 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Block Nonlinear Neural Dynamical Models
Jan 06, 2021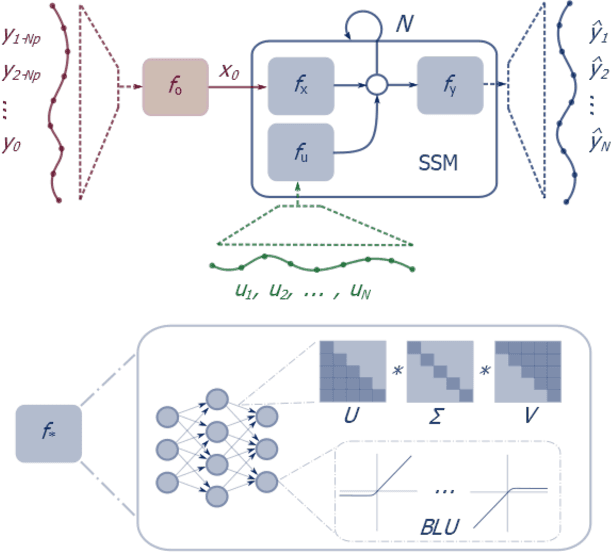
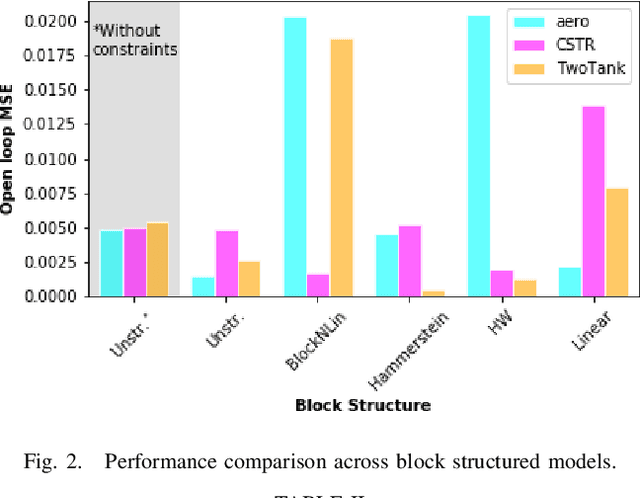
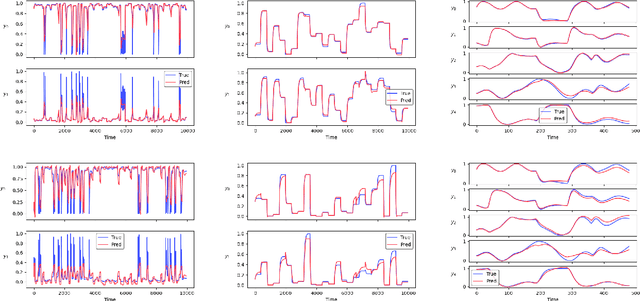
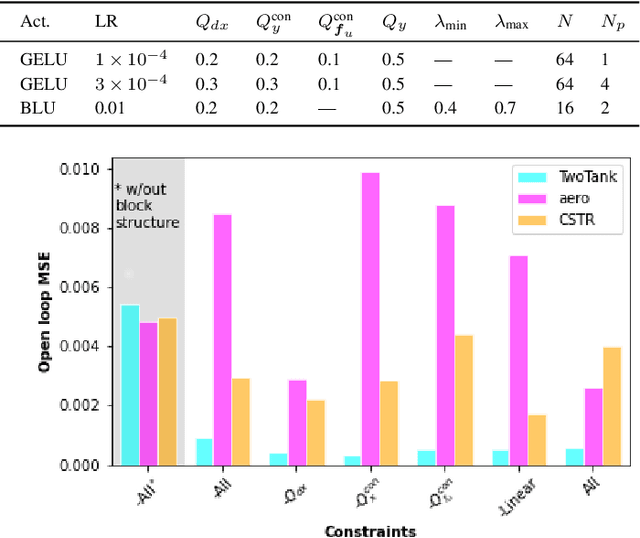
Neural network modules conditioned by known priors can be effectively trained and combined to represent systems with nonlinear dynamics. This work explores a novel formulation for data-efficient learning of deep control-oriented nonlinear dynamical models by embedding local model structure and constraints. The proposed method consists of neural network blocks that represent input, state, and output dynamics with constraints placed on the network weights and system variables. For handling partially observable dynamical systems, we utilize a state observer neural network to estimate the states of the system's latent dynamics. We evaluate the performance of the proposed architecture and training methods on system identification tasks for three nonlinear systems: a continuous stirred tank reactor, a two tank interacting system, and an aerodynamics body. Models optimized with a few thousand system state observations accurately represent system dynamics in open loop simulation over thousands of time steps from a single set of initial conditions. Experimental results demonstrate an order of magnitude reduction in open-loop simulation mean squared error for our constrained, block-structured neural models when compared to traditional unstructured and unconstrained neural network models.
