 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
GGA-MG: Generative Genetic Algorithm for Music Generation
Apr 07, 2020

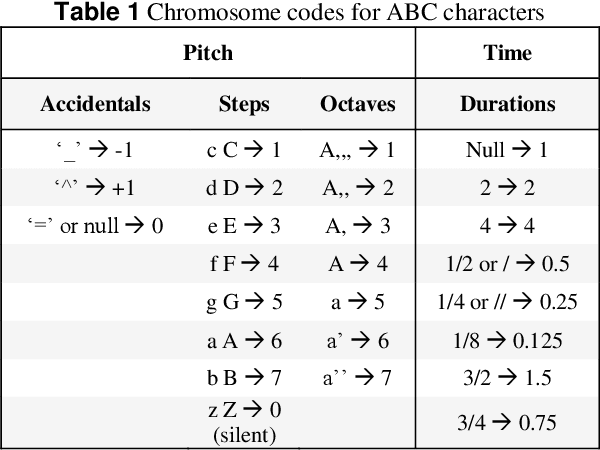
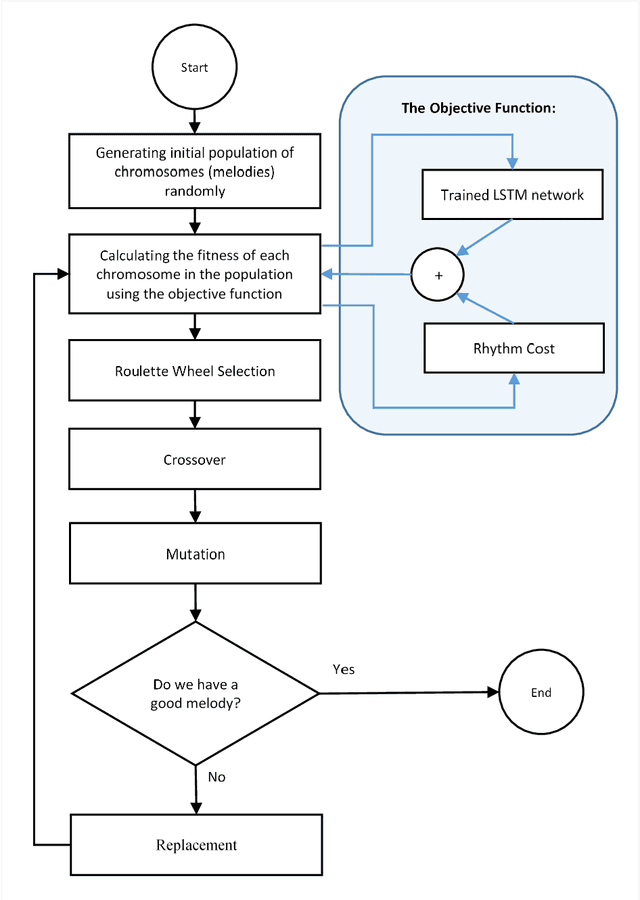
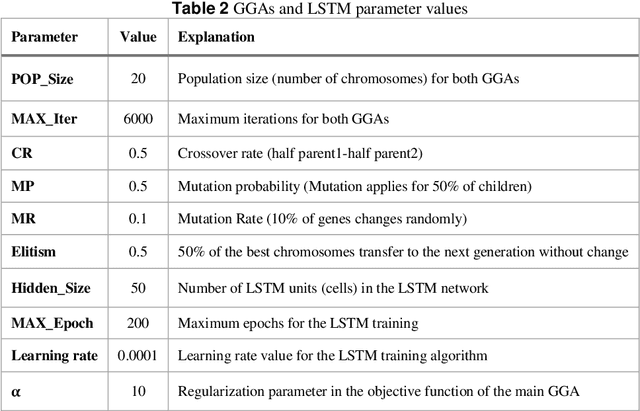
Music Generation (MG) is an interesting research topic that links the art of music and Artificial Intelligence (AI). The goal is to train an artificial composer to generate infinite, fresh, and pleasurable musical pieces. Music has different parts such as melody, harmony, and rhythm. In this paper, we propose a Generative Genetic Algorithm (GGA) to produce a melody automatically. The main GGA uses a Long Short-Term Memory (LSTM) recurrent neural network as the objective function, which should be trained by a spectrum of bad-to-good melodies. These melodies have to be provided by another GGA with a different objective function. Good melodies have been provided by CAMPINs collection. We have considered the rhythm in this work, too. The experimental results clearly show that the proposed GGA method is able to generate eligible melodies with natural transitions and without rhythm error.
