 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCA-Agent: A Market-of-Claims Code Agent for Financial and Numerical Reasoning
Jun 10, 2026Financial and tabular question answering requires more than fluent reasoning: answers must be grounded in the exact facts, formulas, units, signs, and scales that support them. A single misread cell or incorrect operation can silently produce a plausible but wrong result. We introduce \textsc{MOCA-Agent}, a market-of-claims code agent that replaces free-form multi-agent debate with claim-level verification. The system decomposes each question into typed atomic claims, asks specialist trader agents to buy or sell those claims, clears their orders into confidence-weighted accept/reject decisions, and synthesizes an executable Python program from market-supported evidence. A code-aware verifier then checks the program for execution, structural consistency, and common financial reasoning errors, with at most one market-aware repair round. Across ten public benchmarks spanning financial numerical reasoning, general tabular reasoning, ESG question answering, and multimodal chart reasoning, \textsc{MOCA-Agent} achieves strong performance using a fixed Qwen3.6-27B backbone, including $78.3\%$ on FinQA, $76.0\%$ on FinanceMath, $71.2\%$ on MultiHiertt, $86.9\%$ on ESGenius, and $85.6\%$ average on FinChart-Bench. These results show that aggregating evidence at the level of atomic claims, rather than whole answers, improves robustness in high-stakes numerical reasoning.\footnote{The code and data are available: https://github.com/UBC-NLP/MoCA-Agent.
Alexandria: A Multi-Domain Dialectal Arabic Machine Translation Dataset for Culturally Inclusive and Linguistically Diverse LLMs
