 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Dynamics Interpreter Network: What are the Important Relations between Local Dynamics for Facial Trait Estimation?
Jul 24, 2018
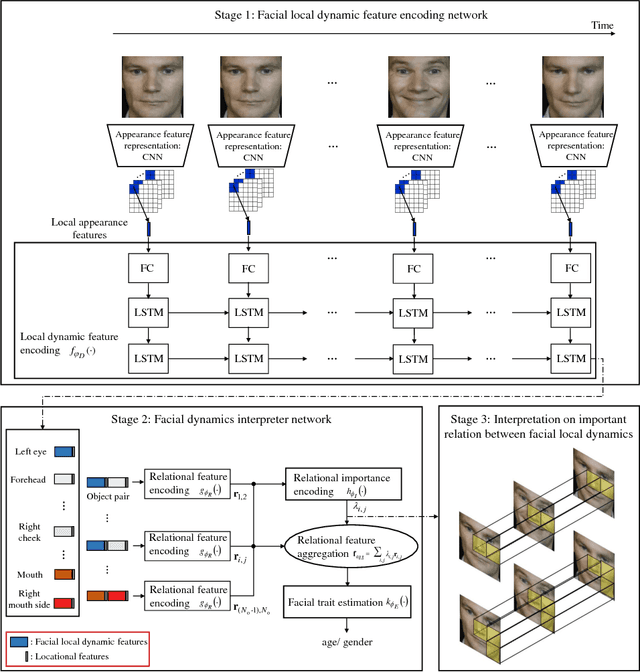

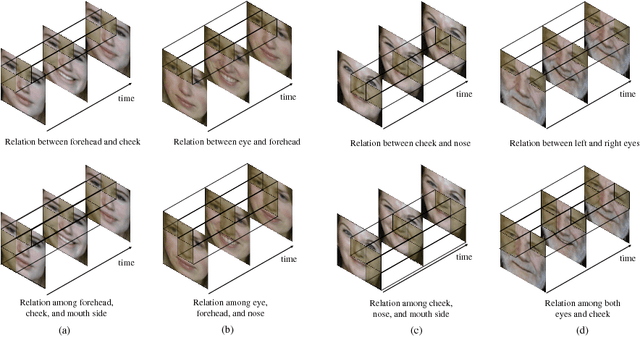

Human face analysis is an important task in computer vision. According to cognitive-psychological studies, facial dynamics could provide crucial cues for face analysis. The motion of a facial local region in facial expression is related to the motion of other facial local regions. In this paper, a novel deep learning approach, named facial dynamics interpreter network, has been proposed to interpret the important relations between local dynamics for estimating facial traits from expression sequence. The facial dynamics interpreter network is designed to be able to encode a relational importance, which is used for interpreting the relation between facial local dynamics and estimating facial traits. By comparative experiments, the effectiveness of the proposed method has been verified. The important relations between facial local dynamics are investigated by the proposed facial dynamics interpreter network in gender classification and age estimation. Moreover, experimental results show that the proposed method outperforms the state-of-the-art methods in gender classification and age estimation.