Upmixing via style transfer: a variational autoencoder for disentangling spatial images and musical content
Mar 22, 2022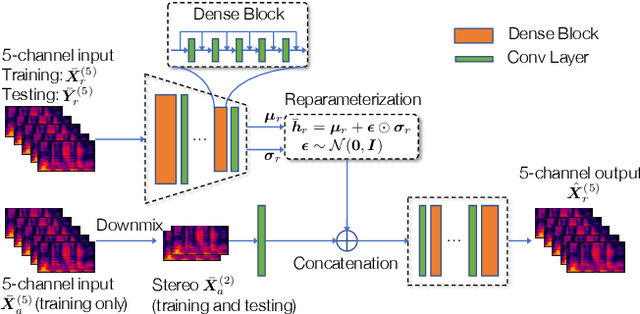

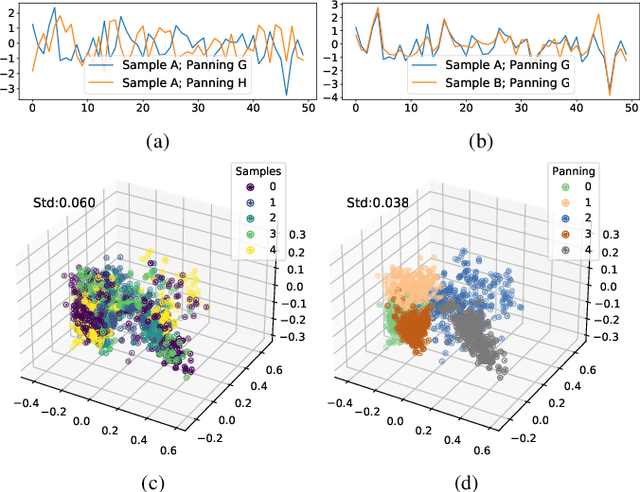
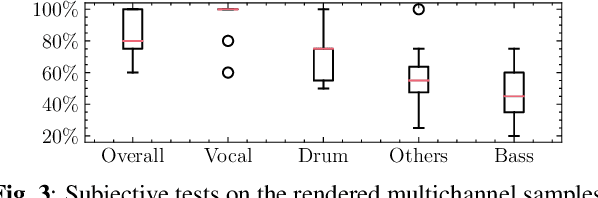
In the stereo-to-multichannel upmixing problem for music, one of the main tasks is to set the directionality of the instrument sources in the multichannel rendering results. In this paper, we propose a modified variational autoencoder model that learns a latent space to describe the spatial images in multichannel music. We seek to disentangle the spatial images and music content, so the learned latent variables are invariant to the music. At test time, we use the latent variables to control the panning of sources. We propose two upmixing use cases: transferring the spatial images from one song to another and blind panning based on the generative model. We report objective and subjective evaluation results to empirically show that our model captures spatial images separately from music content and achieves transfer-based interactive panning.