Jan 19, 2026Arabic is a highly diglossic language where most daily communication occurs in regional dialects rather than Modern Standard Arabic. Despite this, machine translation (MT) systems often generalize poorly to dialectal input, limiting their utility for millions of speakers. We introduce \textbf{Alexandria}, a large-scale, community-driven, human-translated dataset designed to bridge this gap. Alexandria covers 13 Arab countries and 11 high-impact domains, including health, education, and agriculture. Unlike previous resources, Alexandria provides unprecedented granularity by associating contributions with city-of-origin metadata, capturing authentic local varieties beyond coarse regional labels. The dataset consists of multi-turn conversational scenarios annotated with speaker-addressee gender configurations, enabling the study of gender-conditioned variation in dialectal use. Comprising 107K total samples, Alexandria serves as both a training resource and a rigorous benchmark for evaluating MT and Large Language Models (LLMs). Our automatic and human evaluation of Arabic-aware LLMs benchmarks current capabilities in translating across diverse Arabic dialects and sub-dialects, while exposing significant persistent challenges.
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
Arabic Inquiry-Answer Dialogue Acts Annotation Schema
May 15, 2015
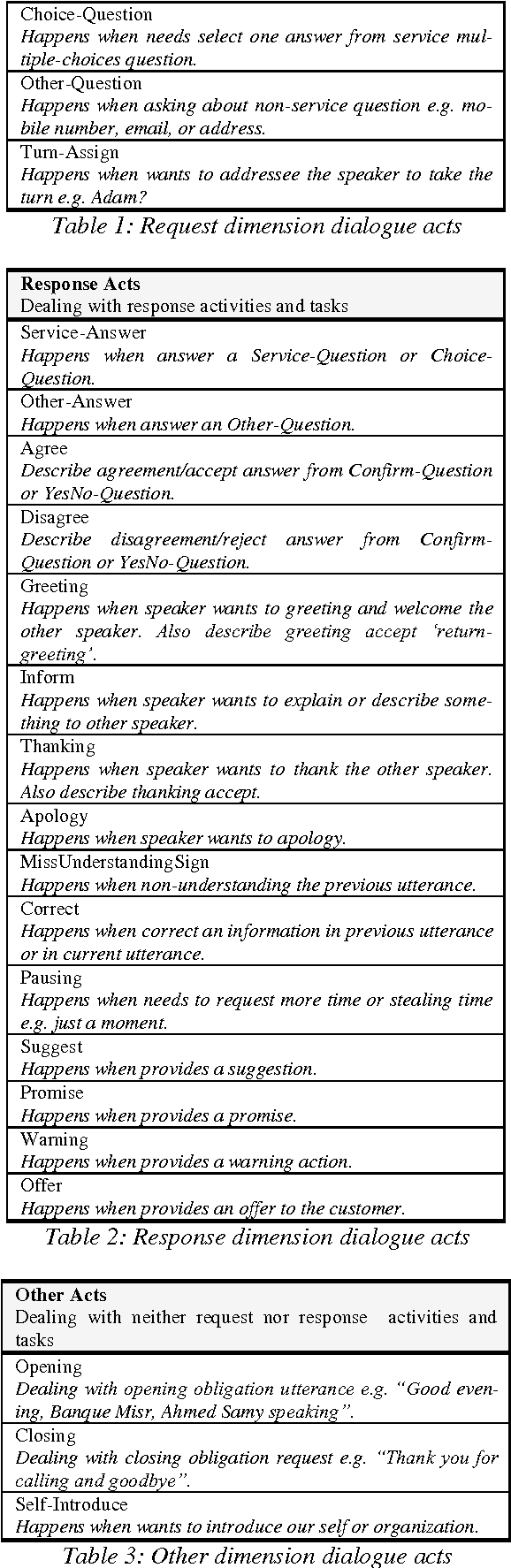

We present an annotation schema as part of an effort to create a manually annotated corpus for Arabic dialogue language understanding including spoken dialogue and written "chat" dialogue for inquiry-answer domain. The proposed schema handles mainly the request and response acts that occurs frequently in inquiry-answer debate conversations expressing request services, suggests, and offers. We applied the proposed schema on 83 Arabic inquiry-answer dialogues.
A Survey of Arabic Dialogues Understanding for Spontaneous Dialogues and Instant Message
May 12, 2015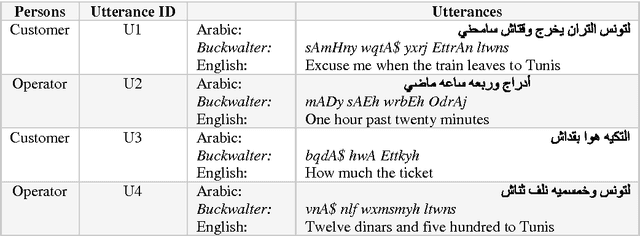
