 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Dialogue Act Classification for Spontaneous Arabic Speech and Instant Messages at Utterance Level
May 30, 2018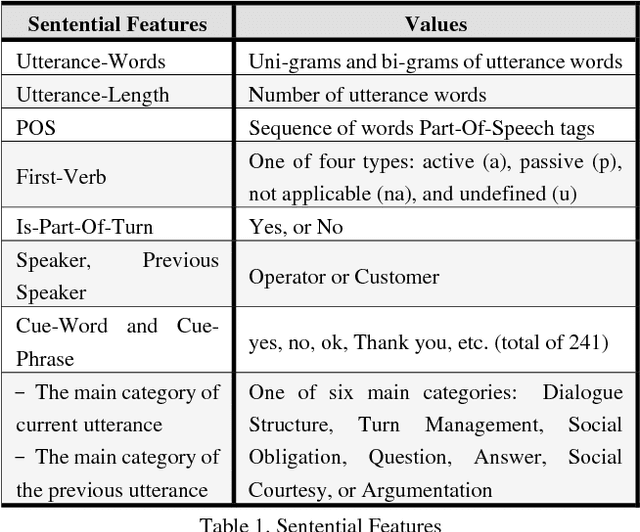
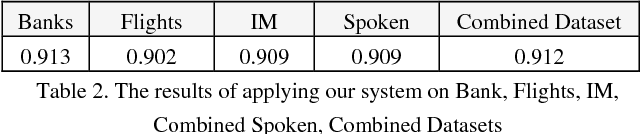

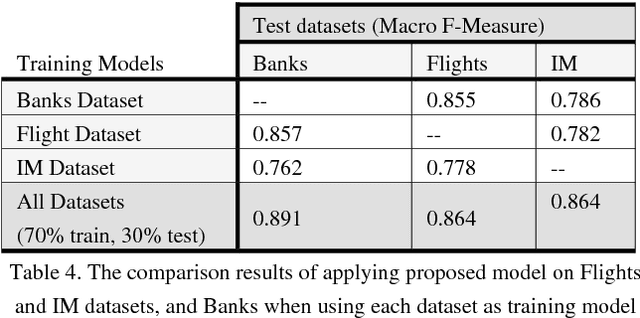
The ability to model and automatically detect dialogue act is an important step toward understanding spontaneous speech and Instant Messages. However, it has been difficult to infer a dialogue act from a surface utterance because it highly depends on the context of the utterance and speaker linguistic knowledge; especially in Arabic dialects. This paper proposes a statistical dialogue analysis model to recognize utterance's dialogue acts using a multi-classes hierarchical structure. The model can automatically acquire probabilistic discourse knowledge from a dialogue corpus were collected and annotated manually from multi-genre Egyptian call-centers. Extensive experiments were conducted using Support Vector Machines classifier to evaluate the system performance. The results attained in the term of average F-measure scores of 0.912; showed that the proposed approach has moderately improved F-measure by approximately 20%.
Towards Understanding Egyptian Arabic Dialogues
Jul 14, 2015
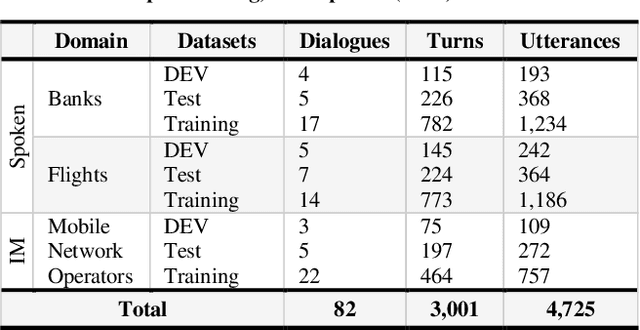
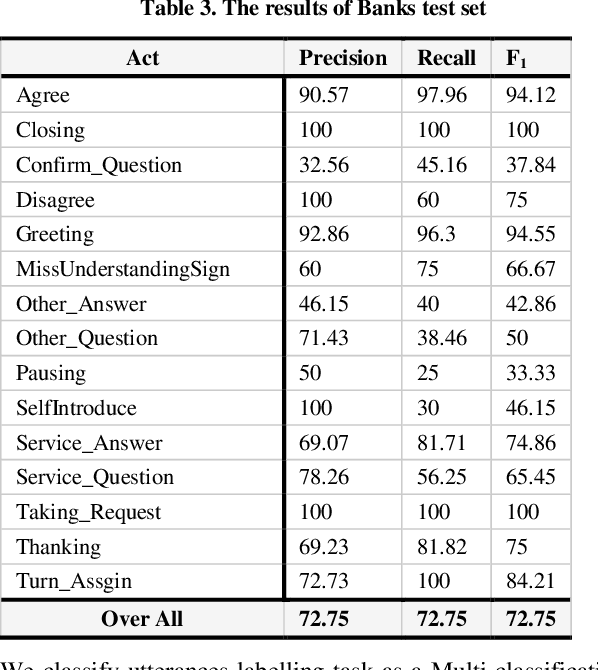
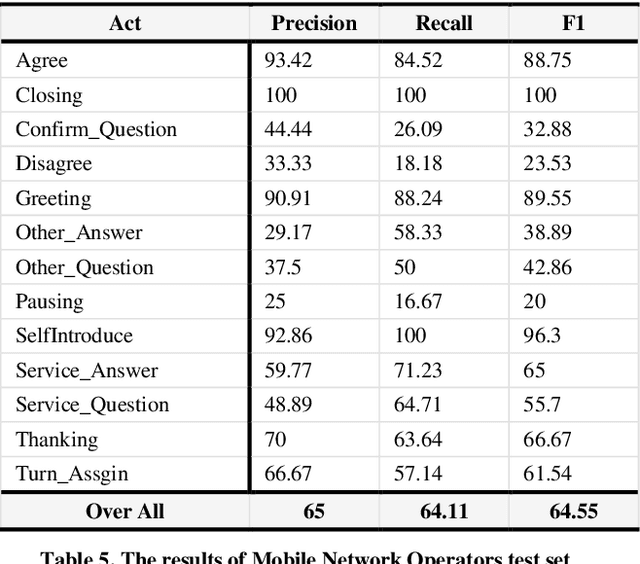
Labelling of user's utterances to understanding his attends which called Dialogue Act (DA) classification, it is considered the key player for dialogue language understanding layer in automatic dialogue systems. In this paper, we proposed a novel approach to user's utterances labeling for Egyptian spontaneous dialogues and Instant Messages using Machine Learning (ML) approach without relying on any special lexicons, cues, or rules. Due to the lack of Egyptian dialect dialogue corpus, the system evaluated by multi-genre corpus includes 4725 utterances for three domains, which are collected and annotated manually from Egyptian call-centers. The system achieves F1 scores of 70. 36% overall domains.