A Comparative Study of Western and Chinese Classical Music based on Soundscape Models
Feb 20, 2020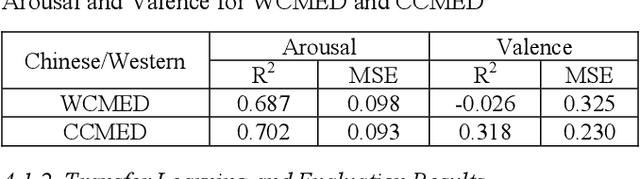
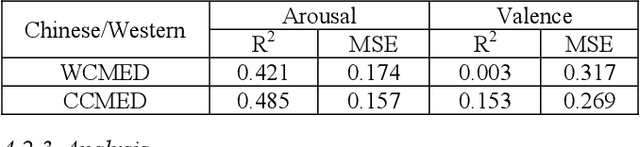
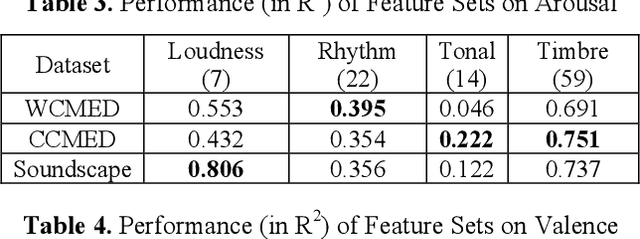
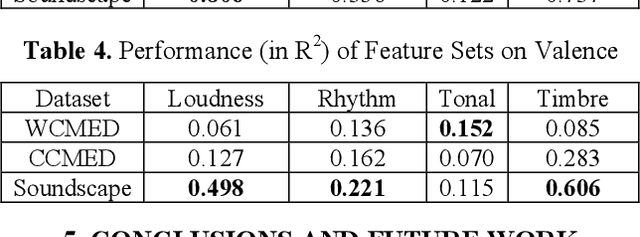
Whether literally or suggestively, the concept of soundscape is alluded in both modern and ancient music. In this study, we examine whether we can analyze and compare Western and Chinese classical music based on soundscape models. We addressed this question through a comparative study. Specifically, corpora of Western classical music excerpts (WCMED) and Chinese classical music excerpts (CCMED) were curated and annotated with emotional valence and arousal through a crowdsourcing experiment. We used a sound event detection (SED) and soundscape emotion recognition (SER) models with transfer learning to predict the perceived emotion of WCMED and CCMED. The results show that both SER and SED models could be used to analyze Chinese and Western classical music. The fact that SER and SED work better on Chinese classical music emotion recognition provides evidence that certain similarities exist between Chinese classical music and soundscape recordings, which permits transferability between machine learning models.
Teaching Qubits to Sing: Mission Impossible?
Jul 21, 2022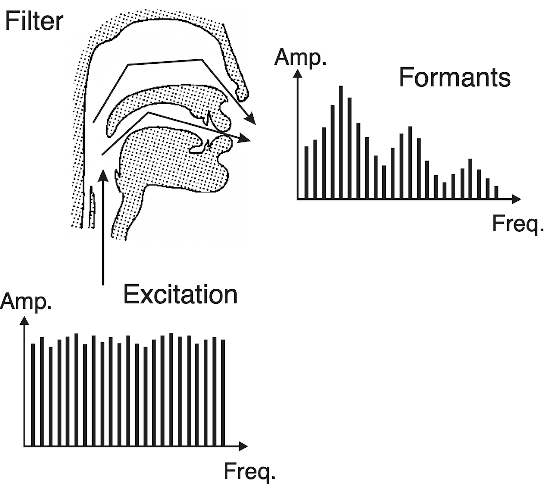
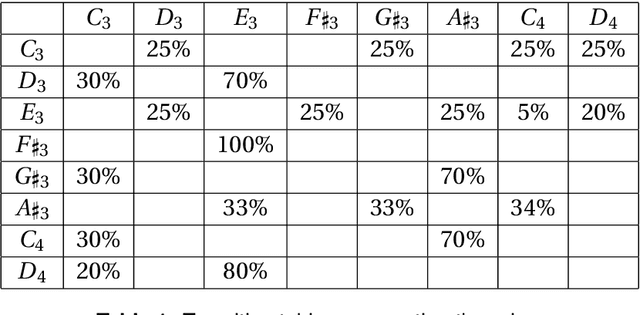
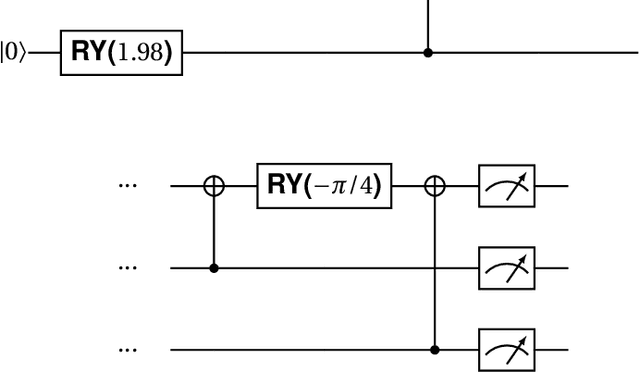
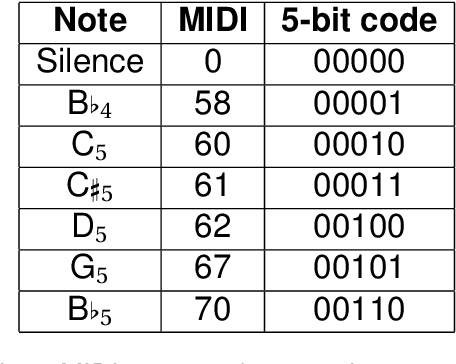