Physics-Informed Neural State Space Models via Learning and Evolution
Nov 26, 2020
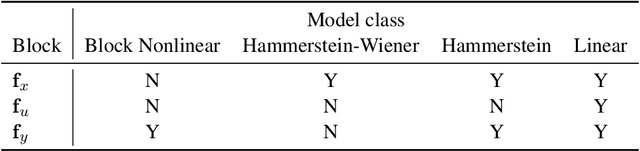

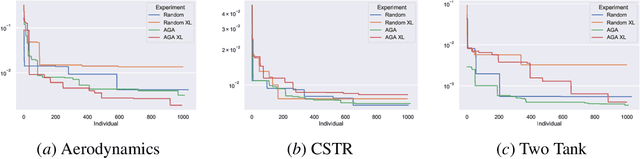
Recent works exploring deep learning application to dynamical systems modeling have demonstrated that embedding physical priors into neural networks can yield more effective, physically-realistic, and data-efficient models. However, in the absence of complete prior knowledge of a dynamical system's physical characteristics, determining the optimal structure and optimization strategy for these models can be difficult. In this work, we explore methods for discovering neural state space dynamics models for system identification. Starting with a design space of block-oriented state space models and structured linear maps with strong physical priors, we encode these components into a model genome alongside network structure, penalty constraints, and optimization hyperparameters. Demonstrating the overall utility of the design space, we employ an asynchronous genetic search algorithm that alternates between model selection and optimization and obtains accurate physically consistent models of three physical systems: an aerodynamics body, a continuous stirred tank reactor, and a two tank interacting system.
Spectral Analysis and Stability of Deep Neural Dynamics
Nov 26, 2020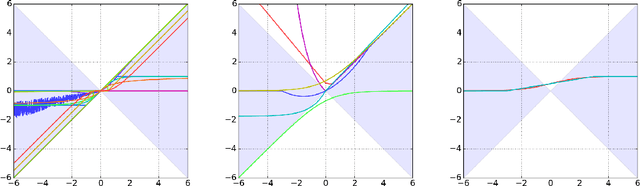
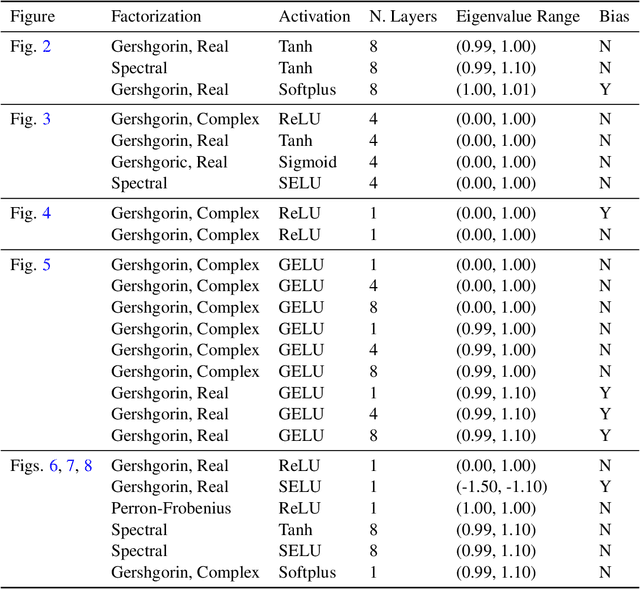
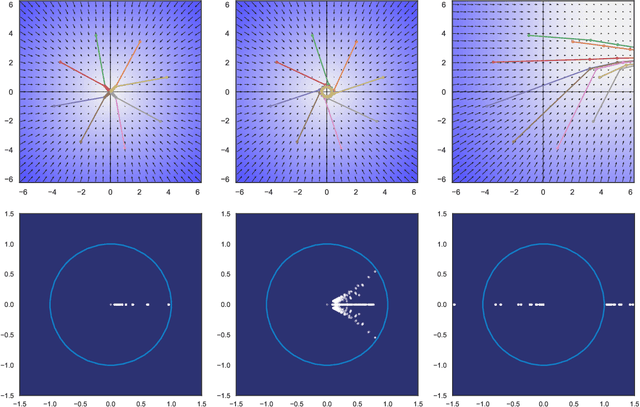
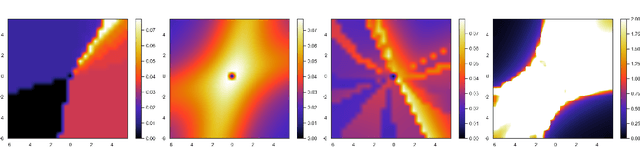
Our modern history of deep learning follows the arc of famous emergent disciplines in engineering (e.g. aero- and fluid dynamics) when theory lagged behind successful practical applications. Viewing neural networks from a dynamical systems perspective, in this work, we propose a novel characterization of deep neural networks as pointwise affine maps, making them accessible to a broader range of analysis methods to help close the gap between theory and practice. We begin by showing the equivalence of neural networks with parameter-varying affine maps parameterized by the state (feature) vector. As the paper's main results, we provide necessary and sufficient conditions for the global stability of generic deep feedforward neural networks. Further, we identify links between the spectral properties of layer-wise weight parametrizations, different activation functions, and their effect on the overall network's eigenvalue spectra. We analyze a range of neural