* arXiv admin note: substantial text overlap with arXiv:1505.03081
Idioms-Proverbs Lexicon for Modern Standard Arabic and Colloquial Sentiment Analysis
Jun 05, 2015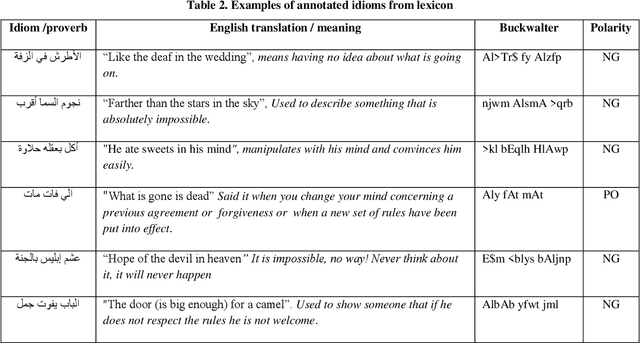
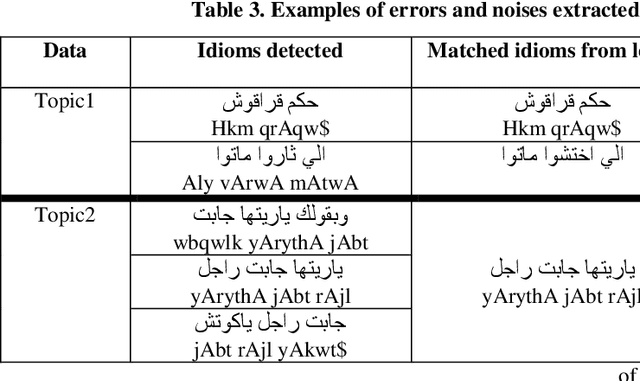

Although, the fair amount of works in sentiment analysis (SA) and opinion mining (OM) systems in the last decade and with respect to the performance of these systems, but it still not desired performance, especially for morphologically-Rich Language (MRL) such as Arabic, due to the complexities and challenges exist in the nature of the languages itself. One of these challenges is the detection of idioms or proverbs phrases within the writer text or comment. An idiom or proverb is a form of speech or an expression that is peculiar to itself. Grammatically, it cannot be understood from the individual meanings of its elements and can yield different sentiment when treats as separate words. Consequently, In order to facilitate the task of detection and classification of lexical phrases for automated SA systems, this paper presents AIPSeLEX a novel idioms/ proverbs sentiment lexicon for modern standard Arabic (MSA) and colloquial. AIPSeLEX is manually collected and annotated at sentence level with semantic orientation (positive or negative). The efforts of manually building and annotating the lexicon are reported. Moreover, we build a classifier that extracts idioms and proverbs, phrases from text using n-gram and similarity measure methods. Finally, several experiments were carried out on various data, including Arabic tweets and Arabic microblogs (hotel reservation, product reviews, and TV program comments) from publicly available Arabic online reviews websites (social media, blogs, forums, e-commerce web sites) to evaluate the coverage and accuracy of AIPSeLEX.