This paper introduces a system that learns to sing new tunes by listening to examples. It extracts sequencing rules from input music and uses these rules to generate new tunes, which are sung by a vocal synthesiser. We developed a method to represent rules for musical composition as quantum circuits. We claim that such musical rules are quantum native: they are naturally encodable in the amplitudes of quantum states. To evaluate a rule to generate a subsequent event, the system builds the respective quantum circuit dynamically and measures it. After a brief discussion about the vocal synthesis methods that we have been experimenting with, the paper introduces our novel generative music method through a practical example. The paper shows some experiments and concludes with a discussion about harnessing the creative potential of the system.
Graph Representation learning for Audio & Music genre Classification
Oct 23, 2019Music genre is arguably one of the most important and discriminative information for music and audio content. Visual representation based approaches have been explored on spectrograms for music genre classification. However, lack of quality data and augmentation techniques makes it difficult to employ deep learning techniques successfully. We discuss the application of graph neural networks on such task due to their strong inductive bias, and show that combination of CNN and GNN is able to achieve state-of-the-art results on GTZAN, and AudioSet (Imbalanced Music) datasets. We also discuss the role of Siamese Neural Networks as an analogous to GNN for learning edge similarity weights. Furthermore, we also perform visual analysis to understand the field-of-view of our model into the spectrogram based on genre labels.
