 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discovering Patterns in Time-Varying Graphs: A Triclustering Approach
Aug 29, 2016
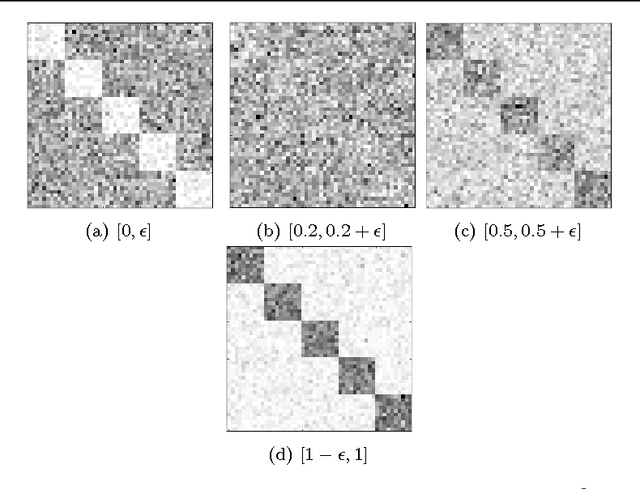
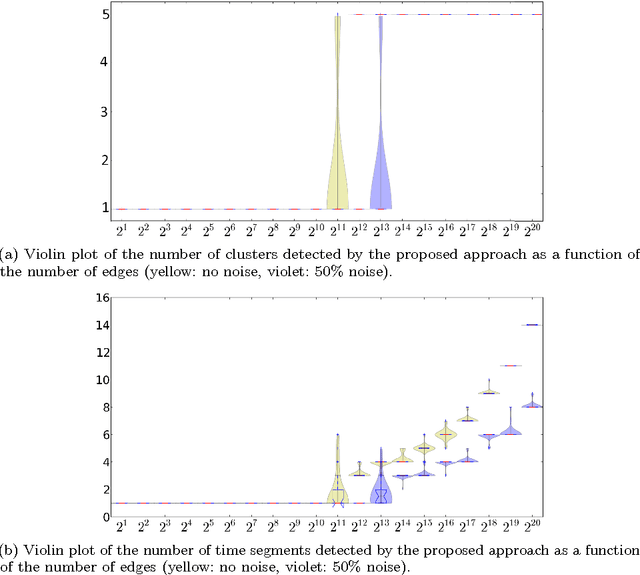

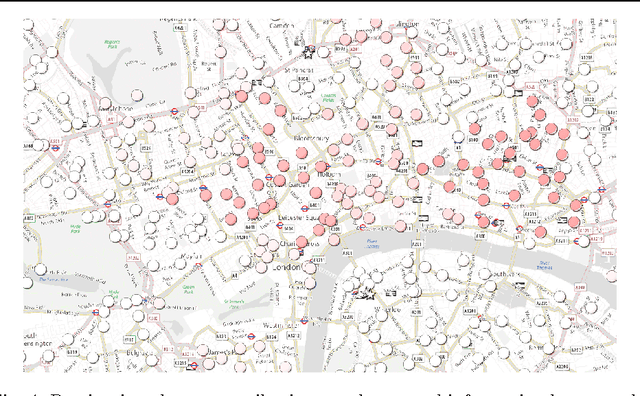
This paper introduces a novel technique to track structures in time varying graphs. The method uses a maximum a posteriori approach for adjusting a three-dimensional co-clustering of the source vertices, the destination vertices and the time, to the data under study, in a way that does not require any hyper-parameter tuning. The three dimensions are simultaneously segmented in order to build clusters of source vertices, destination vertices and time segments where the edge distributions across clusters of vertices follow the same evolution over the time segments. The main novelty of this approach lies in that the time segments are directly inferred from the evolution of the edge distribution between the vertices, thus not requiring the user to make any a priori quantization. Experiments conducted on artificial data illustrate the good behavior of the technique, and a study of a real-life data set shows the potential of the proposed approach for exploratory data analysis.