* arXiv admin note: text overlap with arXiv:1505.03105
Arabic Inquiry-Answer Dialogue Acts Annotation Schema
May 15, 2015
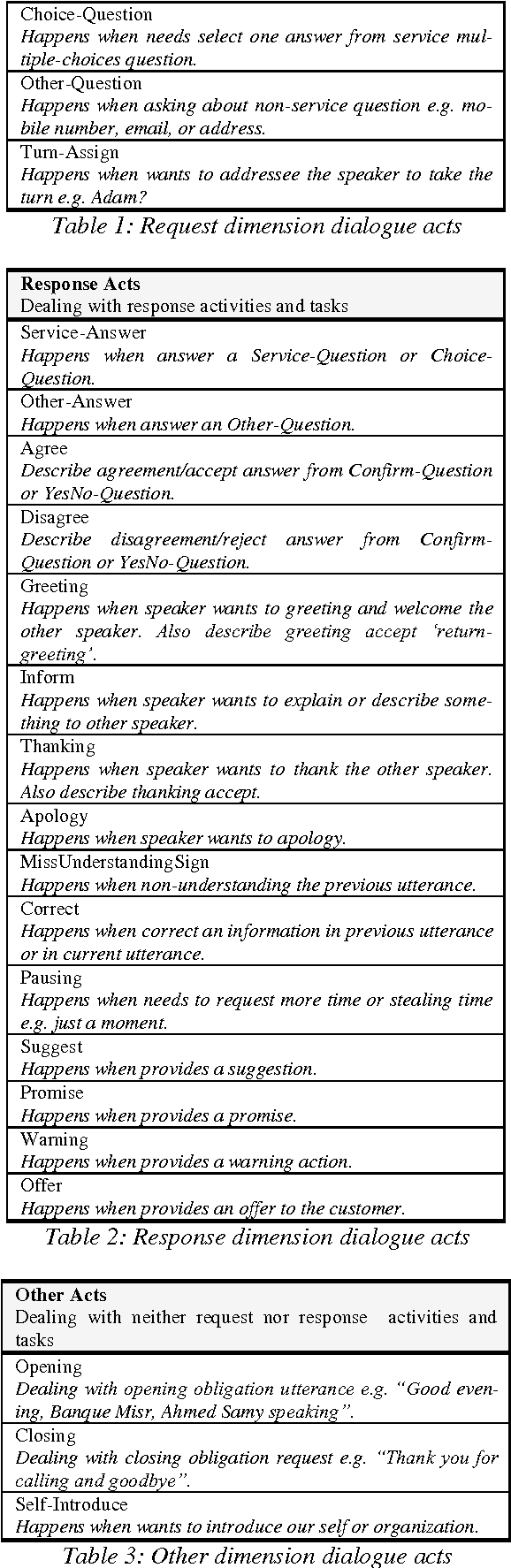

We present an annotation schema as part of an effort to create a manually annotated corpus for Arabic dialogue language understanding including spoken dialogue and written "chat" dialogue for inquiry-answer domain. The proposed schema handles mainly the request and response acts that occurs frequently in inquiry-answer debate conversations expressing request services, suggests, and offers. We applied the proposed schema on 83 Arabic inquiry-answer dialogues.
