 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard negative examples are hard, but useful
Jul 24, 2020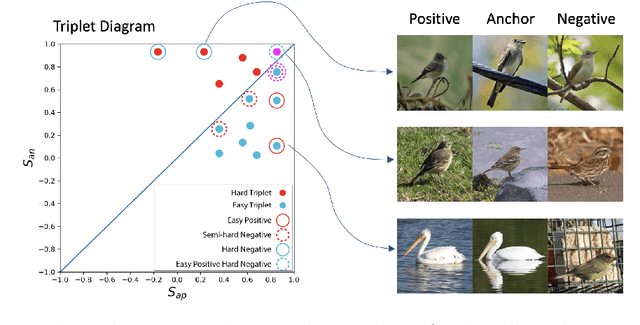

Triplet loss is an extremely common approach to distance metric learning. Representations of images from the same class are optimized to be mapped closer together in an embedding space than representations of images from different classes. Much work on triplet losses focuses on selecting the most useful triplets of images to consider, with strategies that select dissimilar examples from the same class or similar examples from different classes. The consensus of previous research is that optimizing with the \textit{hardest} negative examples leads to bad training behavior. That's a problem -- these hardest negatives are literally the cases where the distance metric fails to capture semantic similarity. In this paper, we characterize the space of triplets and derive why hard negatives make triplet loss training fail. We offer a simple fix to