Multilabel Automated Recognition of Emotions Induced Through Music
May 29, 2019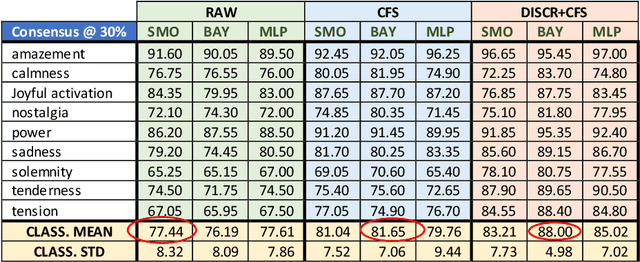
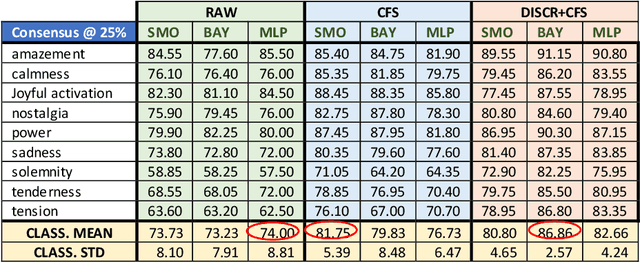
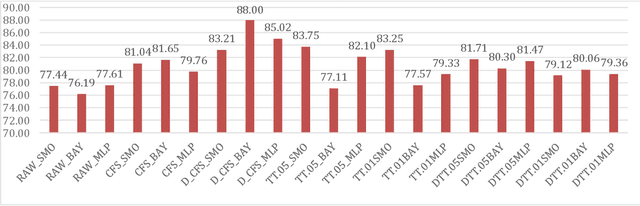
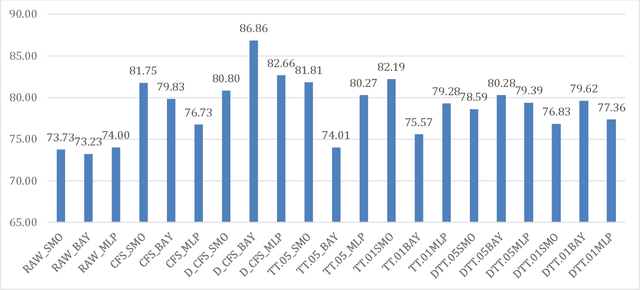
Achieving advancements in automatic recognition of emotions that music can induce require considering multiplicity and simultaneity of emotions. Comparison of different machine learning algorithms performing multilabel and multiclass classification is the core of our work. The study analyzes the implementation of the Geneva Emotional Music Scale 9 in the Emotify music dataset and the data distribution. The research goal is the identification of best methods towards the definition of the audio component of a new a new multimodal dataset for music emotion recognition.
A Semi-Personalized System for User Cold Start Recommendation on Music Streaming Apps
Jun 07, 2021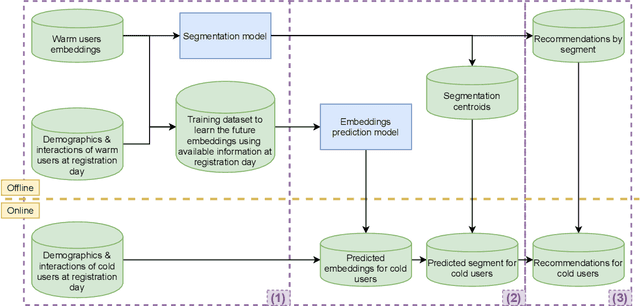
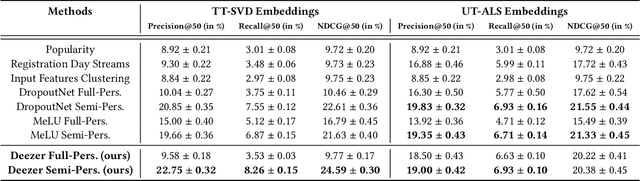
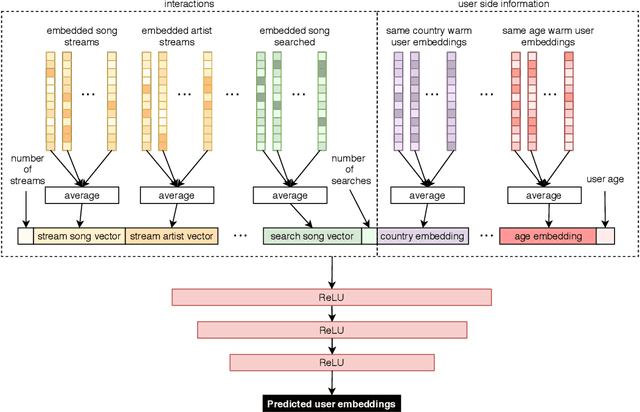

Music streaming services heavily rely on recommender systems to improve their users' experience, by helping them navigate through a large musical catalog and discover new songs, albums or artists. However, recommending relevant and personalized content to new users, with few to no interactions with the catalog, is challenging. This is commonly referred to as the user cold start problem. In this applied paper, we present the system recently deployed on the music streaming service Deezer to address this problem. The solution leverages a semi-personalized recommendation strategy, based on a deep neural network architecture and on a clustering of users from heterogeneous sources of information. We extensively show the practical impact of this system and its effectiveness at predicting the future musical preferences of cold start users on Deezer, through both offline and online large-scale experiments. Besides, we publicly release our code as well as anonymized usage data from our experiments. We hope that this release of industrial resources will benefit future research on user cold start recommendation.
