 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ColDE: A Depth Estimation Framework for Colonoscopy Reconstruction
Nov 19, 2021

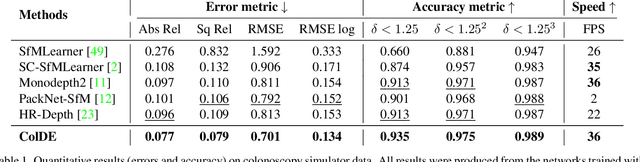
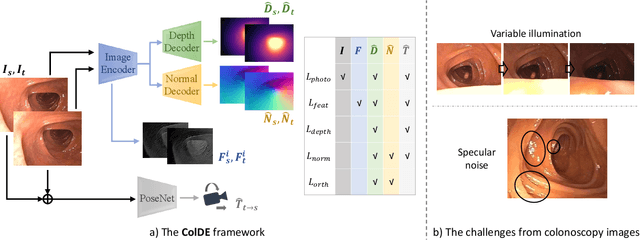
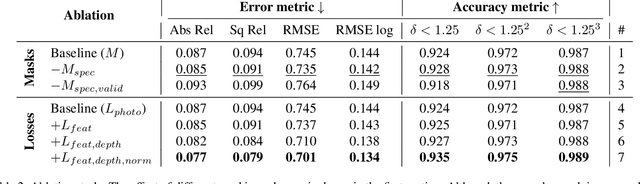
One of the key elements of reconstructing a 3D mesh from a monocular video is generating every frame's depth map. However, in the application of colonoscopy video reconstruction, producing good-quality depth estimation is challenging. Neural networks can be easily fooled by photometric distractions or fail to capture the complex shape of the colon surface, predicting defective shapes that result in broken meshes. Aiming to fundamentally improve the depth estimation quality for colonoscopy 3D reconstruction, in this work we have designed a set of training losses to deal with the special challenges of colonoscopy data. For better training, a set of geometric consistency objectives was developed, using both depth and surface normal information. Also, the classic photometric loss was extended with feature matching to compensate for illumination noise. With the training losses powerful enough, our self-supervised framework named ColDE is able to produce better depth maps of colonoscopy data as compared to the previous work utilizing prior depth knowledge. Used in reconstruction, our network is able to reconstruct good-quality colon meshes in real-time without any post-processing, making it the first to be clinically applicable.
Prosody-TTS: An end-to-end speech synthesis system with prosody control
Oct 06, 2021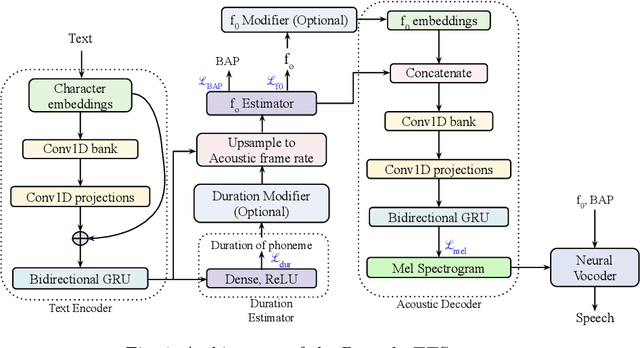
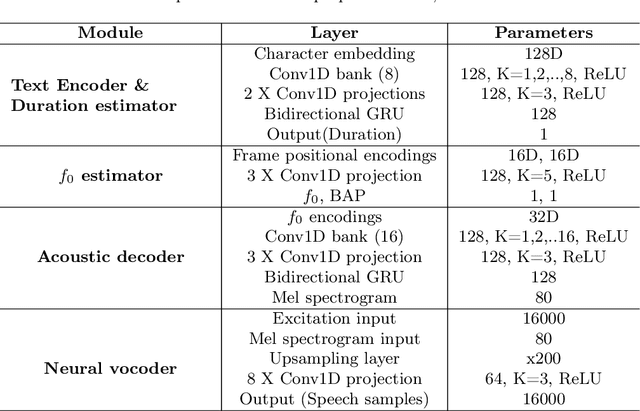
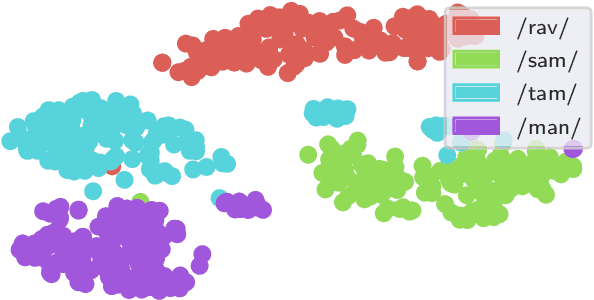
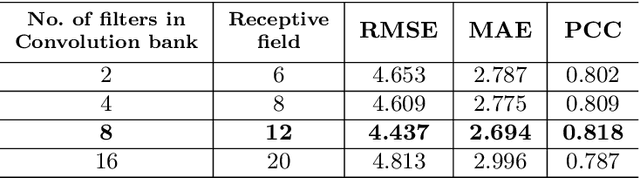
End-to-end text-to-speech synthesis systems achieved immense success in recent times, with improved naturalness and intelligibility. However, the end-to-end models, which primarily depend on the attention-based alignment, do not offer an explicit provision to modify/incorporate the desired prosody while synthesizing the signal. Moreover, the state-of-the-art end-to-end systems use autoregressive models for synthesis, making the prediction sequential. Hence, the inference time and the computational complexity are quite high. This paper proposes Prosody-TTS, an end-to-end speech synthesis model that combines the advantages of statistical parametric models and end-to-end neural network models. It also has a provision to modify or incorporate the desired prosody by controlling the fundamental frequency (f0) and the phone duration. Generating speech samples with appropriate prosody and rhythm helps in improving the naturalness of the synthesized speech. We explicitly model the duration of the phoneme and the f0 to have control over them during the synthesis. The model is trained in an end-to-end fashion to directly generate the speech waveform from the input text, which in turn depends on the auxiliary subtasks of predicting the phoneme duration, f0, and mel spectrogram. Experiments on the Telugu language data of the IndicTTS database show that the proposed Prosody-TTS model achieves state-of-the-art performance with a mean opinion score of 4.08, with a very low inference time.
