 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideline2Graph: Profile-Aware Multimodal Parsing for Executable Clinical Decision Graphs
Apr 02, 2026Clinical practice guidelines are long, multimodal documents whose branching recommendations are difficult to convert into executable clinical decision support (CDS), and one-shot parsing often breaks cross-page continuity. Recent LLM/VLM extractors are mostly local or text-centric, under-specifying section interfaces and failing to consolidate cross-page control flow across full documents into one coherent decision graph. We present a decomposition-first pipeline that converts full-guideline evidence into an executable clinical decision graph through topology-aware chunking, interface-constrained chunk graph generation, and provenance-preserving global aggregation. Rather than relying on single-pass generation, the pipeline uses explicit entry/terminal interfaces and semantic deduplication to preserve cross-page continuity while keeping the induced control flow auditable and structurally consistent. We evaluate on an adjudicated prostate-guideline benchmark with matched inputs and the same underlying VLM backbone across compared methods. On the complete merged graph, our approach improves edge and triplet precision/recall from $19.6\%/16.1\%$ in existing models to $69.0\%/87.5\%$, while node recall rises from $78.1\%$ to $93.8\%$. These results support decomposition-first, auditable guideline-to-CDS conversion on this benchmark, while current evidence remains limited to one adjudicated prostate guideline and motivates broader multi-guideline validation.
Deep Metric Learning with Chance Constraints
Sep 19, 2022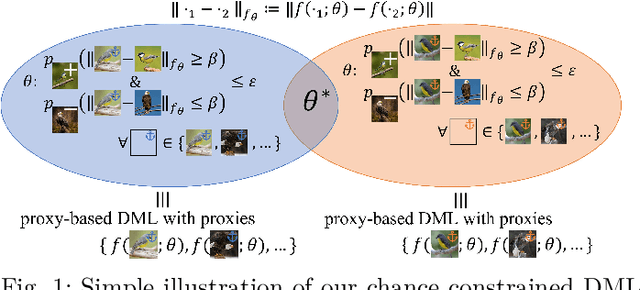
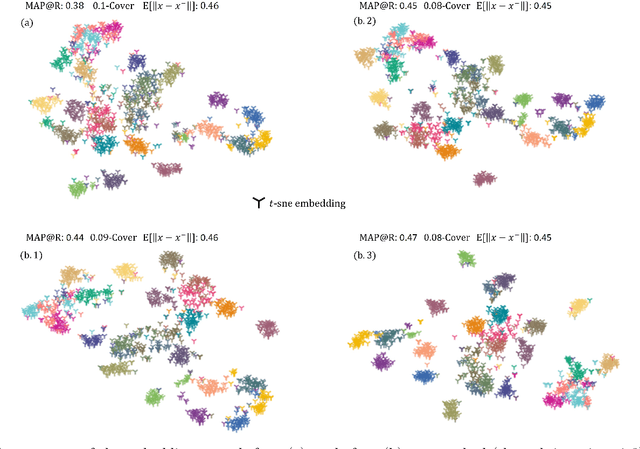
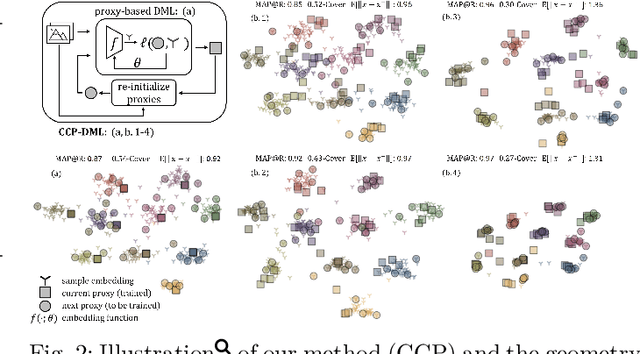

Deep metric learning (DML) aims to minimize empirical expected loss of the pairwise intra-/inter- class proximity violations in the embedding image. We relate DML to feasibility problem of finite chance constraints. We show that minimizer of proxy-based DML satisfies certain chance constraints, and that the worst case generalization performance of the proxy-based methods can be characterized by the radius of the smallest ball around a class proxy to cover the entire domain of the corresponding class samples, suggesting multiple proxies per class helps performance. To provide a scalable algorithm as well as exploiting more proxies, we consider the chance constraints implied by the minimizers of proxy-based DML instances and reformulate DML as finding a feasible point in intersection of such constraints, resulting in a problem to be approximately solved by iterative projections. Simply put, we repeatedly train a regularized proxy-based loss and re-initialize the proxies with the embeddings of the deliberately selected new samples. We apply our method with the well-accepted losses and evaluate on four popular benchmark datasets for image retrieval. Outperforming state-of-the-art, our method consistently improves the performance of the applied losses. Code is available at: https://github.com/yetigurbuz/ccp-dml