Analysing the Direction of Emotional Influence in Nonverbal Dyadic Communication: A Facial-Expression Study
Dec 16, 2020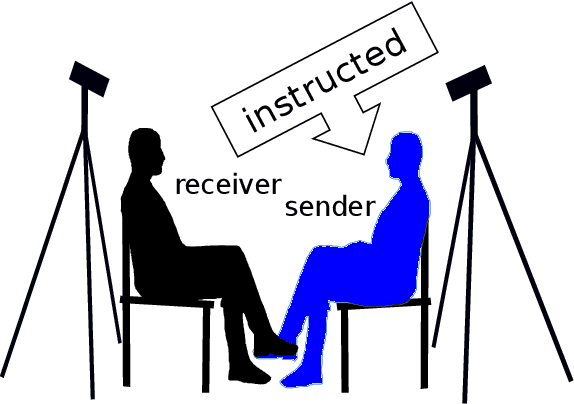
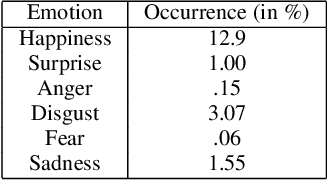
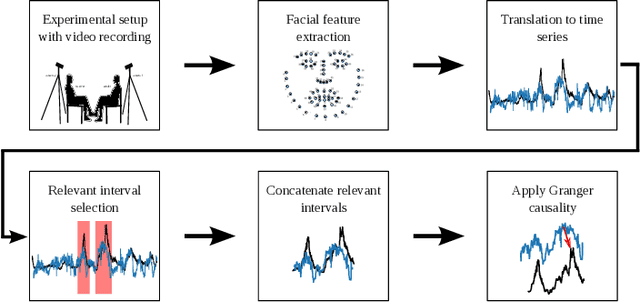
Identifying the direction of emotional influence in a dyadic dialogue is of increasing interest in the psychological sciences with applications in psychotherapy, analysis of political interactions, or interpersonal conflict behavior. Facial expressions are widely described as being automatic and thus hard to overtly influence. As such, they are a perfect measure for a better understanding of unintentional behavior cues about social-emotional cognitive processes. With this view, this study is concerned with the analysis of the direction of emotional influence in dyadic dialogue based on facial expressions only. We exploit computer vision capabilities along with causal inference theory for quantitative verification of hypotheses on the direction of emotional influence, i.e., causal effect relationships, in dyadic dialogues. We address two main issues. First, in a dyadic dialogue, emotional influence occurs over transient time intervals and with intensity and direction that are variant over time. To this end, we propose a relevant interval selection approach that we use prior to causal inference to identify those transient intervals where causal inference should be applied. Second, we propose to use fine-grained facial expressions that are present when strong distinct facial emotions are not visible. To specify the direction of influence, we apply the concept of Granger causality to the time series of facial expressions over selected relevant intervals. We tested our approach on