SECDA: Efficient Hardware/Software Co-Design of FPGA-based DNN Accelerators for Edge Inference
Oct 01, 2021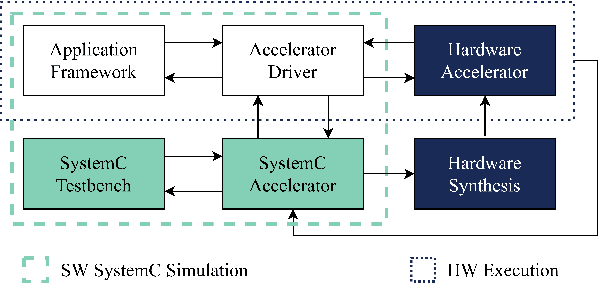
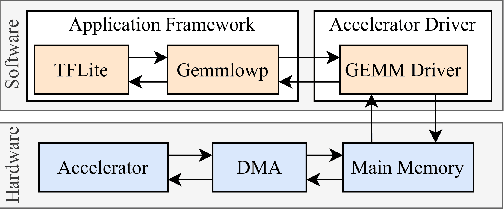
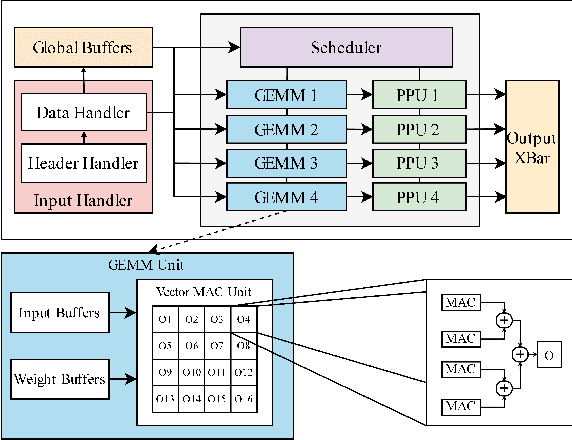
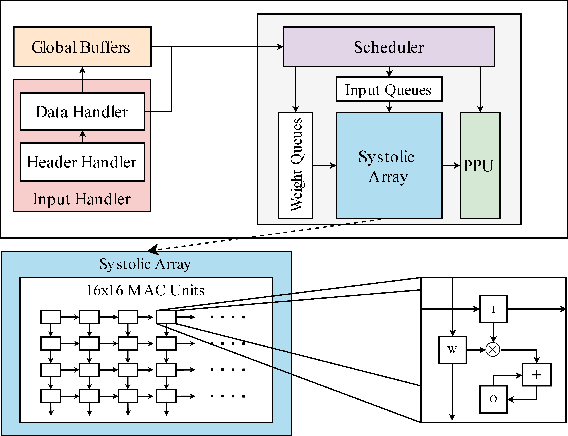
Edge computing devices inherently face tight resource constraints, which is especially apparent when deploying Deep Neural Networks (DNN) with high memory and compute demands. FPGAs are commonly available in edge devices. Since these reconfigurable circuits can achieve higher throughput and lower power consumption than general purpose processors, they are especially well-suited for DNN acceleration. However, existing solutions for designing FPGA-based DNN accelerators for edge devices come with high development overheads, given the cost of repeated FPGA synthesis passes, reimplementation in a Hardware Description Language (HDL) of the simulated design, and accelerator system integration. In this paper we propose SECDA, a new hardware/software co-design methodology to reduce design time of optimized DNN inference accelerators on edge devices with FPGAs. SECDA combines cost-effective SystemC simulation with hardware execution, streamlining design space exploration and the development process via reduced design evaluation time. As a case study, we use SECDA to efficiently develop two different DNN accelerator designs on a PYNQ-Z1 board, a platform that includes an edge FPGA. We quickly and iteratively explore the system's hardware/software stack, while identifying and mitigating performance bottlenecks. We evaluate the two accelerator designs with four common DNN models, achieving an average performance speedup across models of up to 3.5$\times$ with a 2.9$\times$ reduction in energy consumption over CPU-only inference. Our code is available at https://github.com/gicLAB/SECDA
Global Context with Discrete Diffusion in Vector Quantised Modelling for Image Generation