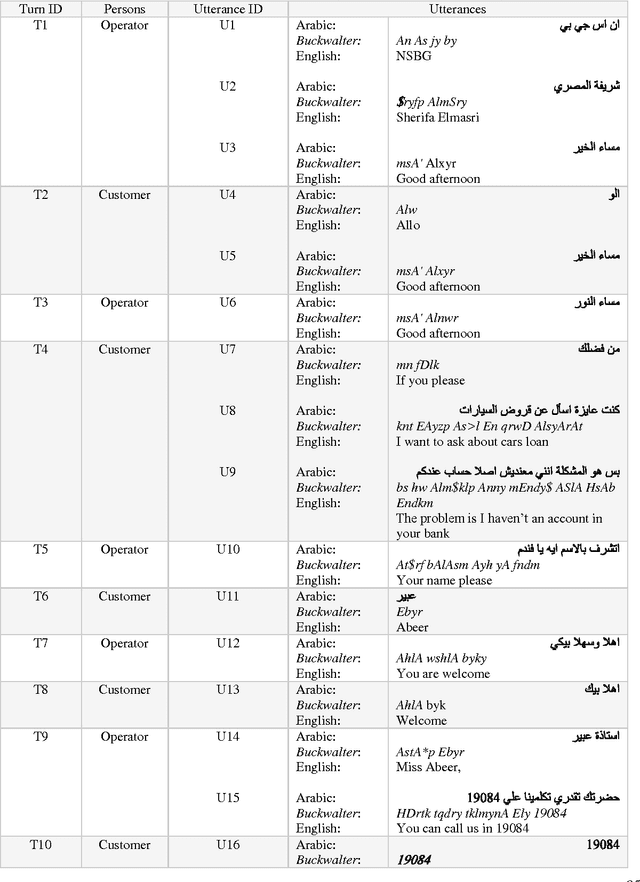
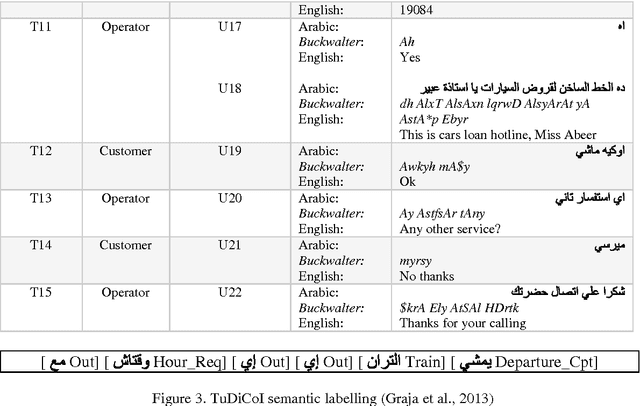
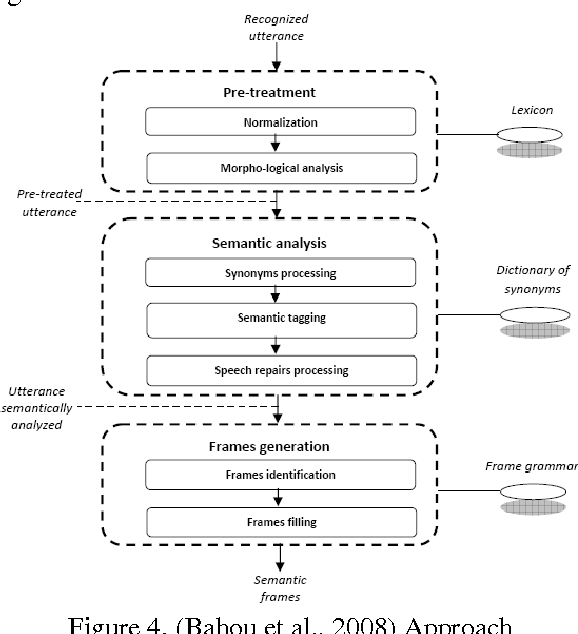
Building dialogues systems interaction has recently gained considerable attention, but most of the resources and systems built so far are tailored to English and other Indo-European languages. The need for designing systems for other languages is increasing such as Arabic language. For this reasons, there are more interest for Arabic dialogue acts classification task because it a key player in Arabic language understanding to building this systems. This paper surveys different techniques for dialogue acts classification for Arabic. We describe the main existing techniques for utterances segmentations and classification, annotation schemas, and test corpora for Arabic dialogues understanding that have introduced in the literature
Turn Segmentation into Utterances for Arabic Spontaneous Dialogues and Instance Messages
May 12, 2015
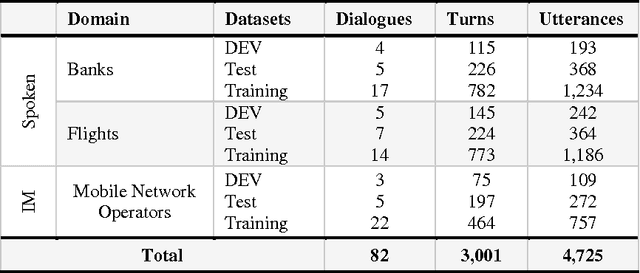
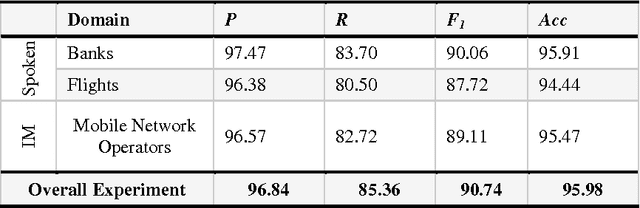
Text segmentation task is an essential processing task for many of Natural Language Processing (NLP) such as text summarization, text translation, dialogue language understanding, among others. Turns segmentation considered the key player in dialogue understanding task for building automatic Human-Computer systems. In this paper, we introduce a novel approach to turn segmentation into utterances for Egyptian spontaneous dialogues and Instance Messages (IM) using Machine Learning (ML) approach as a part of automatic understanding Egyptian spontaneous dialogues and IM task. Due to the lack of Egyptian dialect dialogue corpus the system evaluated by our corpus includes 3001 turns, which are collected, segmented, and annotated manually from Egyptian call-centers. The system achieves F1 scores of 90.74% and accuracy of 95.98%.