newly, experimentally obtained data. Based on the quantitative verification of hypotheses on the direction of emotional influence, we were able to show that the proposed approach is most promising to reveal the causal effect pattern in various instructed interaction conditions.
Fully-attentive and interpretable: vision and video vision transformers for pain detection
Oct 27, 2022
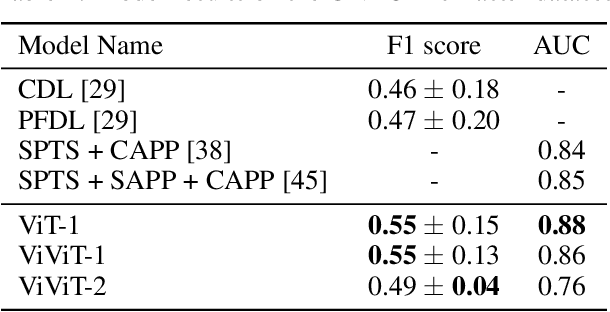
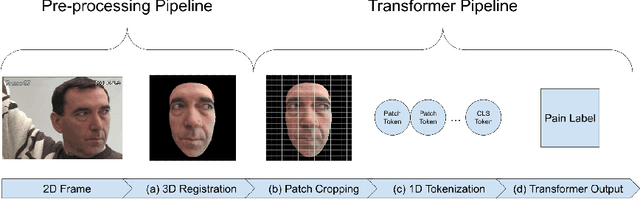
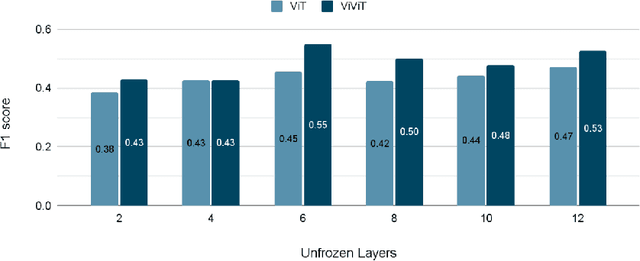
Pain is a serious and costly issue globally, but to be treated, it must first be detected. Vision transformers are a top-performing architecture in computer vision, with little research on their use for pain detection. In this paper, we propose the first fully-attentive automated pain detection pipeline that achieves state-of-the-art performance on binary pain detection from facial expressions. The model is trained on the UNBC-McMaster dataset, after faces are 3D-registered and rotated to the canonical frontal view. In our experiments we identify important areas of the hyperparameter space and their interaction with vision and video vision transformers, obtaining 3 noteworthy models. We analyse the attention maps of one of our models, finding reasonable interpretations for its predictions. We also evaluate Mixup, an augmentation technique, and Sharpness-Aware Minimization, an optimizer, with no success. Our presented models, ViT-1 (F1 score 0.55 +- 0.15), ViViT-1 (F1 score 0.55 +- 0.13), and ViViT-2 (F1 score 0.49 +- 0.04), all outperform earlier works, showing the potential of vision transformers for pain detection. Code is available at https://github.com/IPDTFE/ViT-McMaster
Deep and Shallow Covariance Feature Quantization for 3D Facial Expression Recognition