networks with varying weight initializations, activation functions, bias terms, and depths. Our view of neural networks as affine parameter varying maps allows us to "crack open the black box" of global neural network dynamical behavior through visualization of stationary points, regions of attraction, state-space partitioning, eigenvalue spectra, and stability properties. Our analysis covers neural networks both as an end-to-end function and component-wise without simplifying assumptions or approximations. The methods we develop here provide tools to establish relationships between global neural dynamical properties and their constituent components which can aid in the principled design of neural networks for dynamics modeling and optimal control.
Fuzzy Simplicial Networks: A Topology-Inspired Model to Improve Task Generalization in Few-shot Learning
Sep 23, 2020


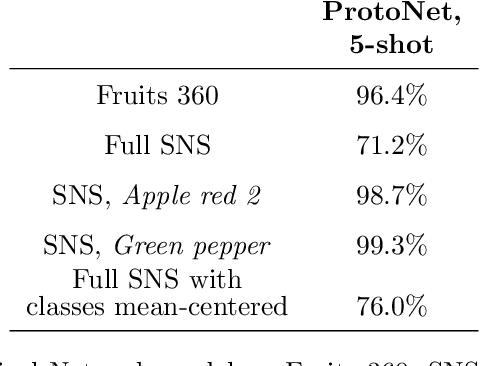
Deep learning has shown great success in settings with massive amounts of data but has struggled when data is limited. Few-shot learning algorithms, which seek to address this limitation, are designed to generalize well to new tasks with limited data. Typically, models are evaluated on unseen classes and datasets that are defined by the same fundamental task as they are trained for (e.g. category membership). One can also ask how well a model can generalize to fundamentally different tasks within a fixed dataset (for example: moving from category membership to tasks that involve detecting object orientation or quantity). To formalize this kind of shift we define a notion of "independence of tasks" and identify three new sets of labels for established computer vision datasets that test a model's ability to generalize to tasks which draw on orthogonal attributes in the data. We use these datasets to investigate the failure modes of metric-based few-shot models. Based on our findings, we introduce a new few-shot model called Fuzzy Simplicial Networks (FSN) which leverages a construction from topology to more flexibly represent each class from limited data. In particular, FSN models can not only form multiple representations for a given class but can also begin to capture the low-dimensional structure which characterizes class manifolds in the encoded space of deep networks. We show that FSN outperforms state-of-the-art models on the challenging tasks we introduce in this paper while remaining competitive on standard few-shot benchmarks.
