 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Conditional VRNNs for Video Prediction
Apr 27, 2019
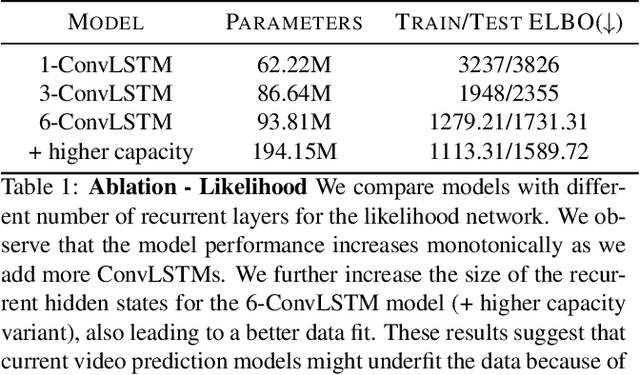
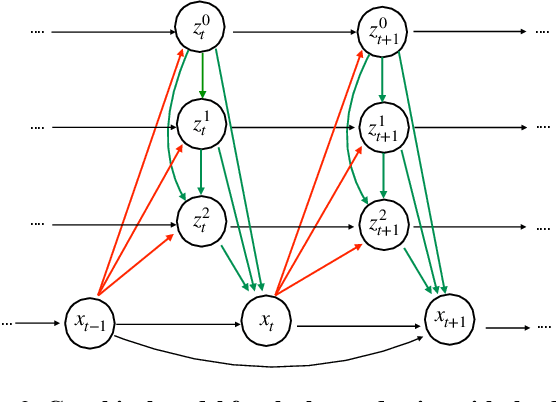
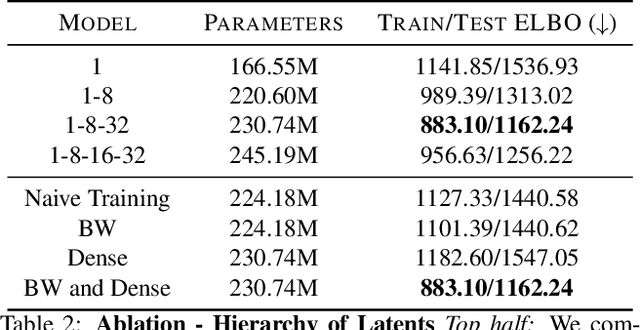
Predicting future frames for a video sequence is a challenging generative modeling task. Promising approaches include probabilistic latent variable models such as the Variational Auto-Encoder. While VAEs can handle uncertainty and model multiple possible future outcomes, they have a tendency to produce blurry predictions. In this work we argue that this is a sign of underfitting. To address this issue, we propose to increase the expressiveness of the latent distributions and to use higher capacity likelihood models. Our approach relies on a hierarchy of latent variables, which defines a family of flexible prior and posterior distributions in order to better model the probability of future sequences. We validate our proposal through a series of ablation experiments and compare our approach to current state-of-the-art latent variable models. Our method performs favorably under several metrics in three different datasets.
