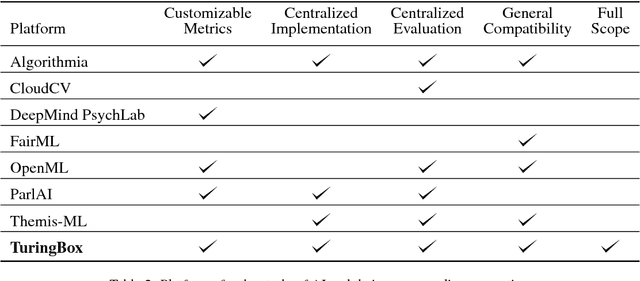
AI researchers employ not only the scientific method, but also methodology from mathematics and engineering. However, the use of the scientific method - specifically hypothesis testing - in AI is typically conducted in service of engineering objectives. Growing interest in topics such as fairness and algorithmic bias show that engineering-focused questions only comprise a subset of the important questions about AI systems. This results in the AI Knowledge Gap: the number of unique AI systems grows faster than the number of studies that characterize these systems' behavior. To close this gap, we argue that the study of AI could benefit from the greater inclusion of researchers who are well positioned to formulate and test hypotheses about the behavior of AI systems. We examine the barriers preventing social and behavioral scientists from conducting such studies. Our diagnosis suggests that accelerating the scientific study of AI systems requires new incentives for academia and industry, mediated by new tools and institutions. To address these needs, we propose a two-sided marketplace called TuringBox. On one side, AI contributors upload existing and novel algorithms to be studied scientifically by others. On the other side, AI examiners develop and post machine intelligence tasks designed to evaluate and characterize algorithmic behavior. We discuss this market's potential to democratize the scientific study of AI behavior, and thus narrow the AI Knowledge Gap.