 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Neural Networks Learn Small Algebraic Worlds? An Investigation Into the Group-theoretic Structures Learned By Narrow Models Trained To Predict Group Operations
Jan 29, 2026While a real-world research program in mathematics may be guided by a motivating question, the process of mathematical discovery is typically open-ended. Ideally, exploration needed to answer the original question will reveal new structures, patterns, and insights that are valuable in their own right. This contrasts with the exam-style paradigm in which the machine learning community typically applies AI to math. To maximize progress in mathematics using AI, we will need to go beyond simple question answering. With this in mind, we explore the extent to which narrow models trained to solve a fixed mathematical task learn broader mathematical structure that can be extracted by a researcher or other AI system. As a basic test case for this, we use the task of training a neural network to predict a group operation (for example, performing modular arithmetic or composition of permutations). We describe a suite of tests designed to assess whether the model captures significant group-theoretic notions such as the identity element, commutativity, or subgroups. Through extensive experimentation we find evidence that models learn representations capable of capturing abstract algebraic properties. For example, we find hints that models capture the commutativity of modular arithmetic. We are also able to train linear classifiers that reliably distinguish between elements of certain subgroups (even though no labels for these subgroups are included in the data). On the other hand, we are unable to extract notions such as the concept of the identity element. Together, our results suggest that in some cases the representations of even small neural networks can be used to distill interesting abstract structure from new mathematical objects.
Systematic Evaluation of Backdoor Data Poisoning Attacks on Image Classifiers
Apr 24, 2020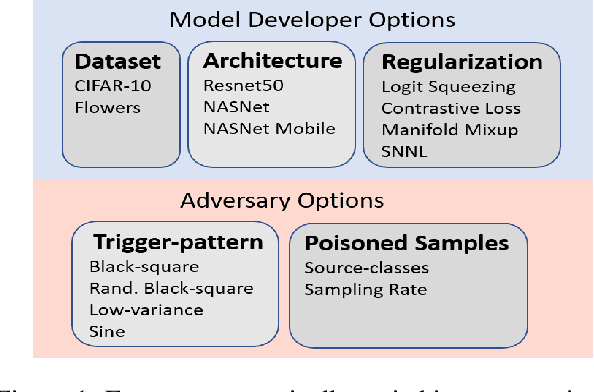
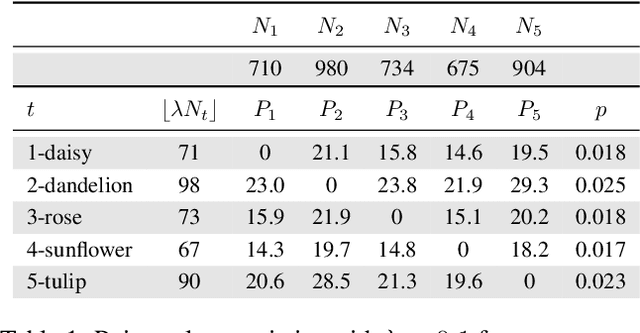