Counterpoint by Convolution
Mar 18, 2019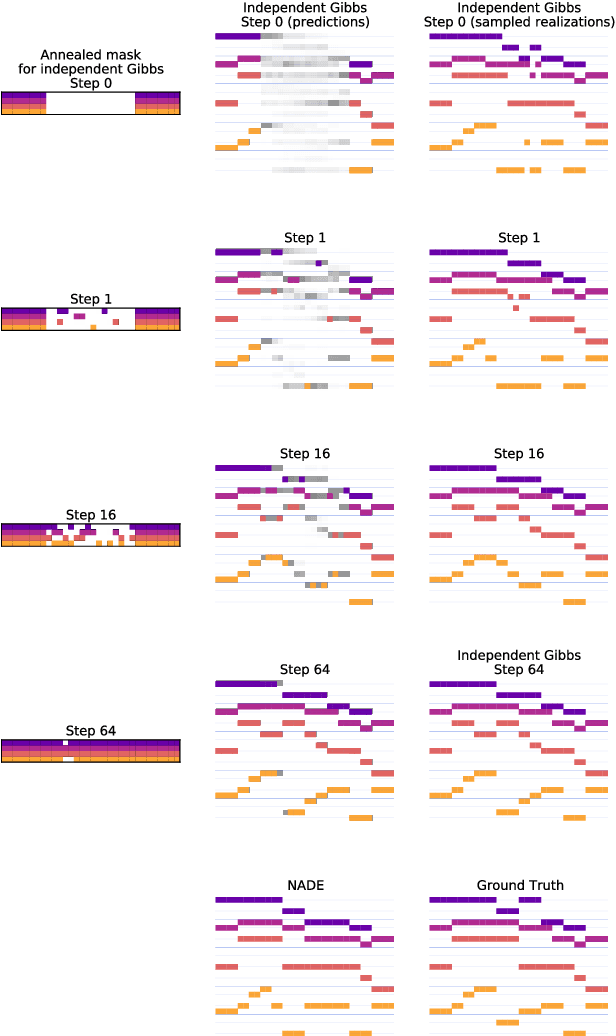
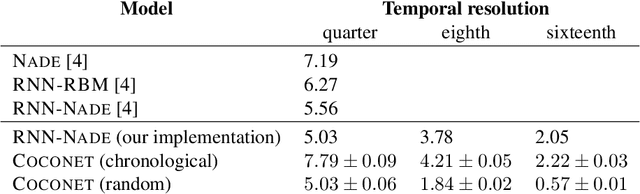
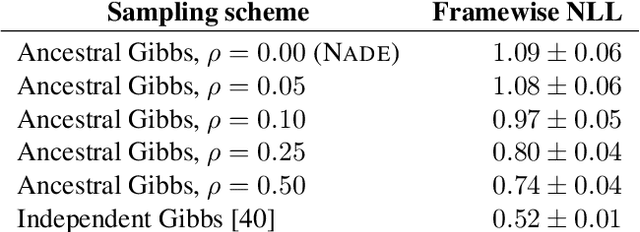
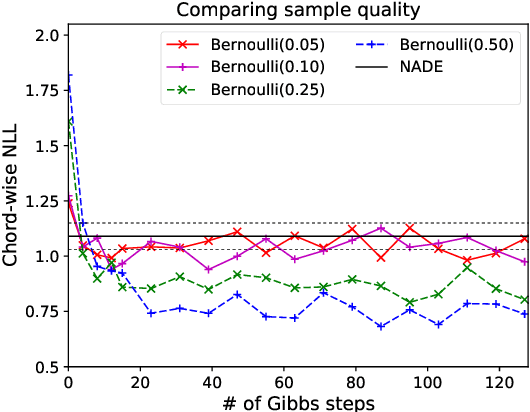
Machine learning models of music typically break up the task of composition into a chronological process, composing a piece of music in a single pass from beginning to end. On the contrary, human composers write music in a nonlinear fashion, scribbling motifs here and there, often revisiting choices previously made. In order to better approximate this process, we train a convolutional neural network to complete partial musical scores, and explore the use of blocked Gibbs sampling as an analogue to rewriting. Neither the model nor the generative procedure are tied to a particular causal direction of composition. Our model is an instance of orderless NADE (Uria et al., 2014), which allows more direct ancestral sampling. However, we find that Gibbs sampling greatly improves sample quality, which we demonstrate to be due to some conditional distributions being poorly modeled. Moreover, we show that even the cheap approximate blocked Gibbs procedure from Yao et al. (2014) yields better samples than ancestral sampling, based on both log-likelihood and human evaluation.