Tracing Affordance and Item Adoption on Music Streaming Platforms
Sep 08, 2021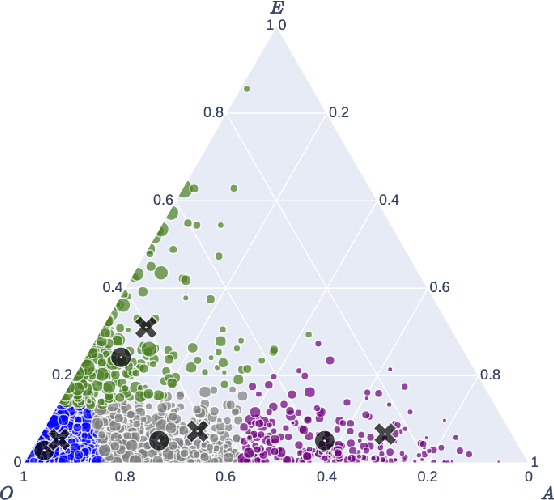
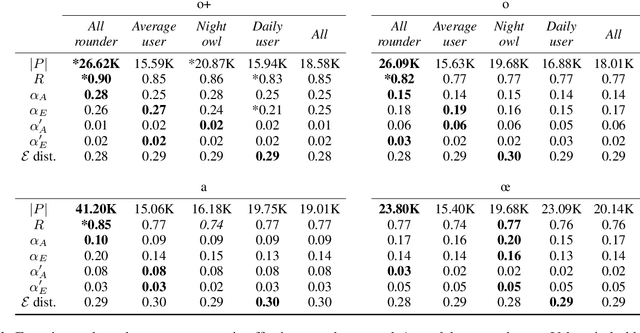
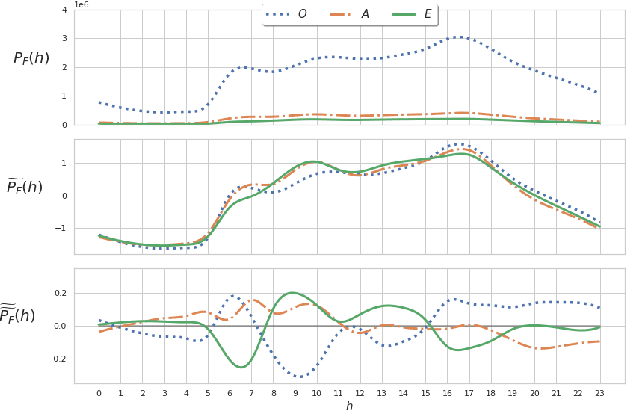
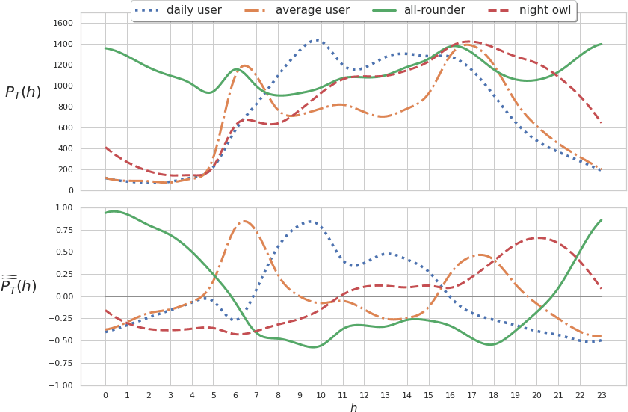
Popular music streaming platforms offer users a diverse network of content exploration through a triad of affordances: organic, algorithmic and editorial access modes. Whilst offering great potential for discovery, such platform developments also pose the modern user with daily adoption decisions on two fronts: platform affordance adoption and the adoption of recommendations therein. Following a carefully constrained set of Deezer users over a 2-year observation period, our work explores factors driving user behaviour in the broad sense, by differentiating users on the basis of their temporal daily usage, adoption of the main platform affordances, and the ways in which they react to them, especially in terms of recommendation adoption. Diverging from a perspective common in studies on the effects of recommendation, we assume and confirm that users exhibit very diverse behaviours in using and adopting the platform affordances. The resulting complex and quite heterogeneous picture demonstrates that there is no blanket answer for adoption practices of both recommendation features and recommendations.