Backdoor data poisoning attacks have recently been demonstrated in computer vision research as a potential safety risk for machine learning (ML) systems. Traditional data poisoning attacks manipulate training data to induce unreliability of an ML model, whereas backdoor data poisoning attacks maintain system performance unless the ML model is presented with an input containing an embedded "trigger" that provides a predetermined response advantageous to the adversary. Our work builds upon prior backdoor data-poisoning research for ML image classifiers and systematically assesses different experimental conditions including types of trigger patterns, persistence of trigger patterns during retraining, poisoning strategies, architectures (ResNet-50, NasNet, NasNet-Mobile), datasets (Flowers, CIFAR-10), and potential defensive regularization techniques (Contrastive Loss, Logit Squeezing, Manifold Mixup, Soft-Nearest-Neighbors Loss). Experiments yield four key findings. First, the success rate of backdoor poisoning attacks varies widely, depending on several factors, including model architecture, trigger pattern and regularization technique. Second, we find that poisoned models are hard to detect through performance inspection alone. Third, regularization typically reduces backdoor success rate, although it can have no effect or even slightly increase it, depending on the form of regularization. Finally, backdoors inserted through data poisoning can be rendered ineffective after just a few epochs of additional training on a small set of clean data without affecting the model's performance.
Projecting Trouble: Light Based Adversarial Attacks on Deep Learning Classifiers
Oct 16, 2018
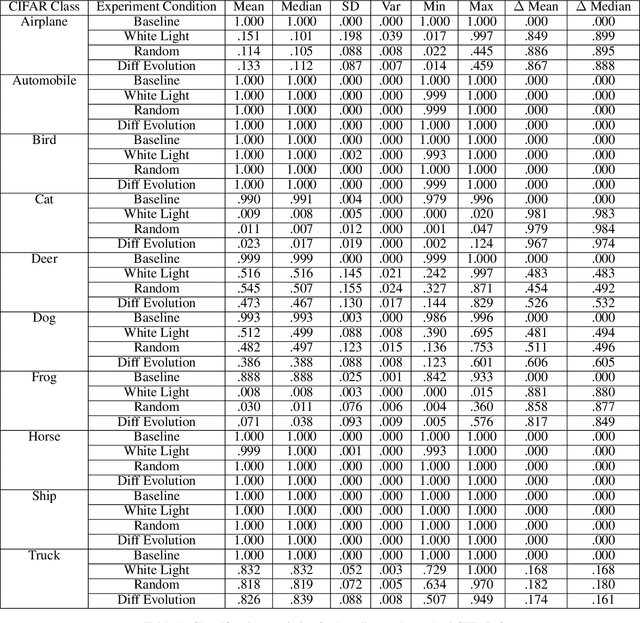


This work demonstrates a physical attack on a deep learning image classification system using projected light onto a physical scene. Prior work is dominated by techniques for creating adversarial examples which directly manipulate the digital input of the classifier. Such an attack is limited to scenarios where the adversary can directly update the inputs to the classifier. This could happen by intercepting and modifying the inputs to an online API such as Clarifai or Cloud Vision. Such limitations have led to a vein of research around physical attacks where objects are constructed to be inherently adversarial or adversarial modifications are added to cause misclassification. Our work differs from other physical attacks in that we can cause misclassification dynamically without altering physical objects in a permanent way. We construct an experimental setup which includes a light projection source, an object for classification, and a camera to capture the scene. Experiments are conducted against 2D and 3D objects from CIFAR-10. Initial tests show projected light patterns selected via differential evolution could degrade classification from 98% to 22% and 89% to 43% probability for 2D and 3D targets respectively. Subsequent experiments explore sensitivity to physical setup and compare two additional baseline conditions for all 10 CIFAR classes. Some physical targets are more susceptible to perturbation. Simple attacks show near equivalent success, and 6 of the 10 classes were disrupted by light.
Faster Fuzzing: Reinitialization with Deep Neural Models
Nov 08, 2017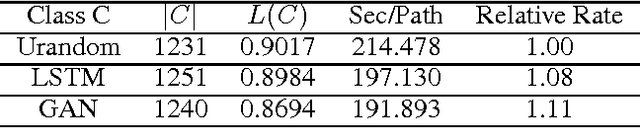
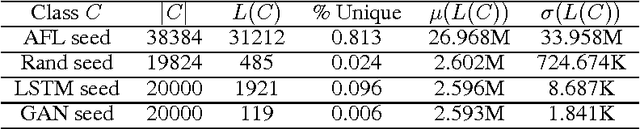

We improve the performance of the American Fuzzy Lop (AFL) fuzz testing framework by using Generative Adversarial Network (GAN) models to reinitialize the system with novel seed files. We assess performance based on the temporal rate at which we produce novel and unseen code paths. We compare this approach to seed file generation from a random draw of bytes observed in the training seed files. The code path lengths and variations were not sufficiently diverse to fully replace AFL input generation. However, augmenting native AFL with these additional code paths demonstrated improvements over AFL alone. Specifically, experiments showed the GAN was faster and more effective than the LSTM and out-performed a random augmentation strategy, as measured by the number of unique code paths discovered. GAN helps AFL discover 14.23% more code paths than the random strategy in the same amount of CPU time, finds 6.16% more unique code paths, and finds paths that are on average 13.84% longer. Using GAN shows promise as a reinitialization strategy for AFL to help the fuzzer exercise deep paths in software.