Project-Level Encoding for Neural Source Code Summarization of Subroutines
Mar 22, 2021
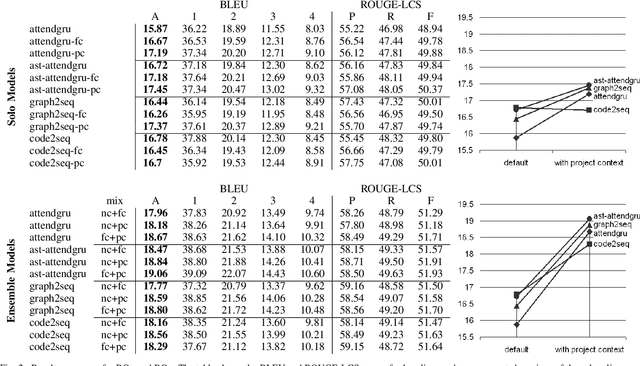
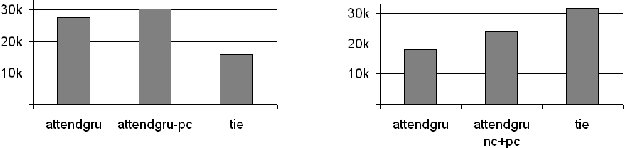
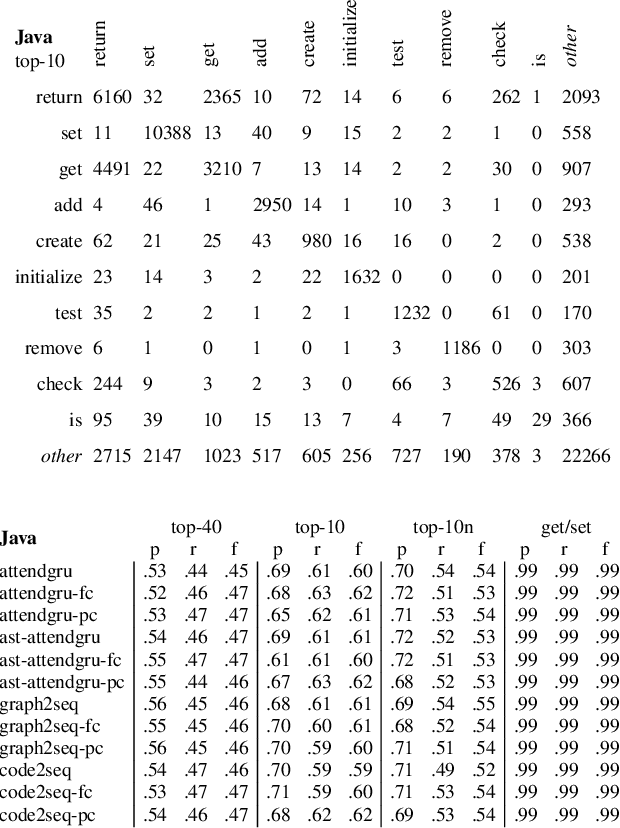
Source code summarization of a subroutine is the task of writing a short, natural language description of that subroutine. The description usually serves in documentation aimed at programmers, where even brief phrase (e.g. "compresses data to a zip file") can help readers rapidly comprehend what a subroutine does without resorting to reading the code itself. Techniques based on neural networks (and encoder-decoder model designs in particular) have established themselves as the state-of-the-art. Yet a problem widely recognized with these models is that they assume the information needed to create a summary is present within the code being summarized itself - an assumption which is at odds with program comprehension literature. Thus a current research frontier lies in the question of encoding source code context into neural models of summarization. In this paper, we present a project-level encoder to improve models of code summarization. By project-level, we mean that we create a vectorized representation of selected code files in a software project, and use that representation to augment the encoder of state-of-the-art neural code summarization techniques. We demonstrate how our encoder improves several existing models, and provide guidelines for maximizing improvement while controlling time and resource costs in model size.
Retrieving Event-related Human Brain Dynamics from Natural Sentence Reading
Mar 29, 2021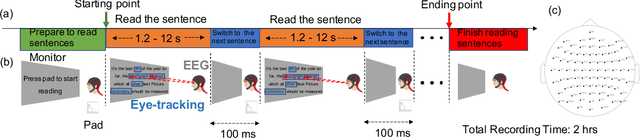
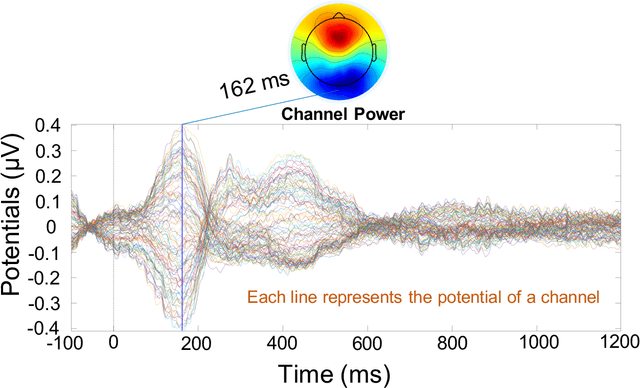
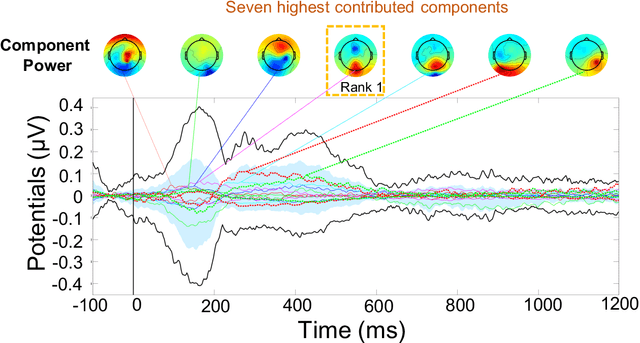
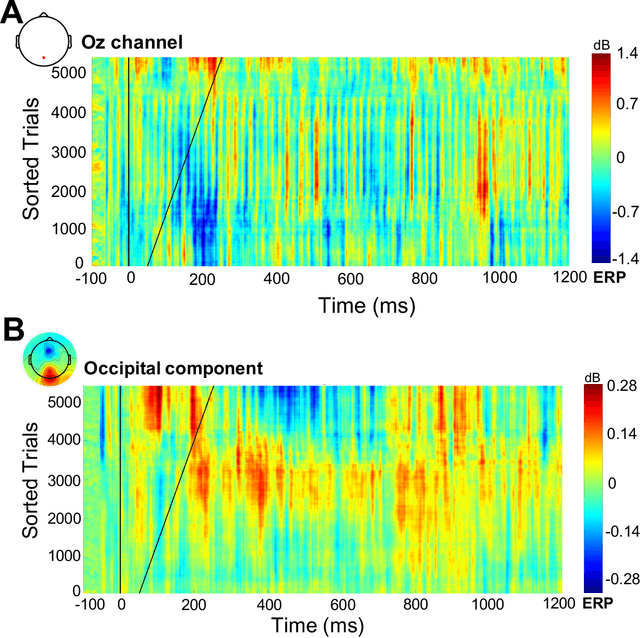