the loss function and show that, with this fix, optimizing with hard negative examples becomes feasible. This leads to more generalizable features, and image retrieval results that outperform state of the art for datasets with high intra-class variance.
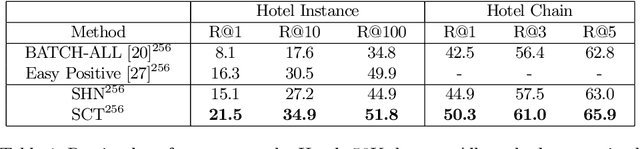
TraffickCam: Explainable Image Matching For Sex Trafficking Investigations
Oct 08, 2019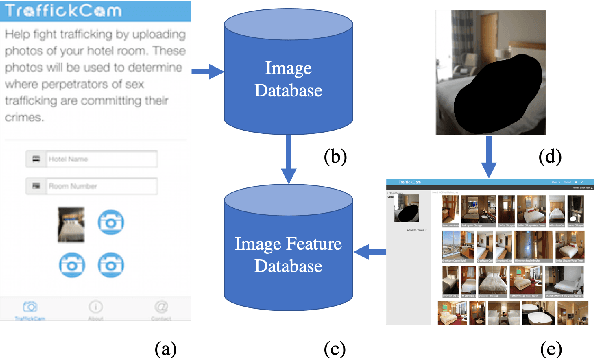
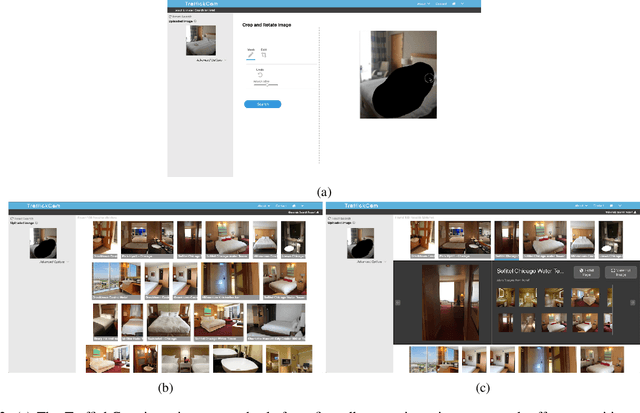

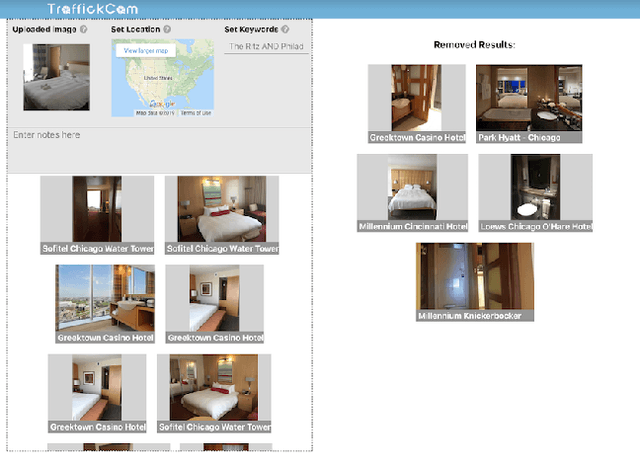
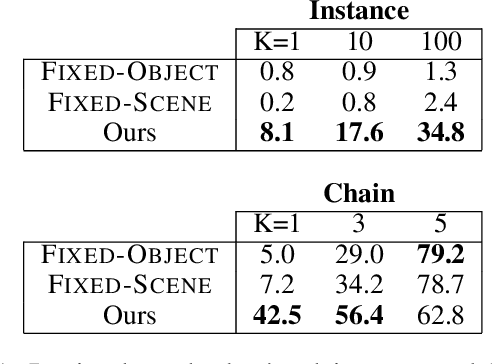
Investigations of sex trafficking sometimes have access to photographs of victims in hotel rooms. These images directly link victims to places, which can help verify where victims have been trafficked or where traffickers might operate in the future. Current machine learning approaches give promising results in image search to find the matching hotel. This paper explores approaches to make this end-to-end system better support government and law enforcement