Systematic Evaluation of Backdoor Data Poisoning Attacks on Image Classifiers
Apr 24, 2020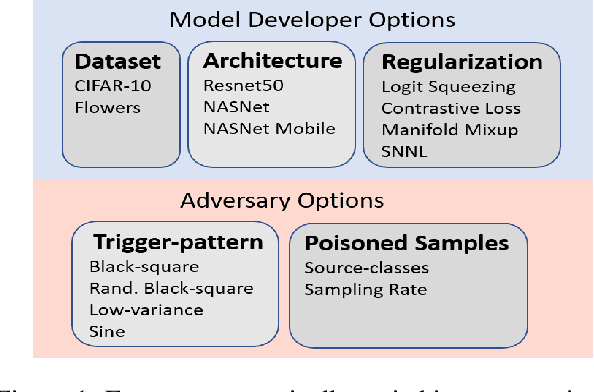
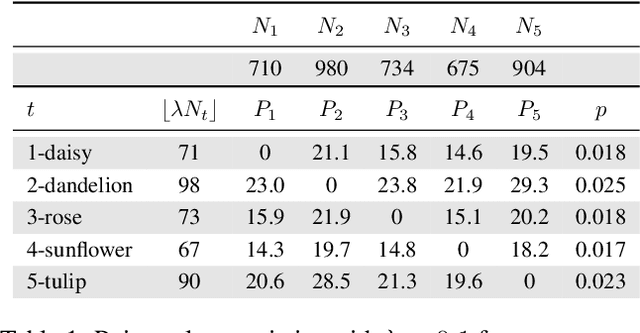


Backdoor data poisoning attacks have recently been demonstrated in computer vision research as a potential safety risk for machine learning (ML) systems. Traditional data poisoning attacks manipulate training data to induce unreliability of an ML model, whereas backdoor data poisoning attacks maintain system performance unless the ML model is presented with an input containing an embedded "trigger" that provides a predetermined response advantageous to the adversary. Our work builds upon prior backdoor data-poisoning research for ML image classifiers and systematically assesses different experimental conditions including types of trigger patterns, persistence of trigger patterns during retraining, poisoning strategies, architectures (ResNet-50, NasNet, NasNet-Mobile), datasets (Flowers, CIFAR-10), and potential defensive regularization techniques (Contrastive Loss, Logit Squeezing, Manifold Mixup, Soft-Nearest-Neighbors Loss). Experiments yield four key findings. First, the success rate of backdoor poisoning attacks varies widely, depending on several factors, including model architecture, trigger pattern and regularization technique. Second, we find that poisoned models are hard to detect through performance inspection alone. Third, regularization typically reduces backdoor success rate, although it can have no effect or even slightly increase it, depending on the form of regularization. Finally, backdoors inserted through data poisoning can be rendered ineffective after just a few epochs of additional training on a small set of clean data without affecting the model's performance.