Electroencephalography (EEG) signals recordings when people reading natural languages are commonly used as a cognitive method to interpret human language understanding in neuroscience and psycholinguistics. Previous studies have demonstrated that the human fixation and activation in word reading associated with some brain regions, but it is not clear when and how to measure the brain dynamics across time and frequency domains. In this study, we propose the first analysis of event-related brain potentials (ERPs), and event-related spectral perturbations (ERSPs) on benchmark datasets which consist of sentence-level simultaneous EEG and related eye-tracking recorded from human natural reading experiment tasks. Our results showed peaks evoked at around 162 ms after the stimulus (starting to read each sentence) in the occipital area, indicating the brain retriving lexical and semantic visual information processing approaching 200 ms from the sentence onset. Furthermore, the occipital ERP around 200ms presents negative power and positive power in short and long reaction times. In addition, the occipital ERSP around 200ms demonstrated increased high gamma and decreased low beta and low gamma power, relative to the baseline. Our results implied that most of the semantic-perception responses occurred around the 200ms in alpha, beta and gamma bands of EEG signals. Our findings also provide potential impacts on promoting cognitive natural language processing models evaluation from EEG dynamics.
Approximate Tolerance and Prediction in Non-normal Models with Application to Clinical Trial Recruitment and End-of-study Success
Nov 23, 2020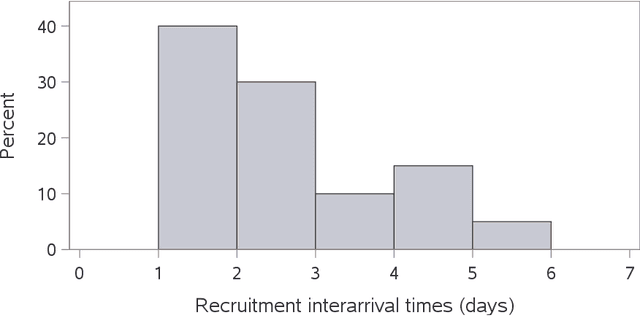
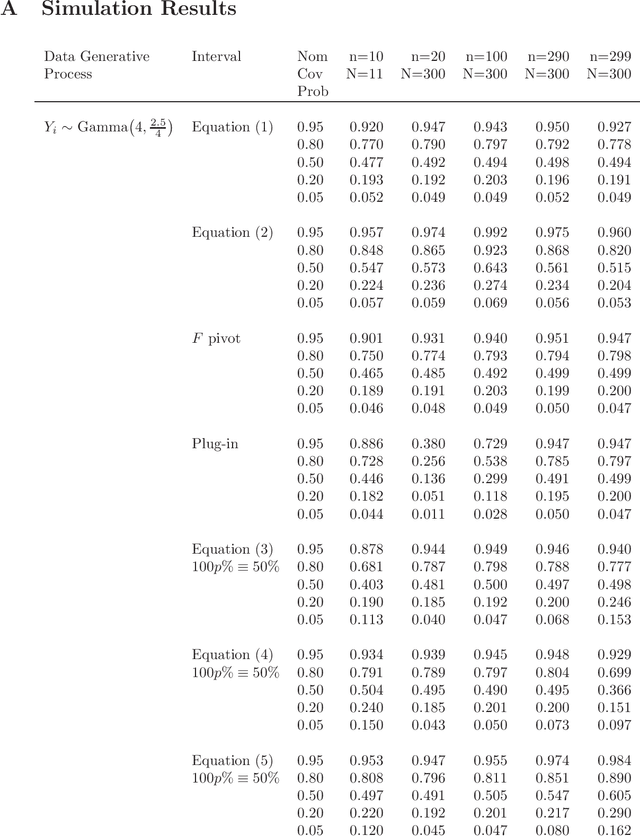
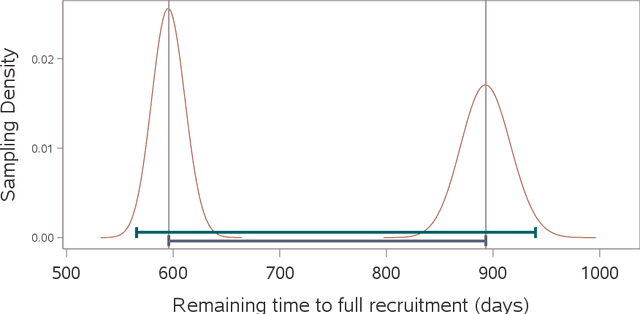
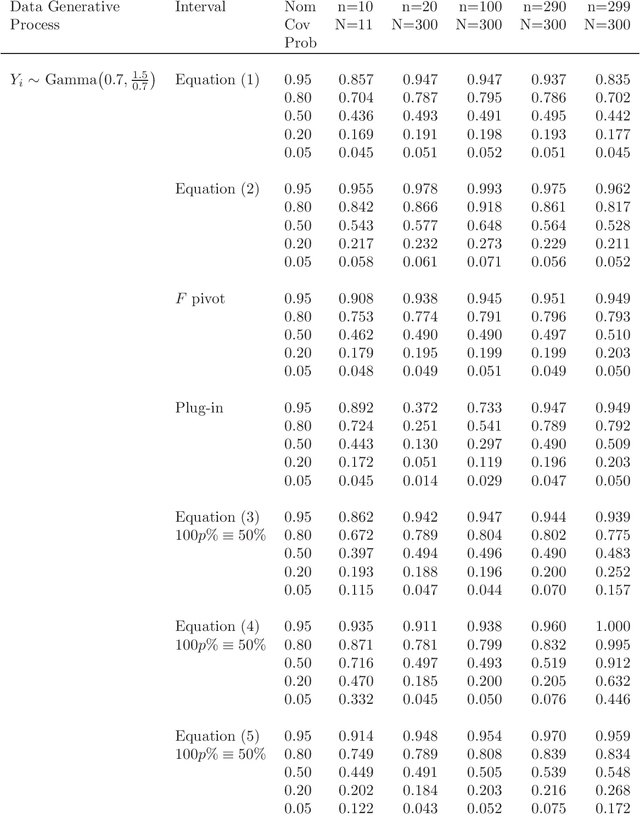
A prediction interval covers a future observation from a random process in repeated sampling, and is typically constructed by identifying a pivotal quantity that is also an ancillary statistic. Outside of normality it can sometimes be challenging to identify an ancillary pivotal quantity without assuming some of the model parameters are known. A common solution is to identify an appropriate transformation of the data that yields normally distributed observations, or to treat model parameters as random variables and construct