Solving Audio Inverse Problems with a Diffusion Model
Oct 27, 2022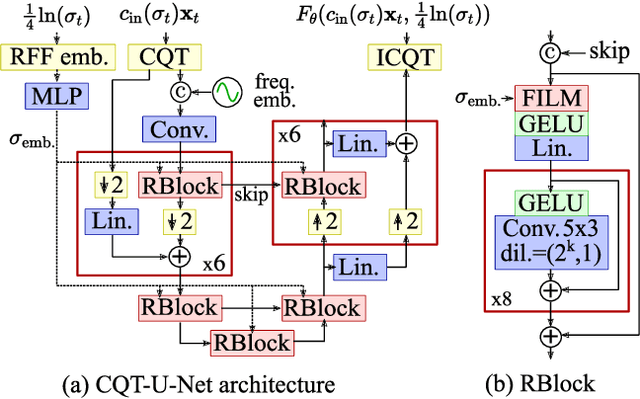
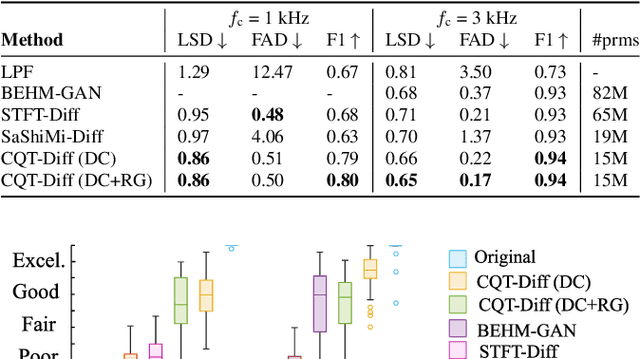

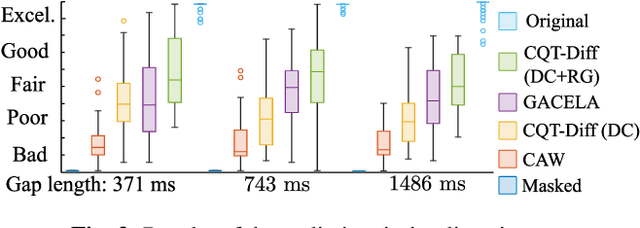
This paper presents CQT-Diff, a data-driven generative audio model that can, once trained, be used for solving various different audio inverse problems in a problem-agnostic setting. CQT-Diff is a neural diffusion model with an architecture that is carefully constructed to exploit pitch-equivariant symmetries in music. This is achieved by preconditioning the model with an invertible Constant-Q Transform (CQT), whose logarithmically-spaced frequency axis represents pitch equivariance as translation equivariance. The proposed method is evaluated with objective and subjective metrics in three different and varied tasks: audio bandwidth extension, inpainting, and declipping. The results show that CQT-Diff outperforms the compared baselines and ablations in audio bandwidth extension and, without retraining, delivers competitive performance against modern baselines in audio inpainting and declipping. This work represents the first diffusion-based general framework for solving inverse problems in audio processing.