Constrained Physics-Informed Deep Learning for Stable System Identification and Control of Unknown Linear Systems
Apr 24, 2020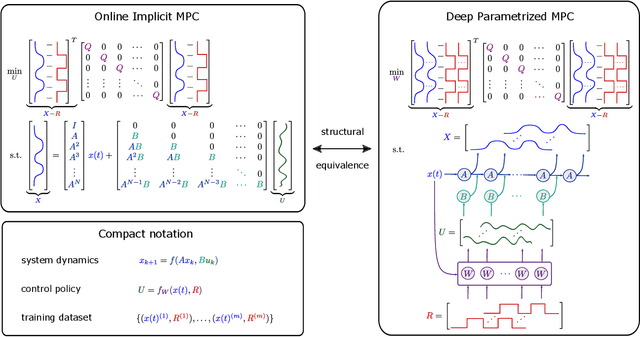
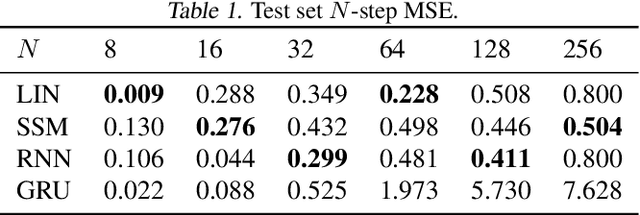
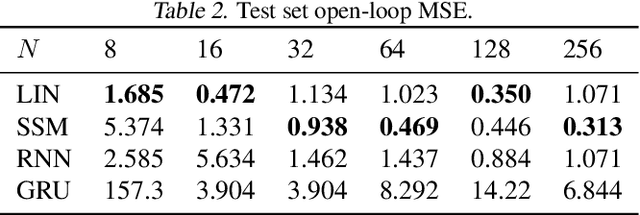
This paper presents a novel data-driven method for learning deep constrained continuous control policies and dynamical models of linear systems. By leveraging partial knowledge of system dynamics and constraint enforcing multi-objective loss functions, the method can learn from small and static datasets, handle time-varying state and input constraints and enforce the stability properties of the controlled system. We use a continuous control design example to demonstrate the performance of the method on three distinct tasks: system identification, control policy learning, and simultaneous system identification and policy learning. We assess the system identification performance by comparing open-loop simulations of the true system and the learned models. We demonstrate the performance of the policy learning methodology in closed-loop simulations using the system model affected by varying levels of parametric and additive uncertainties. We report superior performance in terms of reference tracking, robustness, and online computational and memory footprints compared with classical control approaches, namely LQR and LQI controllers, and with three variants of model predictive control (MPC) formulations and two traditional MPC solution approaches. We then evaluate the potential of simultaneously learning the system model and control policy. Our empirical results demonstrate the effectiveness of our unifying framework for constrained optimal control of linear systems to provide stability guarantees of the learned dynamics, robustness to uncertainty, and high sampling efficiency.
Constrained Neural Ordinary Differential Equations with Stability Guarantees
Apr 22, 2020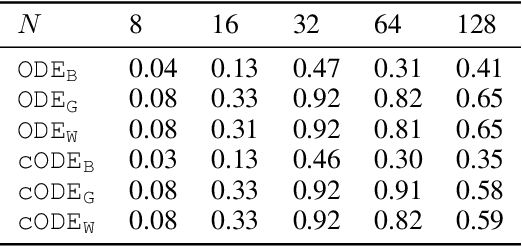
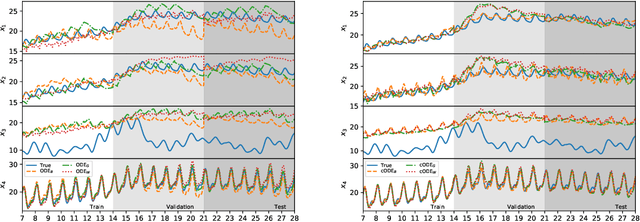
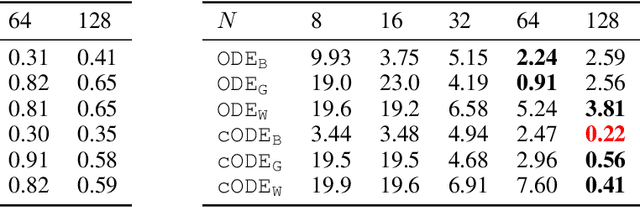