a Bayesian predictive distribution. Analogously, a tolerance interval covers a population percentile in repeated sampling and poses similar challenges outside of normality. The approach we consider leverages a link function that results in a pivotal quantity that is approximately normally distributed and produces tolerance and prediction intervals that work well for non-normal models where identifying an exact pivotal quantity may be intractable. This is the approach we explore when modeling recruitment interarrival time in clinical trials, and ultimately, time to complete recruitment.
Restless-UCB, an Efficient and Low-complexity Algorithm for Online Restless Bandits
Nov 05, 2020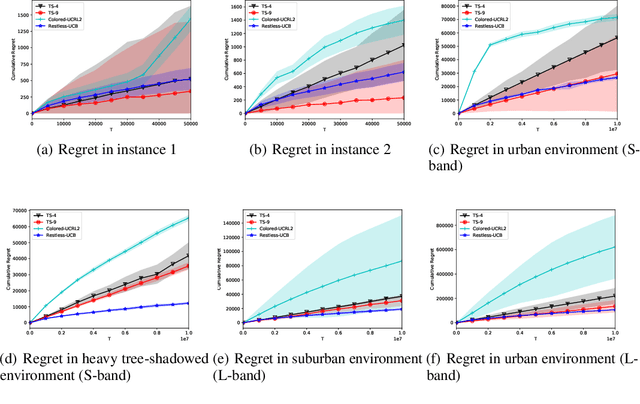
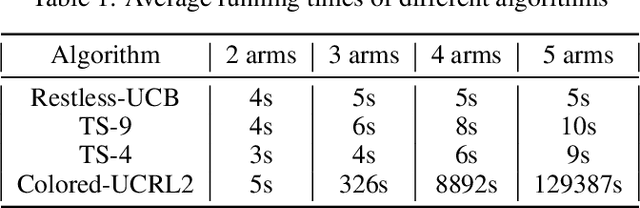
We study the online restless bandit problem, where the state of each arm evolves according to a Markov chain, and the reward of pulling an arm depends on both the pulled arm and the current state of the corresponding Markov chain. In this paper, we propose Restless-UCB, a learning policy that follows the explore-then-commit framework. In Restless-UCB, we present a novel method to construct offline instances, which only requires $O(N)$ time-complexity ($N$ is the number of arms) and is exponentially better than the complexity of existing learning policy. We also prove that Restless-UCB achieves a regret upper bound of $\tilde{O}((N+M^3)T^{2\over 3})$, where $M$ is the Markov chain state space size and $T$ is the time horizon. Compared to existing algorithms, our result eliminates the exponential factor (in $M,N$) in the regret upper bound, due to a novel exploitation of the sparsity in transitions in general restless bandit problems. As a result, our analysis technique can also be adopted to tighten the regret bounds of existing algorithms. Finally, we conduct experiments based on real-world dataset, to compare the Restless-UCB policy with state-of-the-art benchmarks. Our results show that Restless-UCB outperforms existing algorithms in regret, and significantly reduces the running time.