May 12, 2021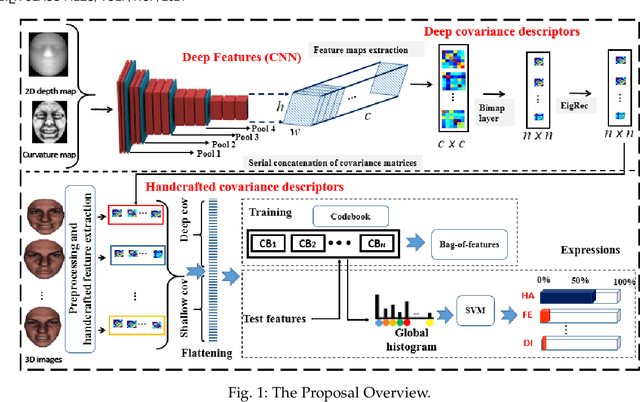
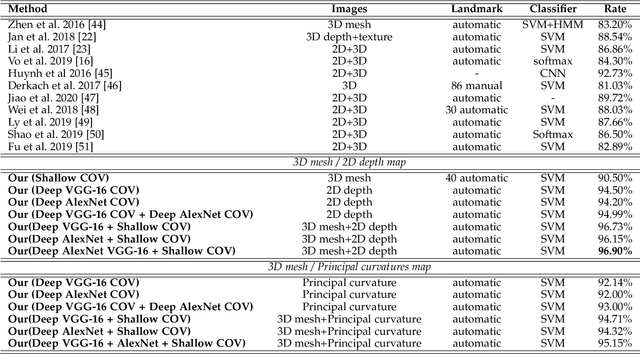
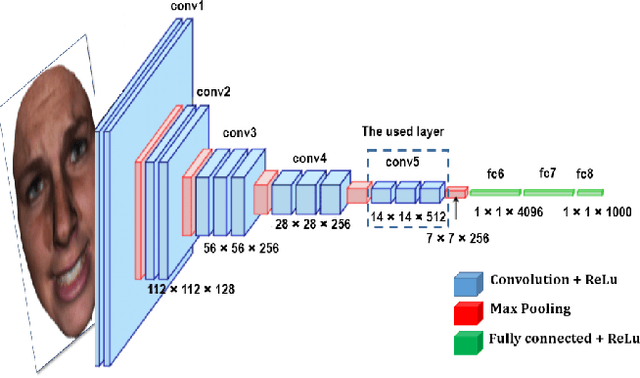
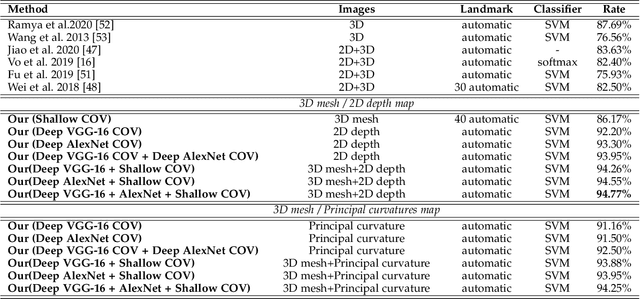
Facial expressions recognition (FER) of 3D face scans has received a significant amount of attention in recent years. Most of the facial expression recognition methods have been proposed using mainly 2D images. These methods suffer from several issues like illumination changes and pose variations. Moreover, 2D mapping from 3D images may lack some geometric and topological characteristics of the face. Hence, to overcome this problem, a multi-modal 2D + 3D feature-based method is proposed. We extract shallow features from the 3D images, and deep features using Convolutional Neural Networks (CNN) from the transformed 2D images. Combining these features into a compact representation uses covariance matrices as descriptors for both features instead of single-handedly descriptors. A covariance matrix learning is used as a manifold layer to reduce the deep covariance matrices size and enhance their discrimination power while preserving their manifold structure. We then use the Bag-of-Features (BoF) paradigm to quantize the covariance matrices after flattening. Accordingly, we obtained two codebooks using shallow and deep features. The global codebook is then used to feed an SVM classifier. High classification performances have been achieved on the BU-3DFE and Bosphorus datasets compared to the state-of-the-art methods.
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
Jan 25, 2021

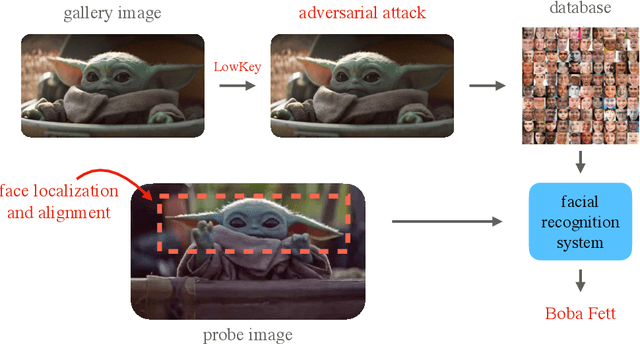
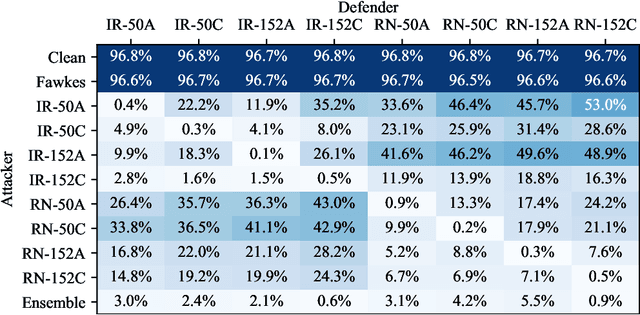
Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%.