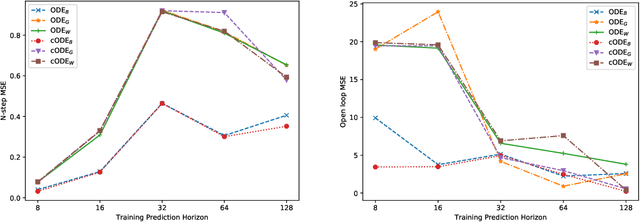
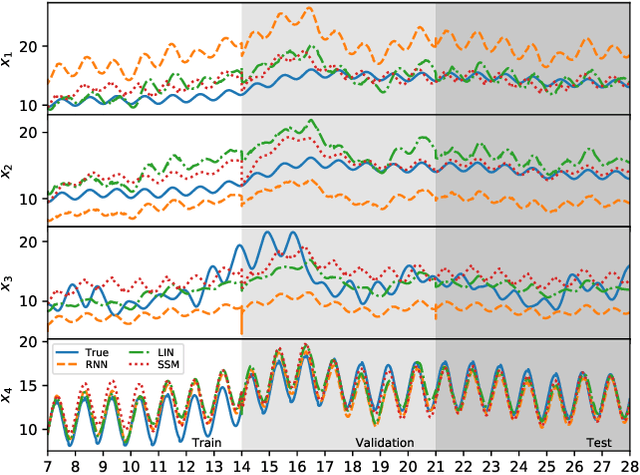
Differential equations are frequently used in engineering domains, such as modeling and control of industrial systems, where safety and performance guarantees are of paramount importance. Traditional physics-based modeling approaches require domain expertise and are often difficult to tune or adapt to new systems. In this paper, we show how to model discrete ordinary differential equations (ODE) with algebraic nonlinearities as deep neural networks with varying degrees of prior knowledge. We derive the stability guarantees of the network layers based on the implicit constraints imposed on the weight's eigenvalues. Moreover, we show how to use barrier methods to generically handle additional inequality constraints. We demonstrate the prediction accuracy of learned neural ODEs evaluated on open-loop simulations compared to ground truth dynamics with bi-linear terms.
Multiple Document Representations from News Alerts for Automated Bio-surveillance Event Detection
Feb 17, 2019
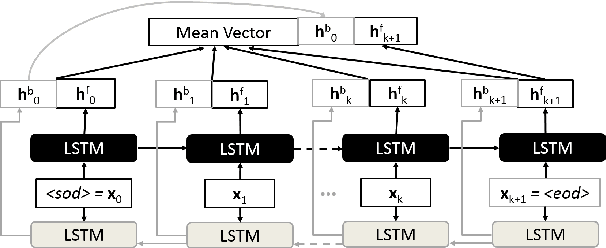
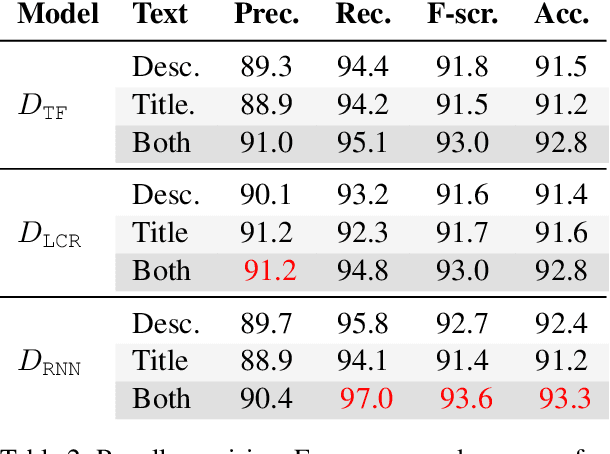
Due to globalization, geographic boundaries no longer serve as effective shields for the spread of infectious diseases. In order to aid bio-surveillance analysts in disease tracking, recent research has been devoted to developing information retrieval and analysis methods utilizing the vast corpora of publicly available documents on the internet. In this work, we present methods for the automated retrieval and classification of documents related to active public health events. We demonstrate classification performance on an auto-generated corpus, using recurrent neural network, TF-IDF, and Naive Bayes log count ratio document representations. By jointly modeling the title and description of a document, we achieve 97% recall and 93.3% accuracy with our best performing bio-surveillance event classification model: logistic regression on the combined output from a pair of bidirectional recurrent neural networks.
