 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyRS-R1: Compact Multimodal Language Model for Remote Sensing
May 17, 2025



Remote-sensing applications often run on edge hardware that cannot host today's 7B-parameter multimodal language models. This paper introduces TinyRS, the first 2B-parameter multimodal small language model (MSLM) optimized for remote sensing tasks, and TinyRS-R1, its reasoning-augmented variant. Built upon Qwen2-VL-2B, TinyRS is trained through a four-stage pipeline: pre-training on million satellite images, instruction tuning on visual instruction examples, fine-tuning with Chain-of-Thought (CoT) annotations from the proposed reasoning dataset, and alignment via Group Relative Policy Optimization (GRPO). TinyRS-R1 achieves or surpasses the performance of recent 7B-parameter remote sensing models across classification, VQA, visual grounding, and open-ended question answering-while requiring just one-third of the memory and latency. Our analysis shows that CoT reasoning substantially benefits spatial grounding and scene understanding, while the non-reasoning TinyRS excels in concise, latency-sensitive VQA tasks. TinyRS-R1 represents the first domain-specialized MSLM with GRPO-aligned CoT reasoning for general-purpose remote sensing.
MilChat: Introducing Chain of Thought Reasoning and GRPO to a Multimodal Small Language Model for Remote Sensing
May 12, 2025Remarkable capabilities in understanding and generating text-image content have been demonstrated by recent advancements in multimodal large language models (MLLMs). However, their effectiveness in specialized domains-particularly those requiring resource-efficient and domain-specific adaptations-has remained limited. In this work, a lightweight multimodal language model termed MilChat is introduced, specifically adapted to analyze remote sensing imagery in secluded areas, including challenging missile launch sites. A new dataset, MilData, was compiled by verifying hundreds of aerial images through expert review, and subtle military installations were highlighted via detailed captions. Supervised fine-tuning on a 2B-parameter open-source MLLM with chain-of-thought (CoT) reasoning annotations was performed, enabling more accurate and interpretable explanations. Additionally, Group Relative Policy Optimization (GRPO) was leveraged to enhance the model's ability to detect critical domain-specific cues-such as defensive layouts and key military structures-while minimizing false positives on civilian scenes. Through empirical evaluations, it has been shown that MilChat significantly outperforms both larger, general-purpose multimodal models and existing remote sensing-adapted approaches on open-ended captioning and classification metrics. Over 80% recall and 98% precision were achieved on the newly proposed MilData benchmark, underscoring the potency of targeted fine-tuning and reinforcement learning in specialized real-world applications.
Improved Hard Example Mining Approach for Single Shot Object Detectors
Feb 26, 2022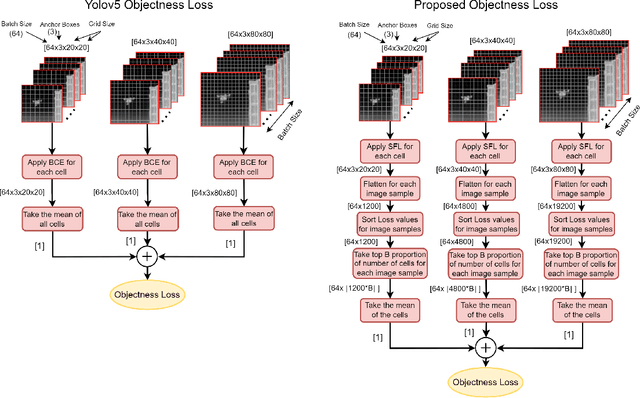
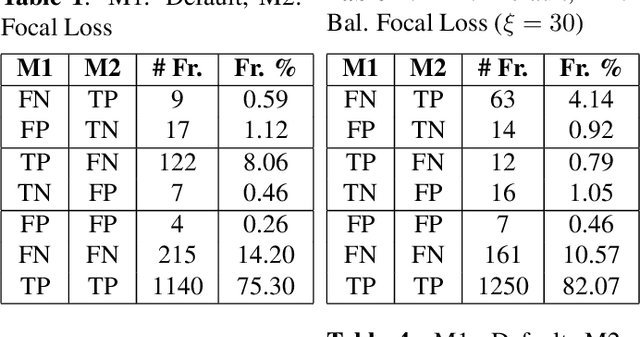
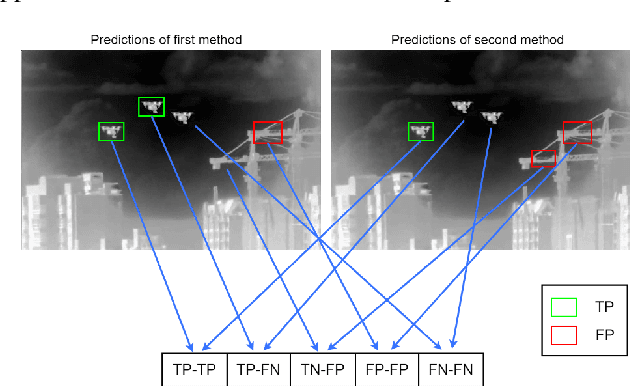
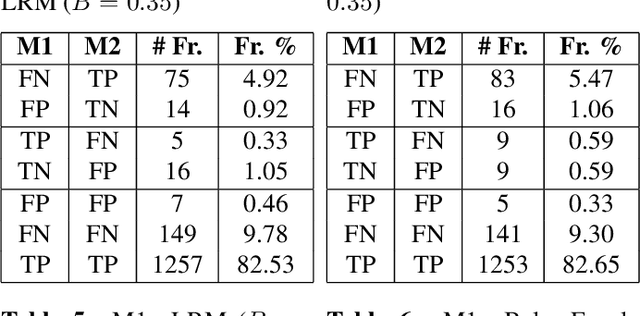
Hard example mining methods generally improve the performance of the object detectors, which suffer from imbalanced training sets. In this work, two existing hard example mining approaches (LRM and focal loss, FL) are adapted and combined in a state-of-the-art real-time object detector, YOLOv5. The effectiveness of the proposed approach for improving the performance on hard examples is extensively evaluated. The proposed method increases mAP by 3% compared to using the original loss function and around 1-2% compared to using the hard-mining methods (LRM or FL) individually on 2021 Anti-UAV Challenge Dataset.
Semi-Automatic Video Annotation For Object Detection
Jan 24, 2021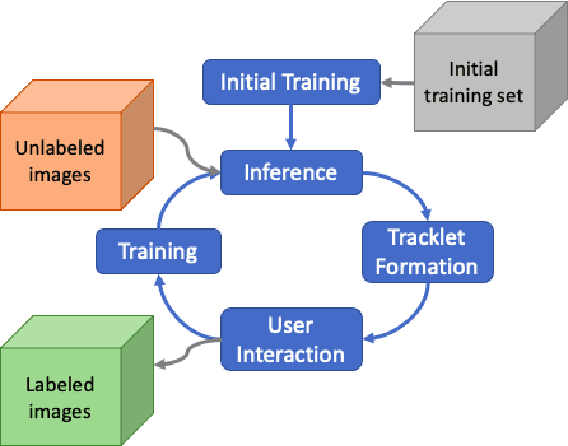
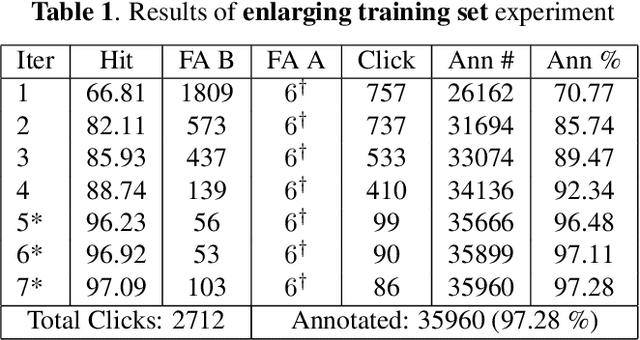