A Facial Feature Discovery Framework for Race Classification Using Deep Learning
Mar 29, 2021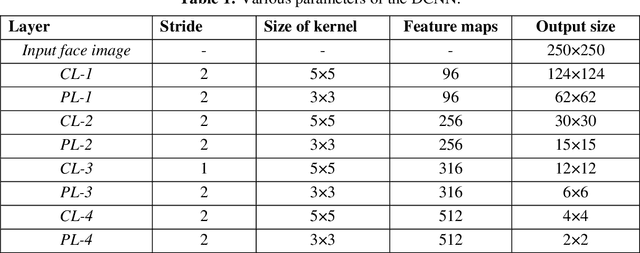
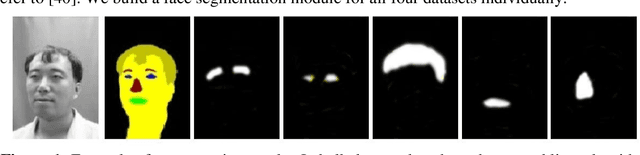

Race classification is a long-standing challenge in the field of face image analysis. The investigation of salient facial features is an important task to avoid processing all face parts. Face segmentation strongly benefits several face analysis tasks, including ethnicity and race classification. We propose a raceclassification algorithm using a prior face segmentation framework. A deep convolutional neural network (DCNN) was used to construct a face segmentation model. For training the DCNN, we label face images according to seven different classes, that is, nose, skin, hair, eyes, brows, back, and mouth. The DCNN model developed in the first phase was used to create segmentation results. The probabilistic classification method is used, and probability maps (PMs) are created for each semantic class. We investigated five salient facial features from among seven that help in race classification. Features are extracted from the PMs of five classes, and a new model is trained based on the DCNN. We assessed the performance of the proposed race classification method on four standard face datasets, reporting superior results compared with previous studies.
* Number of pages in the paper are 15
3D-CNN for Facial Micro- and Macro-expression Spotting on Long Video Sequences using Temporal Oriented Reference Frame
Jun 10, 2021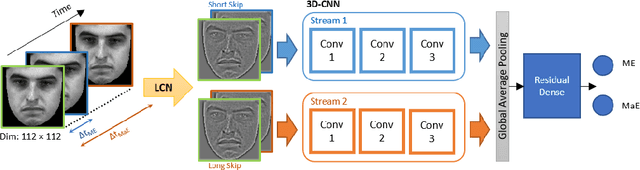
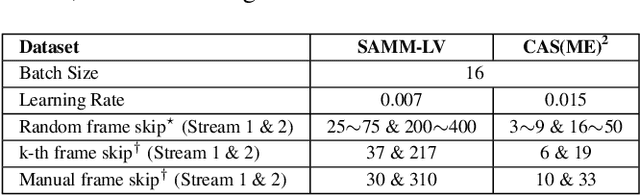
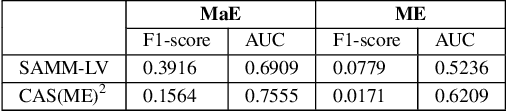
Facial expression spotting is the preliminary step for micro- and macro-expression analysis. The task of reliably spotting such expressions in video sequences is currently unsolved. The current best systems depend upon optical flow methods to extract regional motion features, before categorisation of that motion into a specific class of facial movement. Optical flow is susceptible to drift error, which introduces a serious problem for motions with long-term dependencies, such as high frame-rate macro-expression. We propose a purely deep learning solution which, rather than track frame differential motion, compares via a convolutional model, each frame with two temporally local reference frames. Reference frames are sampled according to calculated micro- and macro-expression durations. We show that our solution achieves state-of-the-art performance (F1-score of 0.126) in a dataset of high frame-rate (200 fps) long video sequences (SAMM-LV) and is competitive in a low frame-rate (30 fps) dataset (CAS(ME)2). In this paper, we document our deep learning model and parameters, including how we use local contrast normalisation, which we show is critical for optimal results. We surpass a limitation in existing methods, and advance the state of deep learning in the domain of facial expression spotting.