Recurrent Neural Network Attention Mechanisms for Interpretable System Log Anomaly Detection
Mar 13, 2018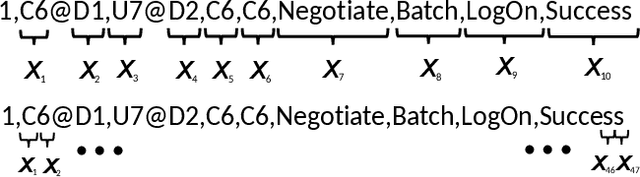
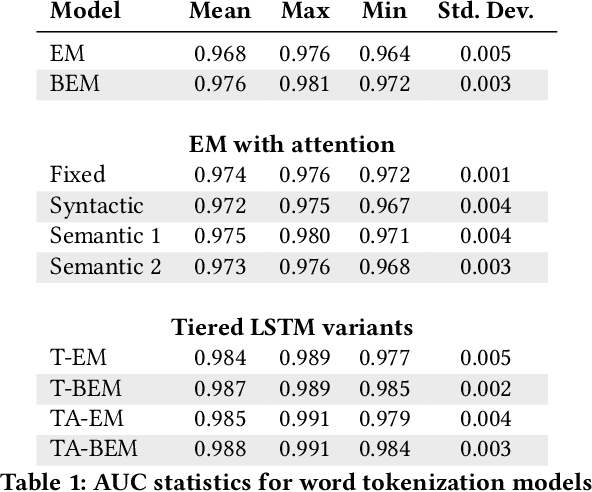
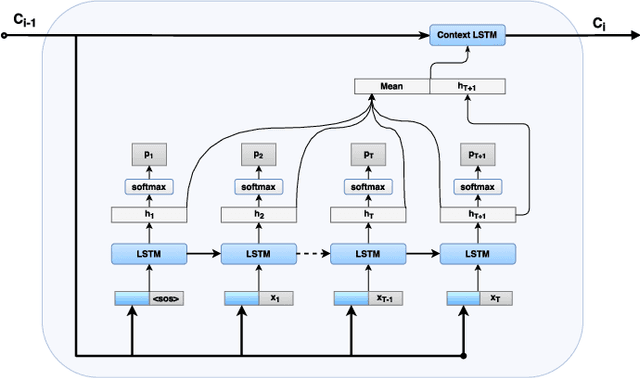
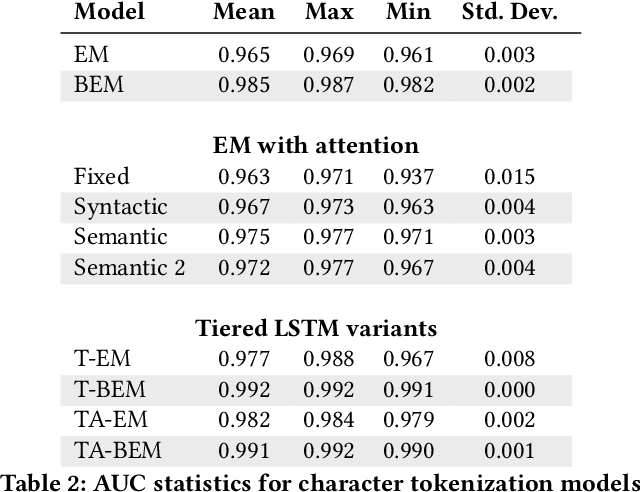
Deep learning has recently demonstrated state-of-the art performance on key tasks related to the maintenance of computer systems, such as intrusion detection, denial of service attack detection, hardware and software system failures, and malware detection. In these contexts, model interpretability is vital for administrator and analyst to trust and act on the automated analysis of machine learning models. Deep learning methods have been criticized as black box oracles which allow limited insight into decision factors. In this work we seek to "bridge the gap" between the impressive performance of deep learning models and the need for interpretable model introspection. To this end we present recurrent neural network (RNN) language models augmented with attention for anomaly detection in system logs. Our methods are generally applicable to any computer system and logging source. By incorporating attention variants into our RNN language models we create opportunities for model introspection and analysis without sacrificing state-of-the art performance. We demonstrate model performance and illustrate model interpretability on an intrusion detection task using the Los Alamos National Laboratory (LANL) cyber security dataset, reporting upward of 0.99 area under the receiver operator characteristic curve despite being trained only on a single day's worth of data.