Sentiment Analysis For Modern Standard Arabic And Colloquial
May 12, 2015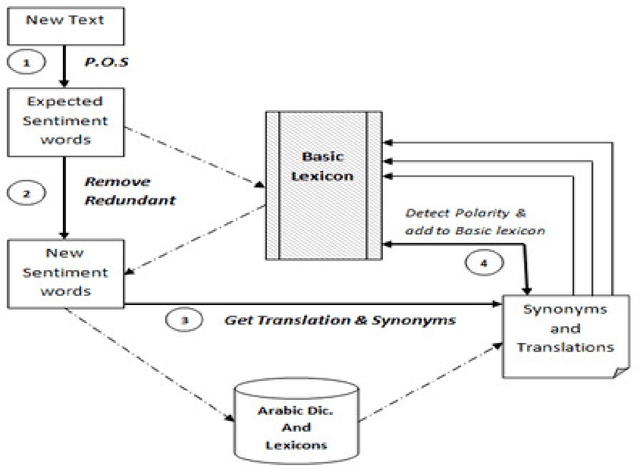



The rise of social media such as blogs and social networks has fueled interest in sentiment analysis. With the proliferation of reviews, ratings, recommendations and other forms of online expression, online opinion has turned into a kind of virtual currency for businesses looking to market their products, identify new opportunities and manage their reputations, therefore many are now looking to the field of sentiment analysis. In this paper, we present a feature-based sentence level approach for Arabic sentiment analysis. Our approach is using Arabic idioms/saying phrases lexicon as a key importance for improving the detection of the sentiment polarity in Arabic sentences as well as a number of novels and rich set of linguistically motivated features contextual Intensifiers, contextual Shifter and negation handling), syntactic features for conflicting phrases which enhance the sentiment classification accuracy. Furthermore, we introduce an automatic expandable wide coverage polarity lexicon of Arabic sentiment words. The lexicon is built with gold-standard sentiment words as a seed which is manually collected and annotated and it expands and detects the sentiment orientation automatically of new sentiment words using synset aggregation technique and free online Arabic lexicons and thesauruses. Our data focus on modern standard Arabic (MSA) and Egyptian dialectal Arabic tweets and microblogs (hotel reservation, product reviews, etc.). The experimental results using our resources and techniques with SVM classifier indicate high performance levels, with accuracies of over 95%.
A Survey of Arabic Dialogues Understanding for Spontaneous Dialogues and Instant Message
May 12, 2015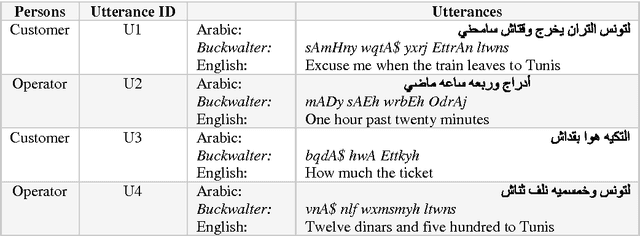
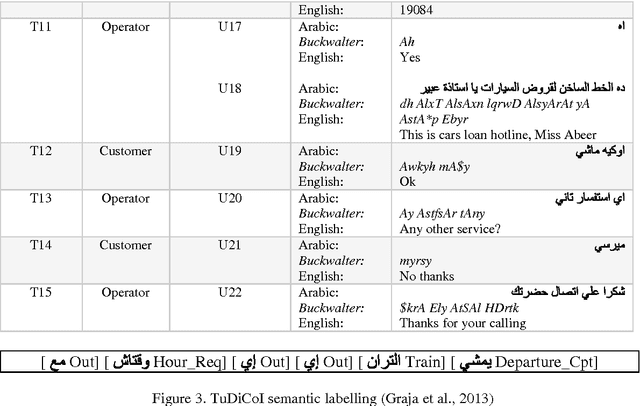