Maximum Entropy Generators for Energy-Based Models
Jan 24, 2019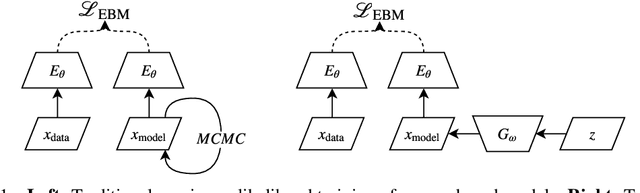
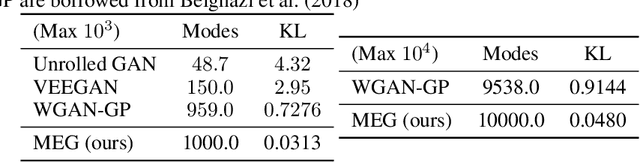
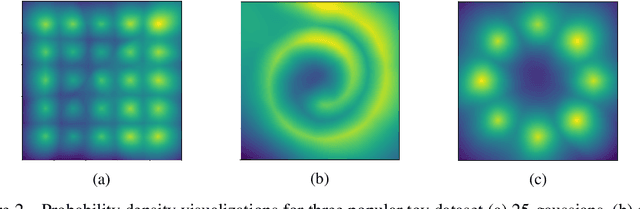
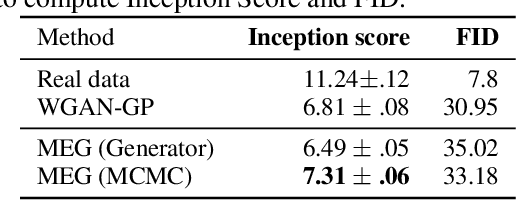
Unsupervised learning is about capturing dependencies between variables and is driven by the contrast between the probable vs. improbable configurations of these variables, often either via a generative model that only samples probable ones or with an energy function (unnormalized log-density) that is low for probable ones and high for improbable ones. Here, we consider learning both an energy function and an efficient approximate sampling mechanism. Whereas the discriminator in generative adversarial networks (GANs) learns to separate data and generator samples, introducing an entropy maximization regularizer on the generator can turn the interpretation of the critic into an energy function, which separates the training distribution from everything else, and thus can be used for tasks like anomaly or novelty detection. Then, we show how Markov Chain Monte Carlo can be done in the generator latent space whose samples can be mapped to data space, producing better samples. These samples are used for the negative phase gradient required to estimate the log-likelihood gradient