Deep Learning for Unsupervised Insider Threat Detection in Structured Cybersecurity Data Streams
Dec 15, 2017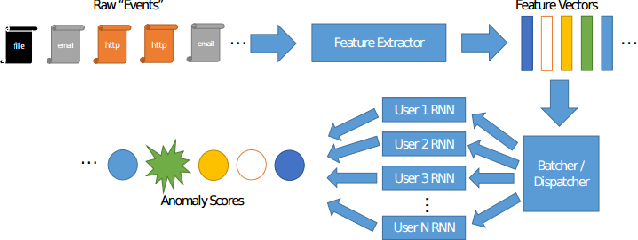

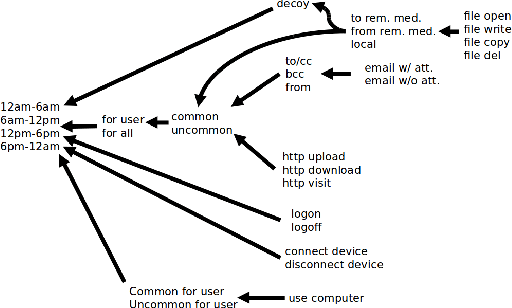
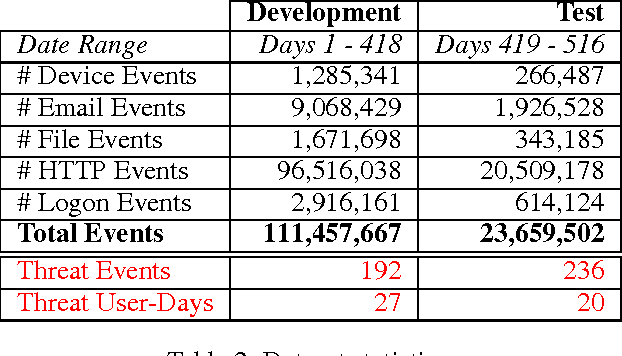
Analysis of an organization's computer network activity is a key component of early detection and mitigation of insider threat, a growing concern for many organizations. Raw system logs are a prototypical example of streaming data that can quickly scale beyond the cognitive power of a human analyst. As a prospective filter for the human analyst, we present an online unsupervised deep learning approach to detect anomalous network activity from system logs in real time. Our models decompose anomaly scores into the contributions of individual user behavior features for increased interpretability to aid analysts reviewing potential cases of insider threat. Using the CERT Insider Threat Dataset v6.2 and threat detection recall as our performance metric, our novel deep and recurrent neural network models outperform Principal Component Analysis, Support Vector Machine and Isolation Forest based anomaly detection baselines. For our best model, the events labeled as insider threat activity in our dataset had an average anomaly score in the 95.53 percentile, demonstrating our approach's potential to greatly reduce analyst workloads.