Building dialogues systems interaction has recently gained considerable attention, but most of the resources and systems built so far are tailored to English and other Indo-European languages. The need for designing systems for other languages is increasing such as Arabic language. For this reasons, there are more interest for Arabic dialogue acts classification task because it a key player in Arabic language understanding to building this systems. This paper surveys different techniques for dialogue acts classification for Arabic. We describe the main existing techniques for utterances segmentations and classification, annotation schemas, and test corpora for Arabic dialogues understanding that have introduced in the literature
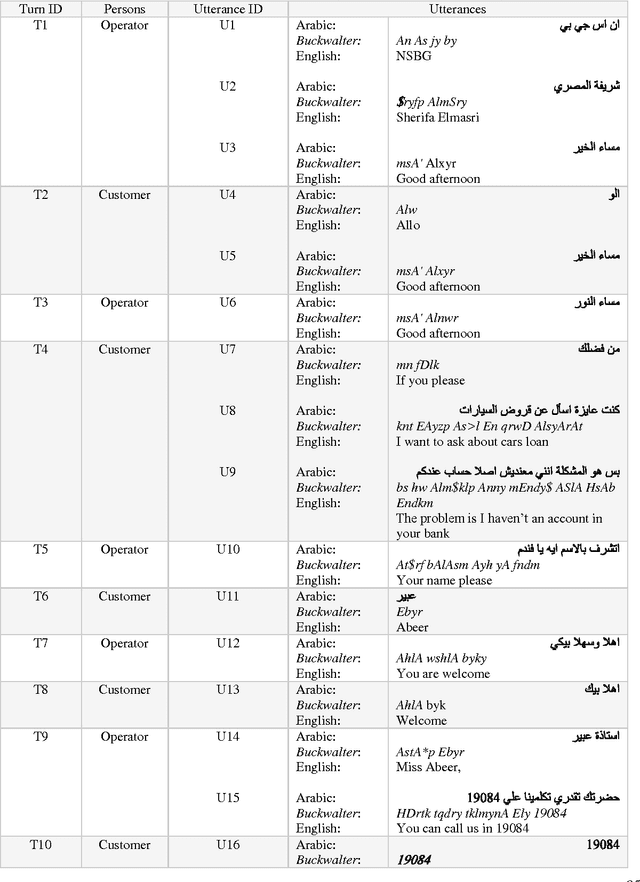
Turn Segmentation into Utterances for Arabic Spontaneous Dialogues and Instance Messages
May 12, 2015
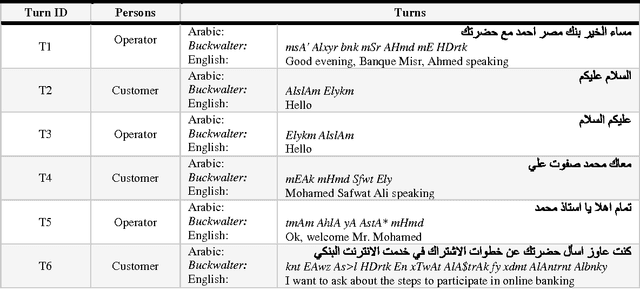
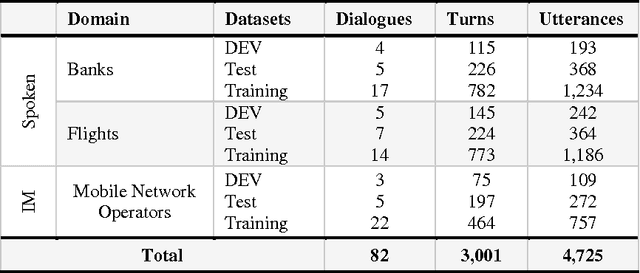
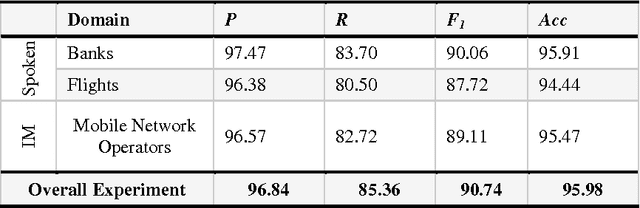
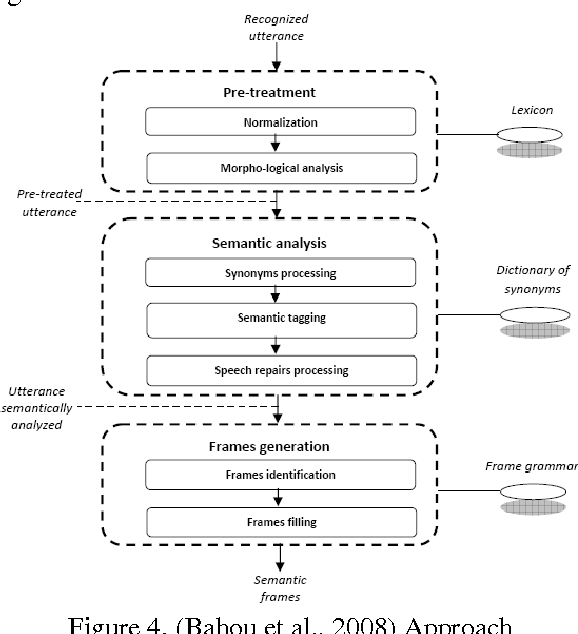
Text segmentation task is an essential processing task for many of Natural Language Processing (NLP) such as text summarization, text translation, dialogue language understanding, among others. Turns segmentation considered the key player in dialogue understanding task for building automatic Human-Computer systems. In this paper, we introduce a novel approach to turn segmentation into utterances for Egyptian spontaneous dialogues and Instance Messages (IM) using Machine Learning (ML) approach as a part of automatic understanding Egyptian spontaneous dialogues and IM task. Due to the lack of Egyptian dialect dialogue corpus the system evaluated by our corpus includes 3001 turns, which are collected, segmented, and annotated manually from Egyptian call-centers. The system achieves F1 scores of 90.74% and accuracy of 95.98%.