of the data space energy function. To maximize entropy at the output of the generator, we take advantage of recently introduced neural estimators of mutual information. We find that in addition to producing a useful scoring function for anomaly detection, the resulting approach produces sharp samples while covering the modes well, leading to high Inception and Frechet scores.
Deep Generative Modeling of LiDAR Data
Dec 17, 2018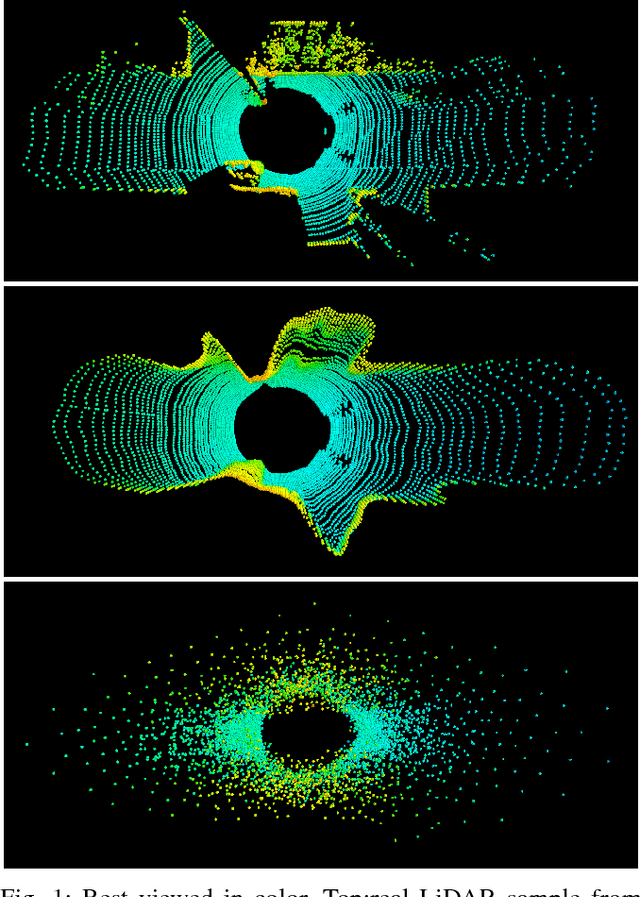

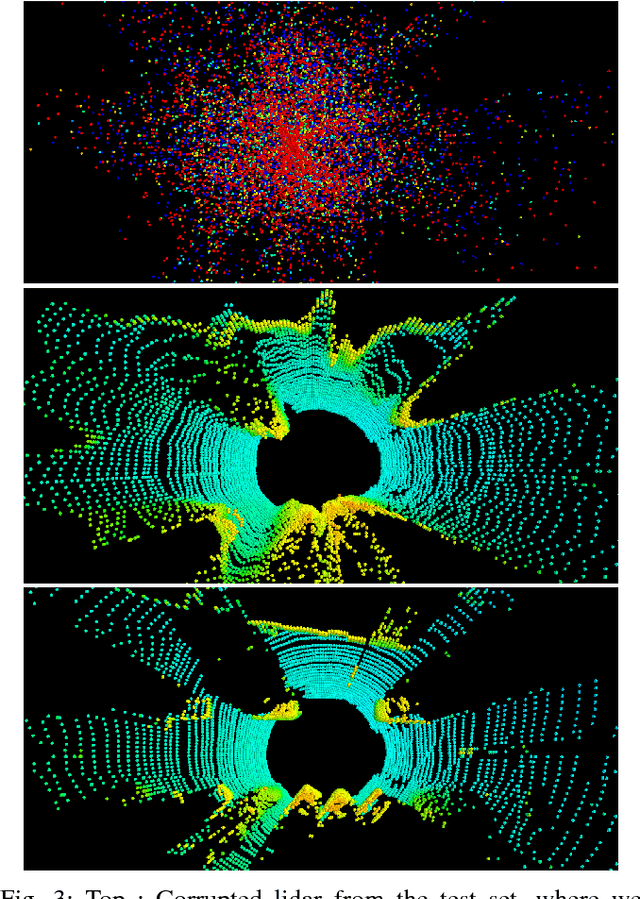
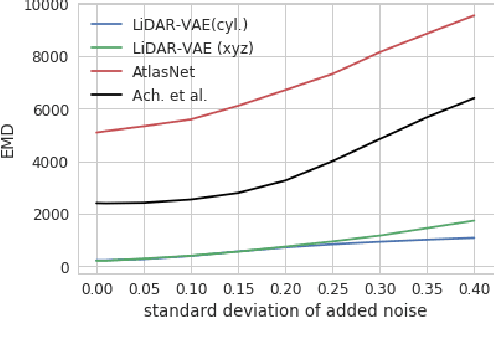
Building models capable of generating structured output is a key challenge for AI and robotics. While generative models have been explored on many types of data, little work has been done on synthesizing lidar scans, which play a key role in robot mapping and localization. In this work, we show that one can adapt deep generative models for this task by unravelling lidar scans into a multi-channel 2D signal. Our approach can generate high quality samples, while simultaneously learning a meaningful latent representation of the data. Furthermore, we demonstrate that our method is robust to noisy input - the learned model can recover the underlying lidar scan from seemingly uninformative data.
Systematic Generalization: What Is Required and Can It Be Learned?