Deep Learning for Real-Time Crime Forecasting and its Ternarization
Nov 23, 2017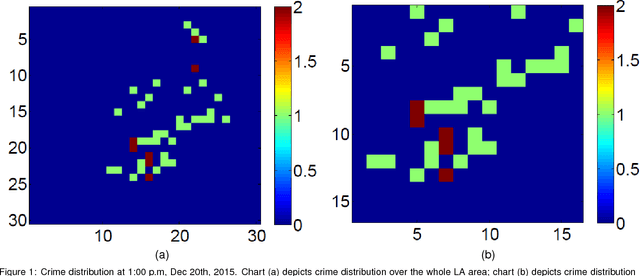
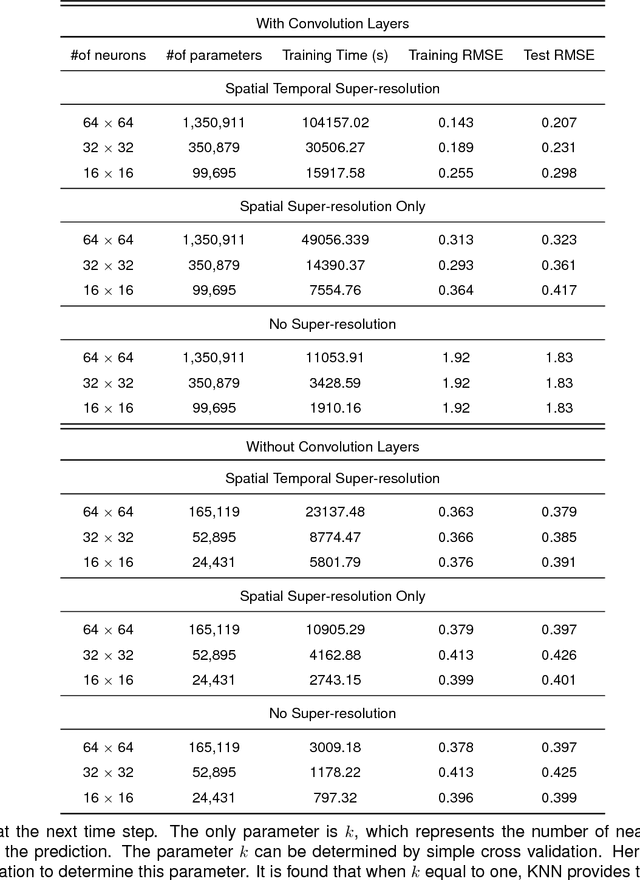
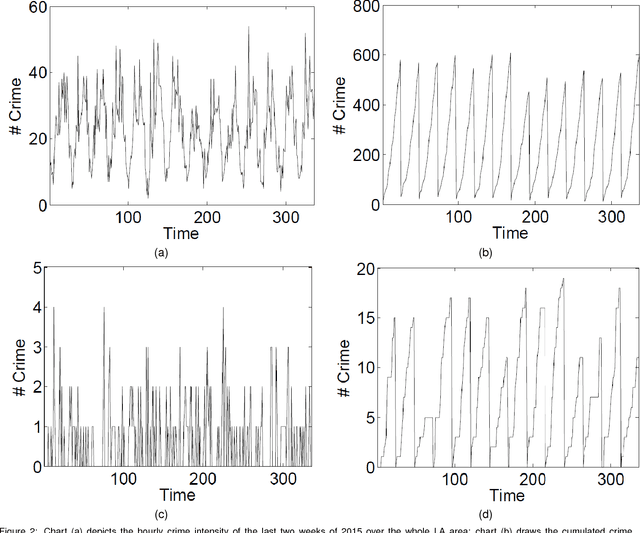
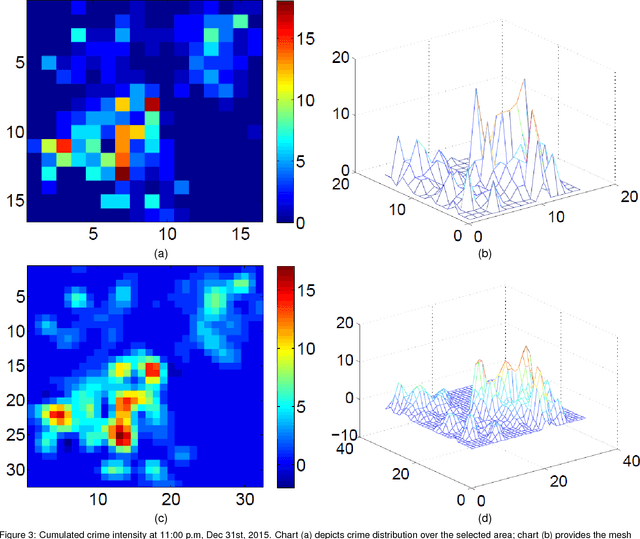
Real-time crime forecasting is important. However, accurate prediction of when and where the next crime will happen is difficult. No known physical model provides a reasonable approximation to such a complex system. Historical crime data are sparse in both space and time and the signal of interests is weak. In this work, we first present a proper representation of crime data. We then adapt the spatial temporal residual network on the well represented data to predict the distribution of crime in Los Angeles at the scale of hours in neighborhood-sized parcels. These experiments as well as comparisons with several existing approaches to prediction demonstrate the superiority of the proposed model in terms of accuracy. Finally, we present a ternarization technique to address the resource consumption issue for its deployment in real world. This work is an extension of our short conference proceeding paper [Wang et al, Arxiv 1707.03340].