requirements, including improved performance, visualization approaches that explain what parts of the image led to a match, and infrastructure to support exporting the results of a query.
Visualizing How Embeddings Generalize
Sep 16, 2019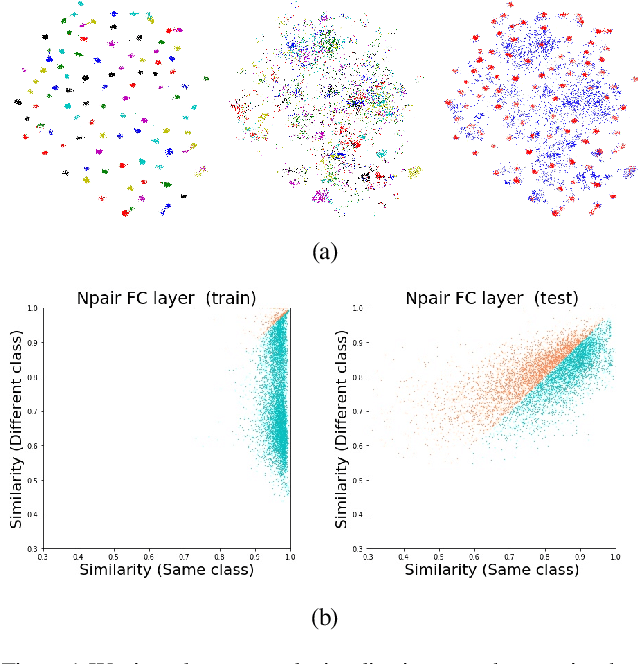
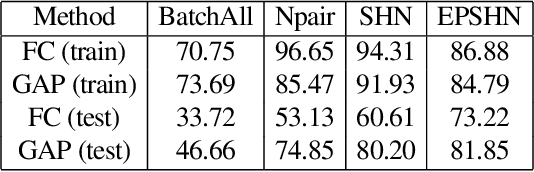
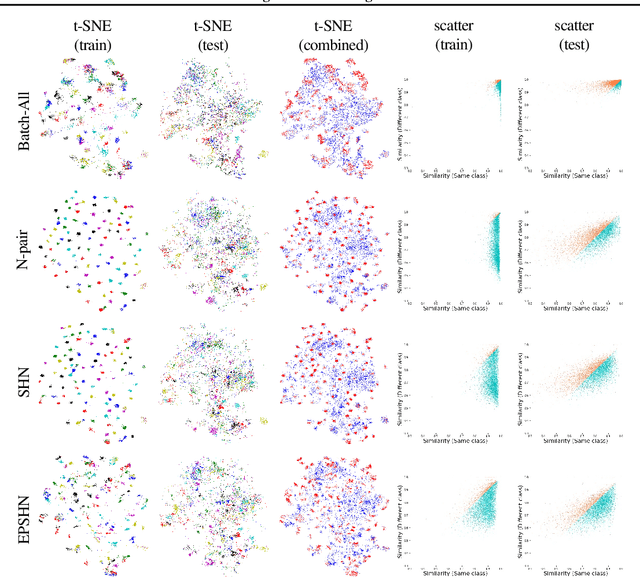
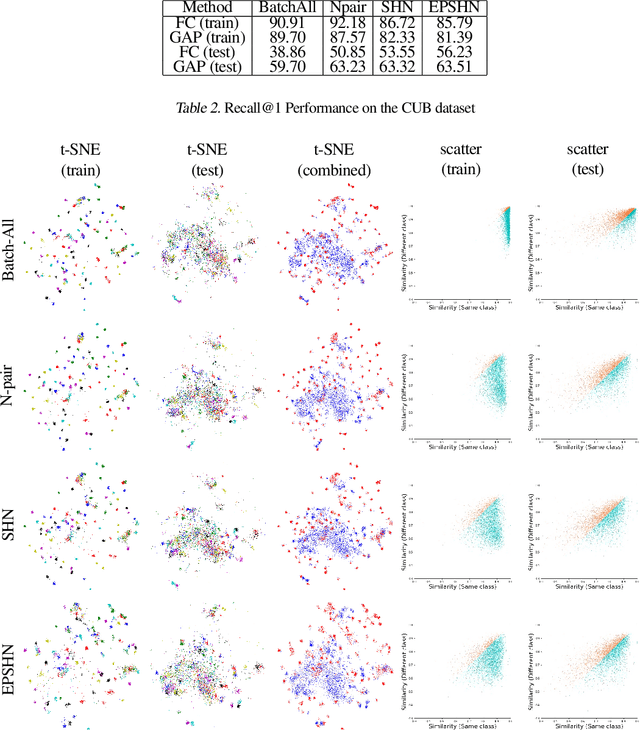
Deep metric learning is often used to learn an embedding function that captures the semantic differences within a dataset. A key factor in many problem domains is how this embedding generalizes to new classes of data. In observing many triplet selection strategies for Metric Learning, we find that the best performance consistently arises from approaches that focus on a few, well selected triplets.We introduce visualization tools to illustrate how an embedding generalizes beyond measuring accuracy on validation data, and we illustrate the behavior of a range of triplet selection strategies.