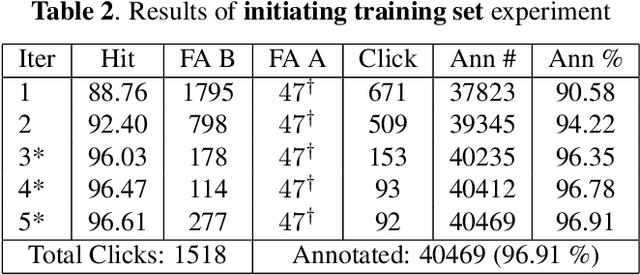
In this study, a semi-automatic video annotation method is proposed which utilizes temporal information to eliminate false-positives with a tracking-by-detection approach by employing multiple hypothesis tracking (MHT). MHT method automatically forms tracklets which are confirmed by human operators to enlarge the training set. A novel incremental learning approach helps to annotate videos in an iterative way. The experiments performed on AUTH Multidrone Dataset reveals that the annotation workload can be reduced up to 96% by the proposed approach.
Effect of Annotation Errors on Drone Detection with YOLOv3
Apr 14, 2020
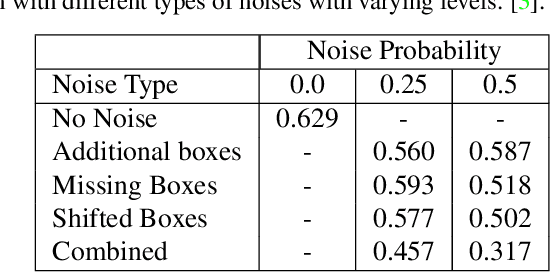

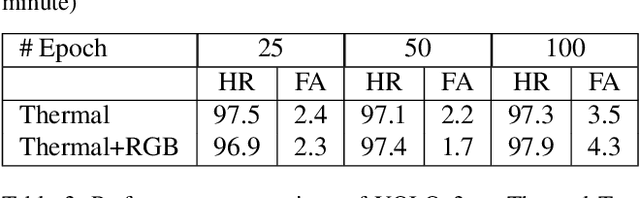
Following the recent advances in deep networks, object detection and tracking algorithms with deep learning backbones have been improved significantly; however, this rapid development resulted in the necessity of large amounts of annotated labels. Even if the details of such semi-automatic annotation processes for most of these datasets are not known precisely, especially for the video annotations, some automated labeling processes are usually employed. Unfortunately, such approaches might result with erroneous annotations. In this work, different types of annotation errors for object detection problem are simulated and the performance of a popular state-of-the-art object detector, YOLOv3, with erroneous annotations during training and testing stages is examined. Moreover, some inevitable annotation errors in CVPR-2020 Anti-UAV Challenge dataset is also examined in this manner, while proposing a solution to correct such annotation errors of this valuable data set.