ClaRe: Practical Class Incremental Learning By Remembering Previous Class Representations
Mar 29, 2021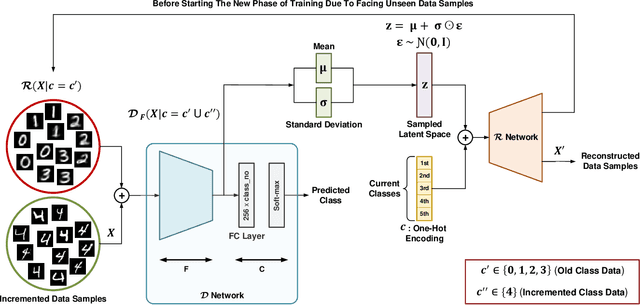

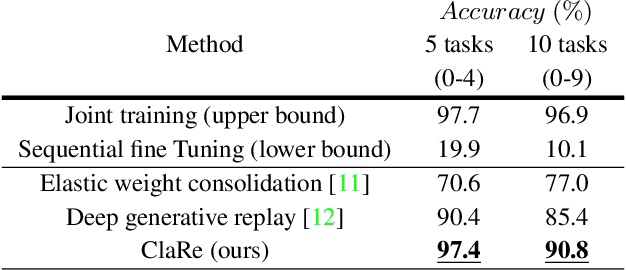
This paper presents a practical and simple yet efficient method to effectively deal with the catastrophic forgetting for Class Incremental Learning (CIL) tasks. CIL tends to learn new concepts perfectly, but not at the expense of performance and accuracy for old data. Learning new knowledge in the absence of data instances from previous classes or even imbalance samples of both old and new classes makes CIL an ongoing challenging problem. These issues can be tackled by storing exemplars belonging to the previous tasks or by utilizing the rehearsal strategy. Inspired by the rehearsal strategy with the approach of using generative models, we propose ClaRe, an efficient solution for CIL by remembering the representations of learned classes in each increment. Taking this approach leads to generating instances with the same distribution of the learned classes. Hence, our model is somehow retrained from the scratch using a new training set including both new and the generated samples. Subsequently, the imbalance data problem is also solved. ClaRe has a better generalization than prior methods thanks to producing diverse instances from the distribution of previously learned classes. We comprehensively evaluate ClaRe on the MNIST benchmark. Results show a very low degradation on accuracy against facing new knowledge over time. Furthermore, contrary to the most proposed solutions, the memory limitation is not problematic any longer which is considered as a consequential issue in this research area.
Comparing Normalization Methods for Limited Batch Size Segmentation Neural Networks
Nov 23, 2020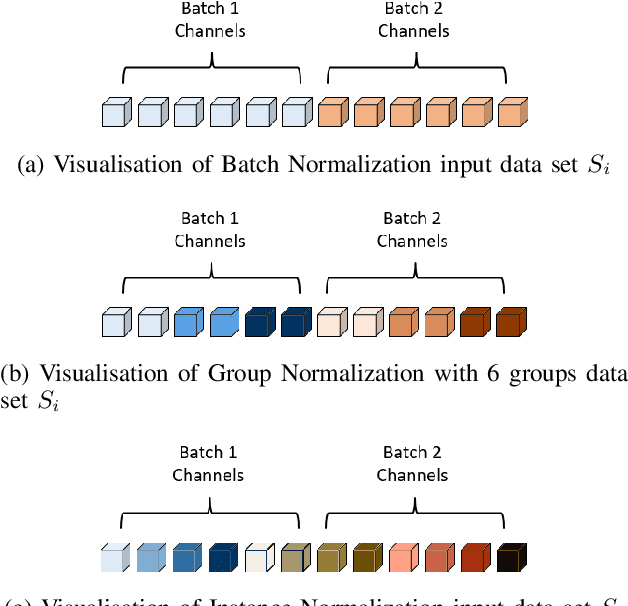

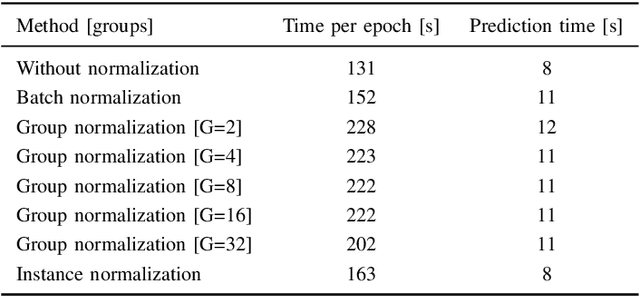
The widespread use of Batch Normalization has enabled training deeper neural networks with more stable and faster results. However, the Batch Normalization works best using large batch size during training and as the state-of-the-art segmentation convolutional neural network architectures are very memory demanding, large batch size is often impossible to achieve on current hardware. We evaluate the alternative normalization methods proposed to solve this issue on a problem of binary spine segmentation from 3D CT scan. Our results show the effectiveness of Instance Normalization in the limited batch size neural network training environment. Out of all the compared methods the Instance Normalization achieved the highest result with Dice coefficient = 0.96 which is comparable to our previous results achieved by deeper network with longer training time. We also show that the Instance Normalization implementation used in this experiment is computational time efficient when compared to the network without any normalization method.