Nov 30, 2018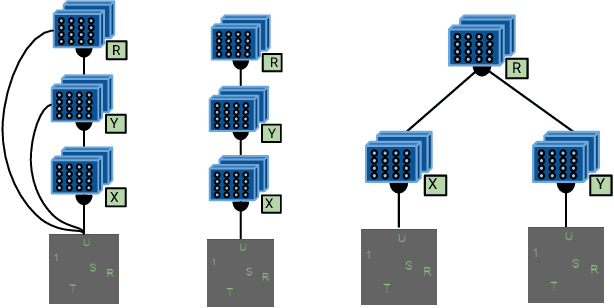
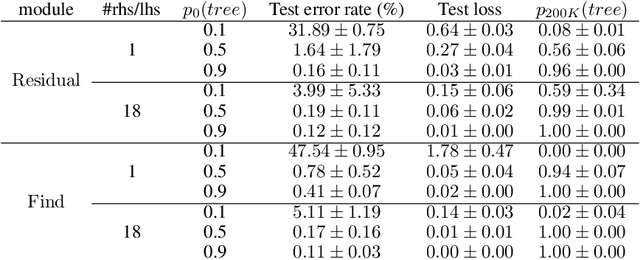

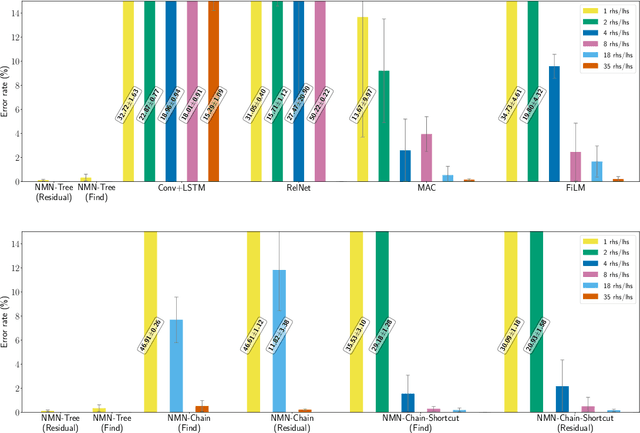
Numerous models for grounded language understanding have been recently proposed, including (i) generic models that can be easily adapted to any given task with little adaptation and (ii) intuitively appealing modular models that require background knowledge to be instantiated. We compare both types of models in how much they lend themselves to a particular form of systematic generalization. Using a synthetic VQA test, we evaluate which models are capable of reasoning about all possible object pairs after training on only a small subset of them. Our findings show that the generalization of modular models is much more systematic and that it is highly sensitive to the module layout, i.e. to how exactly the modules are connected. We furthermore investigate if modular models that generalize well could be made more end-to-end by learning their layout and parametrization. We find that end-to-end methods from prior work often learn a wrong layout and a spurious parametrization that do not facilitate systematic generalization. Our results suggest that, in addition to modularity, systematic generalization in language understanding may require explicit regularizers or priors.
Planning in Dynamic Environments with Conditional Autoregressive Models
Nov 25, 2018

We demonstrate the use of conditional autoregressive generative models (van den Oord et al., 2016a) over a discrete latent space (van den Oord et al., 2017b) for forward planning with MCTS. In order to test this method, we introduce a new environment featuring varying difficulty levels, along with moving goals and obstacles. The combination of high-quality frame generation and classical planning approaches nearly matches true environment performance for our task, demonstrating the usefulness of this method for model-based planning in dynamic environments.