Landmark Enforcement and Style Manipulation for Generative Morphing
Oct 18, 2022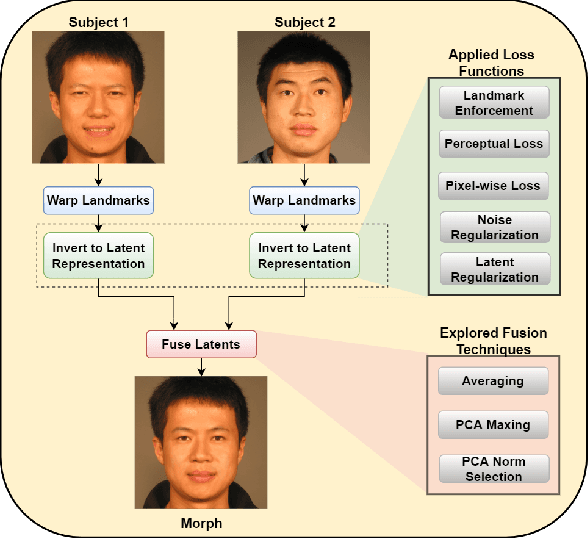
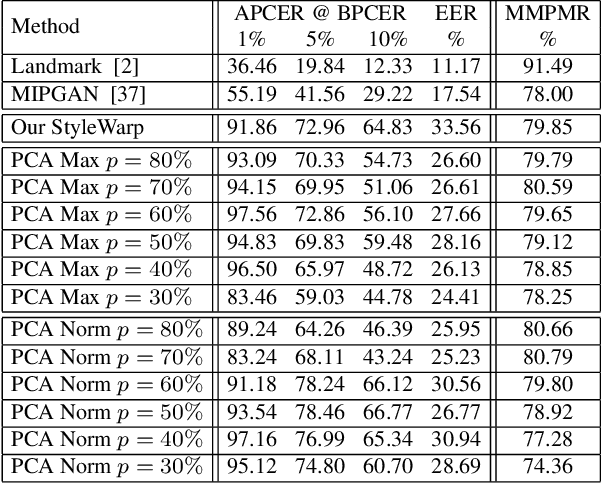

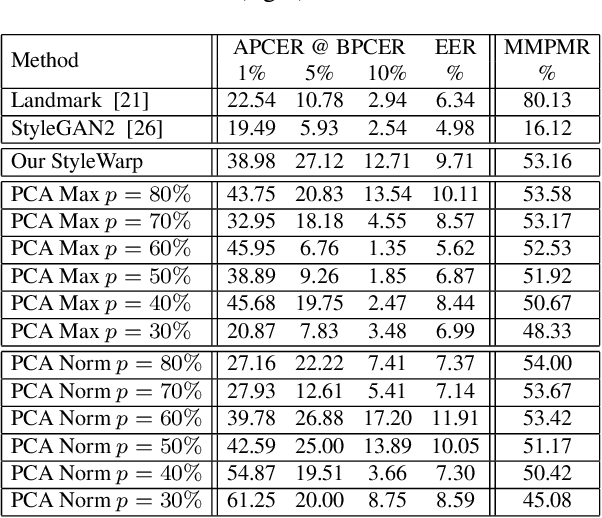
Morph images threaten Facial Recognition Systems (FRS) by presenting as multiple individuals, allowing an adversary to swap identities with another subject. Morph generation using generative adversarial networks (GANs) results in high-quality morphs unaffected by the spatial artifacts caused by landmark-based methods, but there is an apparent loss in identity with standard GAN-based morphing methods. In this paper, we propose a novel StyleGAN morph generation technique by introducing a landmark enforcement method to resolve this issue. Considering this method, we aim to enforce the landmarks of the morph image to represent the spatial average of the landmarks of the bona fide faces and subsequently the morph images to inherit the geometric identity of both bona fide faces. Exploration of the latent space of our model is conducted using Principal Component Analysis (PCA) to accentuate the effect of both the bona fide faces on the morphed latent representation and address the identity loss issue with latent domain averaging. Additionally, to improve high frequency reconstruction in the morphs, we study the train-ability of the noise input for the StyleGAN2 model.