ES-Net: An Efficient Stereo Matching Network
Mar 05, 2021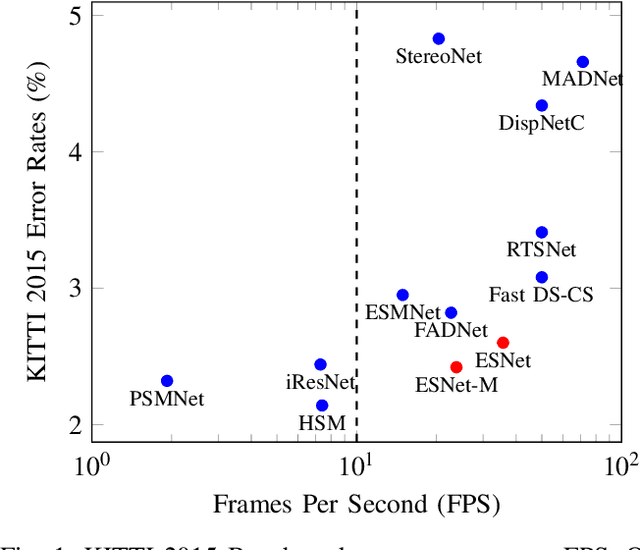
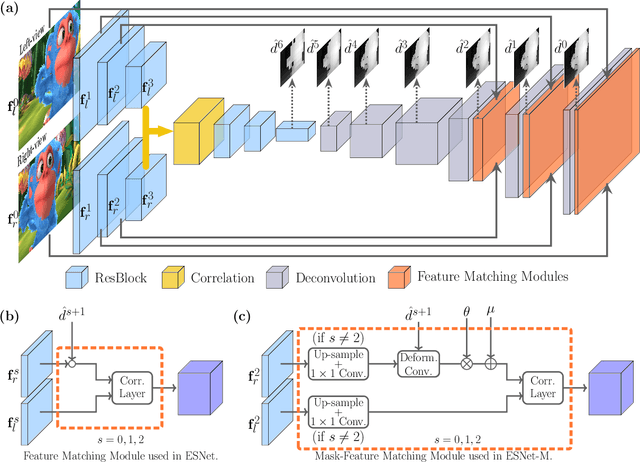

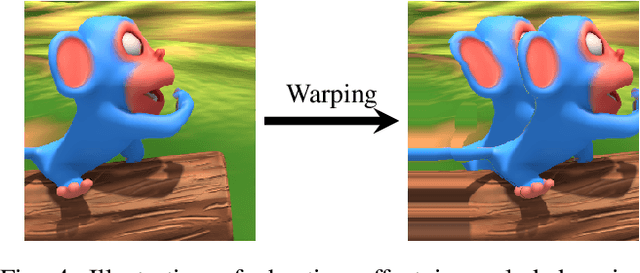
Dense stereo matching with deep neural networks is of great interest to the research community. Existing stereo matching networks typically use slow and computationally expensive 3D convolutions to improve the performance, which is not friendly to real-world applications such as autonomous driving. In this paper, we propose the Efficient Stereo Network (ESNet), which achieves high performance and efficient inference at the same time. ESNet relies only on 2D convolution and computes multi-scale cost volume efficiently using a warping-based method to improve the performance in regions with fine-details. In addition, we address the matching ambiguity issue in the occluded region by proposing ESNet-M, a variant of ESNet that additionally estimates an occlusion mask without supervision. We further improve the network performance by proposing a new training scheme that includes dataset scheduling and unsupervised pre-training. Compared with other low-cost dense stereo depth estimation methods, our proposed approach achieves state-of-the-art performance on the Scene Flow [1], DrivingStereo [2], and KITTI-2015 dataset [3]. Our code will be made available.