Representation Mixing for TTS Synthesis
Nov 24, 2018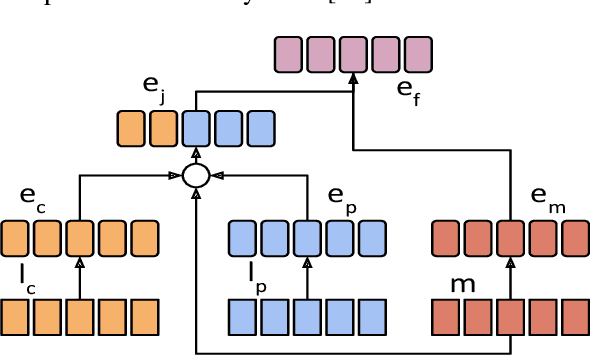
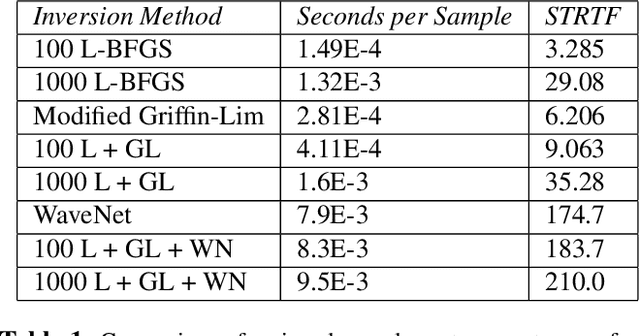
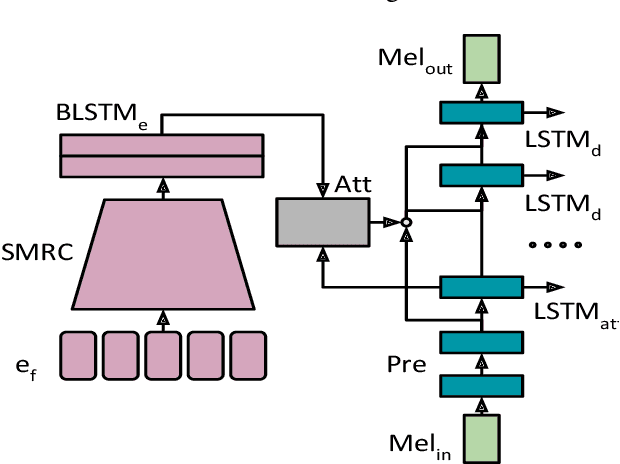

Recent character and phoneme-based parametric TTS systems using deep learning have shown strong performance in natural speech generation. However, the choice between character or phoneme input can create serious limitations for practical deployment, as direct control of pronunciation is crucial in certain cases. We demonstrate a simple method for combining multiple types of linguistic information in a single encoder, named representation mixing, enabling flexible choice between character, phoneme, or mixed representations during inference. Experiments and user studies on a public audiobook corpus show the efficacy of our approach.
Harmonic Recomposition using Conditional Autoregressive Modeling
Nov 18, 2018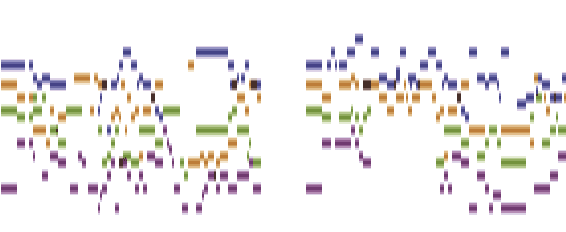
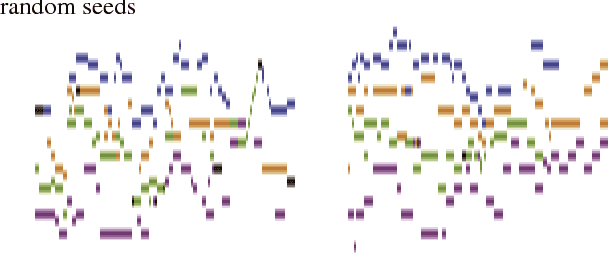
We demonstrate a conditional autoregressive pipeline for efficient music recomposition, based on methods presented in van den Oord et al.(2017). Recomposition (Casal & Casey, 2010) focuses on reworking existing musical pieces, adhering to structure at a high level while also re-imagining other aspects of the work. This can involve reuse of pre-existing themes or parts of the original piece, while also requiring the flexibility to generate new content at different levels of granularity. Applying the aforementioned modeling pipeline to recomposition, we show diverse and structured generation conditioned on chord sequence annotations.