Improving User's Sense of Participation in Robot-Driven Dialogue
Oct 18, 2022
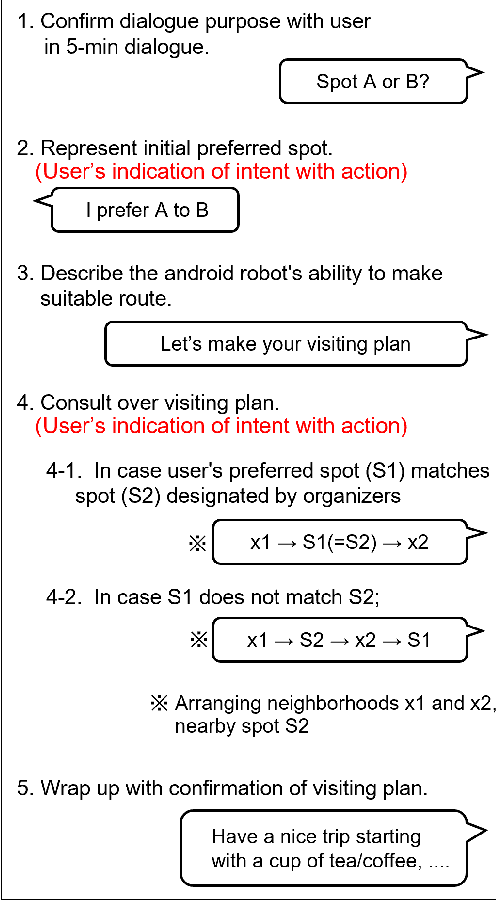
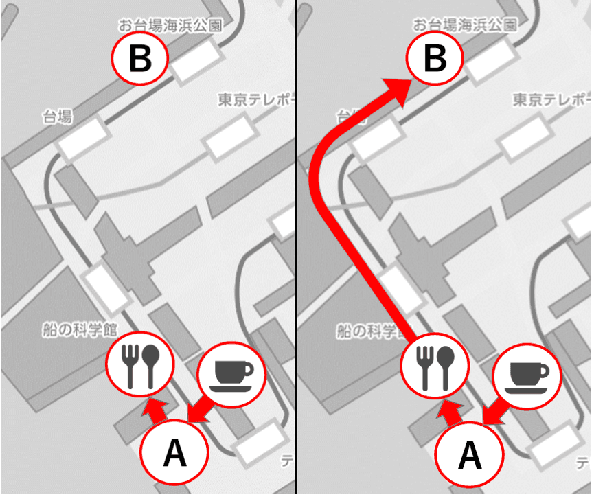
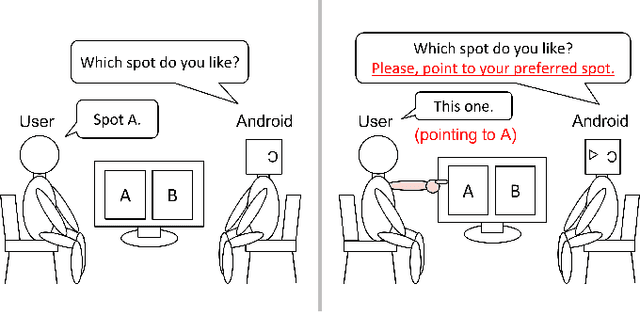
In task-oriented dialogues with symbiotic robots, the robot usually takes the initiative in dialogue progression and topic selection. In such robot-driven dialogue, the user's sense of participation in the dialogue is reduced because the degree of freedom in timing and content of speech is limited, and as a result, the user's familiarity with and trust in the robot as a dialogue partner and the level of dialogue satisfaction decrease. In this study, we constructed a travel agent dialogue system focusing on improving the sense of dialogue participation. At the beginning of the dialogue, the robot tells the user the purpose of the upcoming dialogue and indicates that it is responsible for assisting the user in making decisions. In addition, in situations where users were asked to state their preferences, the robot encourages them to express their intentions with actions, as well as spoken language responses. In addition, we attempted to reduce the sense of discomfort felt toward the android robot by devising a timing control for the robot's detailed movements and facial expressions.