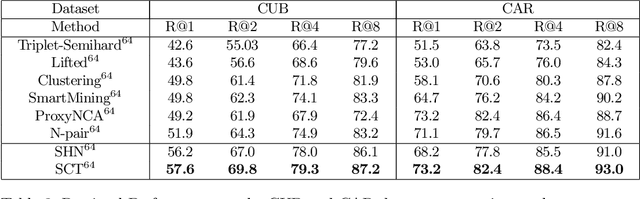
Improved Embeddings with Easy Positive Triplet Mining
Apr 08, 2019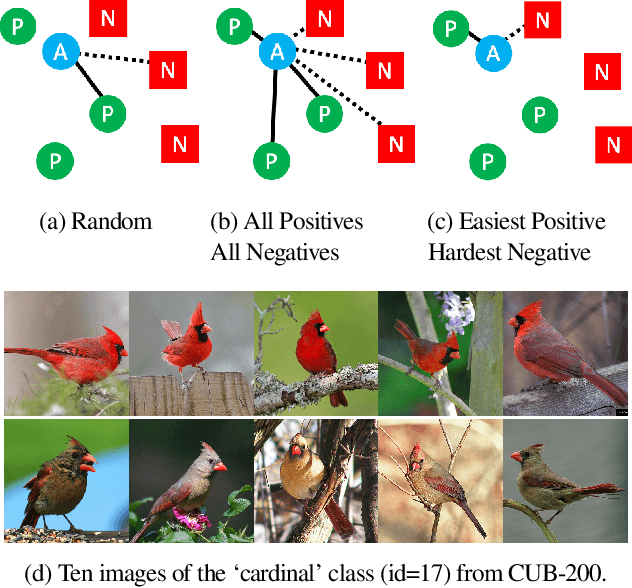
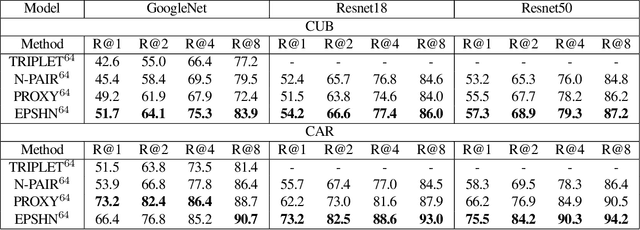
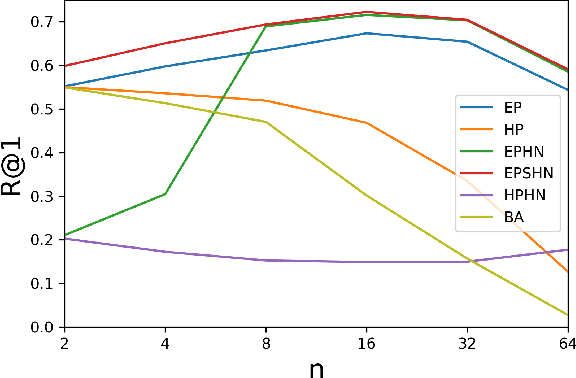
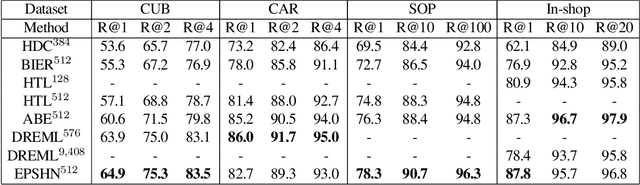
Deep metric learning seeks to define an embedding where semantically similar images are embedded to nearby locations, and semantically dissimilar images are embedded to distant locations. Substantial work has focused on loss functions and strategies to learn these embeddings by pushing images from the same class as close together in the embedding space as possible. In this paper, we propose an alternative, loosened embedding strategy that requires the embedding function only map each training image to the most similar examples from the same class, an approach we call "Easy Positive" mining. We provide a collection of experiments and visualizations that highlight that this Easy Positive mining leads to embeddings that are more flexible and generalize better to new unseen data. This simple mining strategy yields recall performance that exceeds state of the art approaches (including those with complicated loss functions and ensemble methods) on image retrieval datasets including CUB, Stanford Online Products, In-Shop Clothes and Hotels-50K.