MPPI-VS: Sampling-Based Model Predictive Control Strategy for Constrained Image-Based and Position-Based Visual Servoing
Apr 11, 2021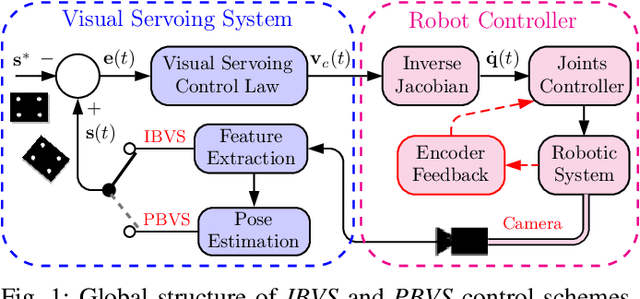
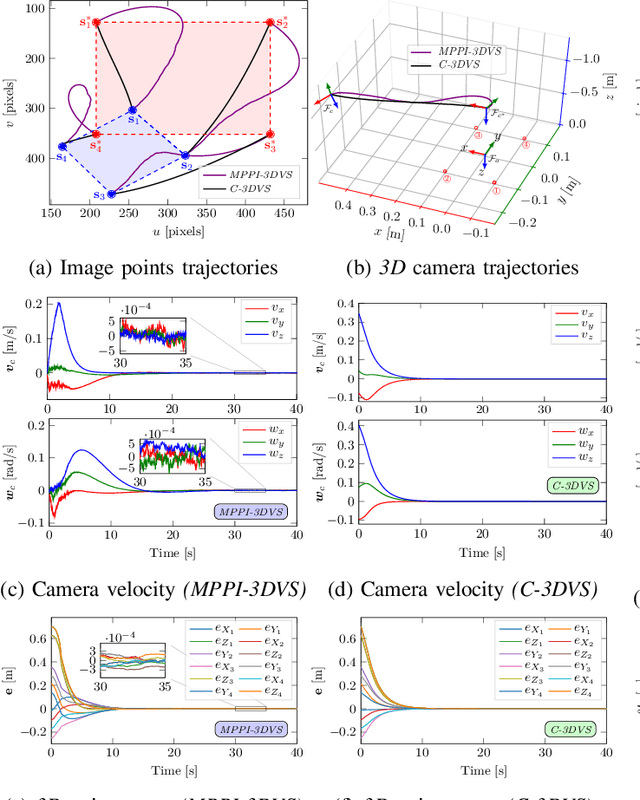
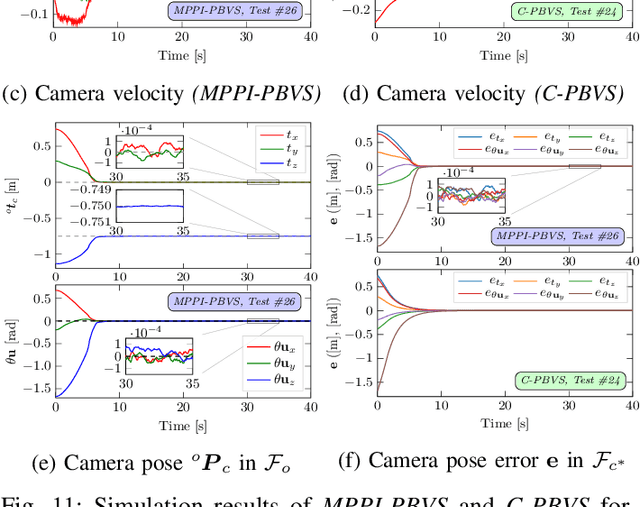
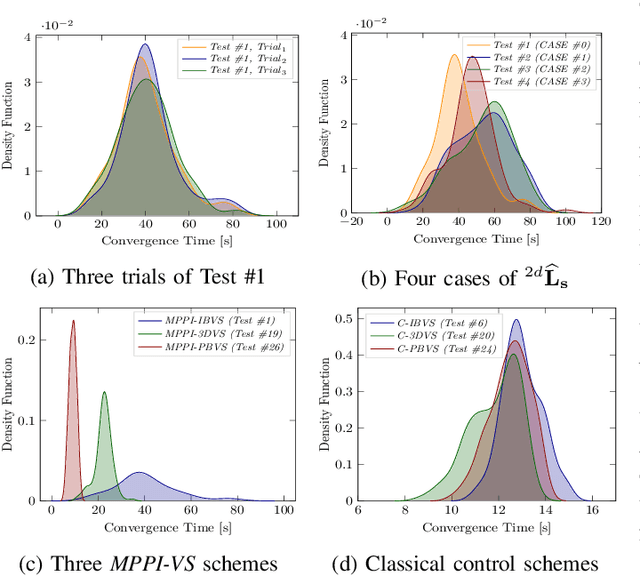
In this paper, we open up new avenues for visual servoing systems built upon the Path Integral (PI) optimal control theory, in which the non-linear partial differential equation (PDE) can be transformed into an expectation over all possible trajectories using the Feynman-Kac (FK) lemma. More precisely, we propose an MPPI-VS control strategy, a real-time and inversion-free control strategy on the basis of sampling-based model predictive control (namely, Model Predictive Path Integral (MPPI) control) algorithm, for both image-based, 3D point, and position-based visual servoing techniques, taking into account the system constraints (such as visibility, 3D, and control constraints) and parametric uncertainties associated with the robot and camera models as well as measurement noise. Contrary to classical visual servoing control schemes, our control strategy directly utilizes the approximation of the interaction matrix, without the need for estimating the interaction matrix inversion or performing the pseudo-inversion. We validate the MPPI-VS control strategy as well as the classical control schemes on a 6-DoF Cartesian robot with an eye-in-hand camera based on the utilization of four points in the image plane as visual features. To better assess and demonstrate the robustness and potential advantages of our proposed control strategy compared to classical schemes, intensive simulations under various operating conditions are carried out and then discussed. The obtained results demonstrate the effectiveness and capability of the proposed scheme in coping easily with the system constraints, as well as its robustness in the presence of large errors in camera parameters and measurements.