Blindfold Baselines for Embodied QA
Nov 12, 2018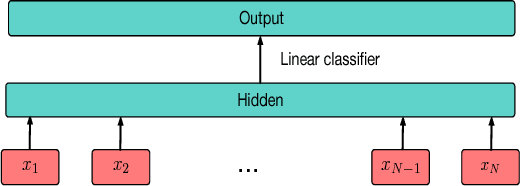
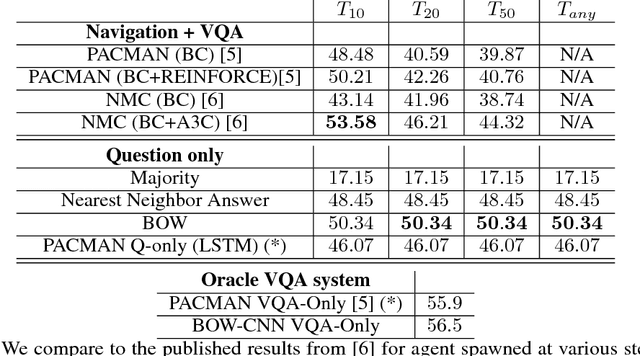
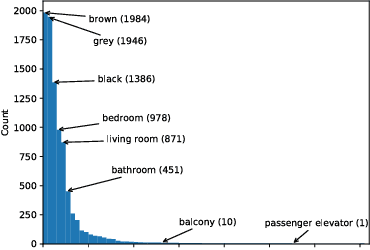
We explore blindfold (question-only) baselines for Embodied Question Answering. The EmbodiedQA task requires an agent to answer a question by intelligently navigating in a simulated environment, gathering necessary visual information only through first-person vision before finally answering. Consequently, a blindfold baseline which ignores the environment and visual information is a degenerate solution, yet we show through our experiments on the EQAv1 dataset that a simple question-only baseline achieves state-of-the-art results on the EmbodiedQA task in all cases except when the agent is spawned extremely close to the object.
Improving Explorability in Variational Inference with Annealed Variational Objectives
Oct 26, 2018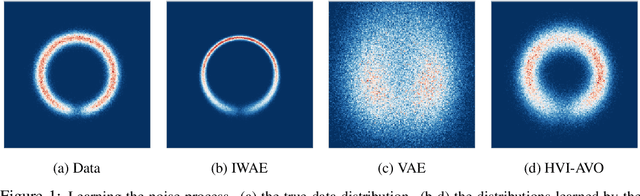
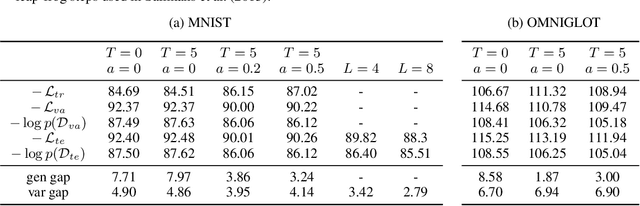
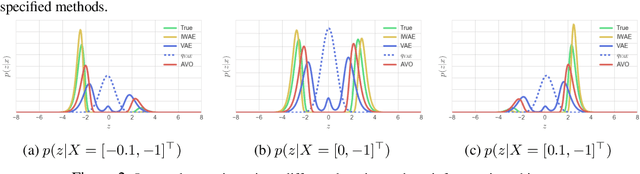
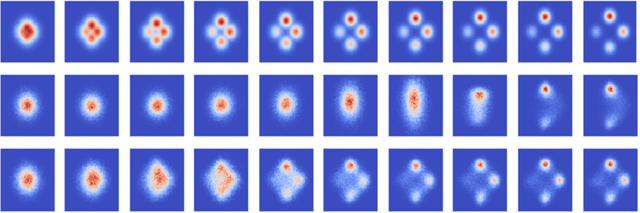
Despite the advances in the representational capacity of approximate distributions for variational inference, the optimization process can still limit the density that is ultimately learned. We demonstrate the drawbacks of biasing the true posterior to be unimodal, and introduce Annealed Variational Objectives (AVO) into the training of hierarchical variational methods. Inspired by Annealed Importance Sampling, the proposed method facilitates learning by incorporating energy tempering into the optimization objective. In our experiments, we demonstrate our method's robustness to deterministic warm up, and the benefits of encouraging exploration in the latent space.