Hotels-50K: A Global Hotel Recognition Dataset
Jan 26, 2019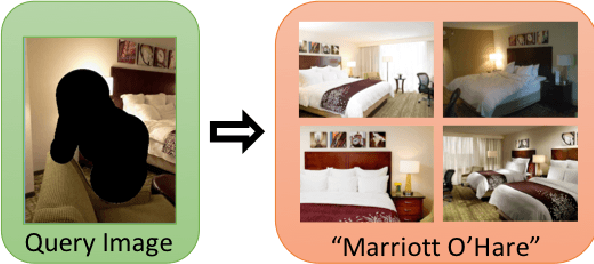


Recognizing a hotel from an image of a hotel room is important for human trafficking investigations. Images directly link victims to places and can help verify where victims have been trafficked, and where their traffickers might move them or others in the future. Recognizing the hotel from images is challenging because of low image quality, uncommon camera perspectives, large occlusions (often the victim), and the similarity of objects (e.g., furniture, art, bedding) across different hotel rooms. To support efforts towards this hotel recognition task, we have curated a dataset of over 1 million annotated hotel room images from 50,000 hotels. These images include professionally captured photographs from travel websites and crowd-sourced images from a mobile application, which are more similar to the types of images analyzed in real-world investigations. We present a baseline approach based on a standard network architecture and a collection of data-augmentation approaches tuned to this problem domain.
Visualizing Deep Similarity Networks
Jan 02, 2019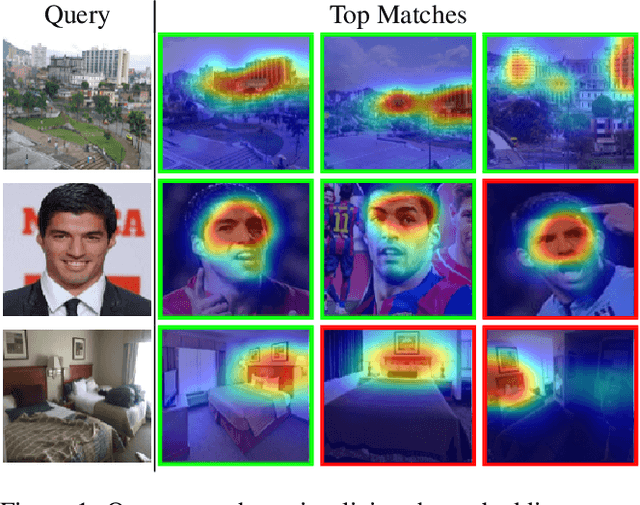
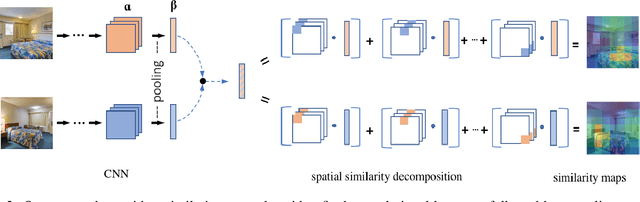
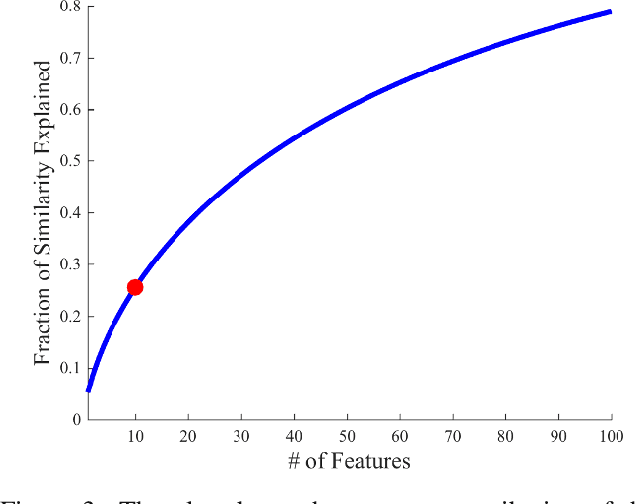

For convolutional neural network models that optimize an image embedding, we propose a method to highlight the regions of images that contribute most to pairwise similarity. This work is a corollary to the visualization tools developed for classification networks, but applicable to the problem domains better suited to similarity learning. The visualization shows how similarity networks that are fine-tuned learn to focus on different features. We also generalize our approach to embedding networks that use different pooling strategies and provide a simple mechanism to support image similarity searches on objects or sub-regions in the query image.