Dec 03, 2021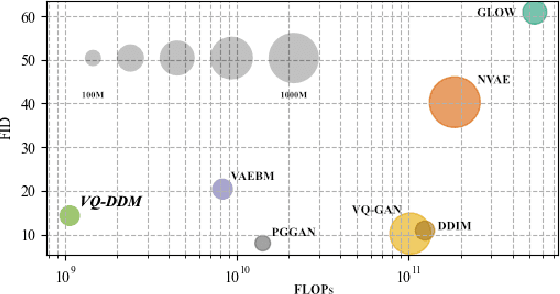
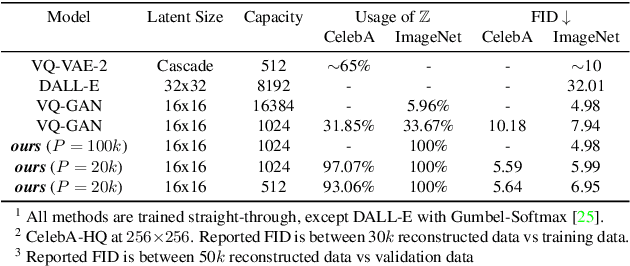
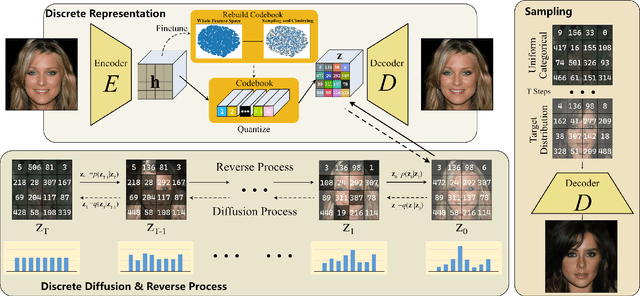
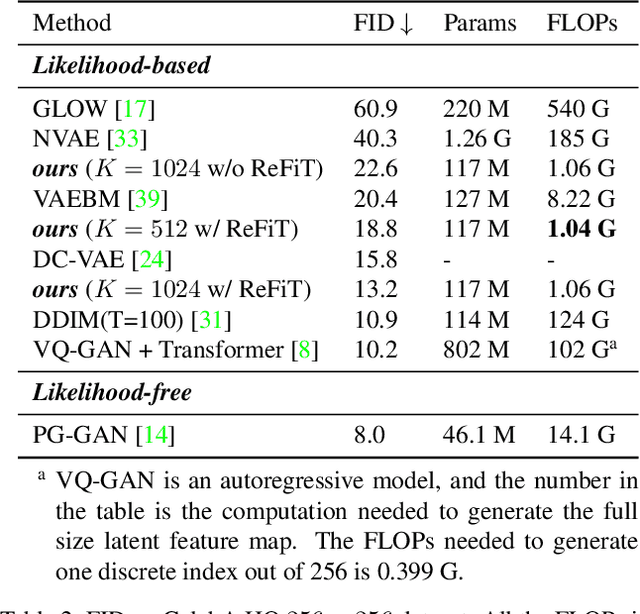
The integration of Vector Quantised Variational AutoEncoder (VQ-VAE) with autoregressive models as generation part has yielded high-quality results on image generation. However, the autoregressive models will strictly follow the progressive scanning order during the sampling phase. This leads the existing VQ series models to hardly escape the trap of lacking global information. Denoising Diffusion Probabilistic Models (DDPM) in the continuous domain have shown a capability to capture the global context, while generating high-quality images. In the discrete state space, some works have demonstrated the potential to perform text generation and low resolution image generation. We show that with the help of a content-rich discrete visual codebook from VQ-VAE, the discrete diffusion model can also generate high fidelity images with global context, which compensates for the deficiency of the classical autoregressive model along pixel space. Meanwhile, the integration of the discrete VAE with the diffusion model resolves the drawback of conventional autoregressive models being oversized, and the diffusion model which demands excessive time in the sampling process when generating images. It is found that the quality of the generated images is heavily dependent on the discrete visual codebook. Extensive experiments demonstrate that the proposed Vector Quantised Discrete Diffusion Model (VQ-DDM) is able to achieve comparable performance to top-tier methods with low complexity. It also demonstrates outstanding advantages over other vectors quantised with autoregressive models in terms of image inpainting tasks without additional training.
Differentially Private Approximate Quantiles
Oct 11, 2021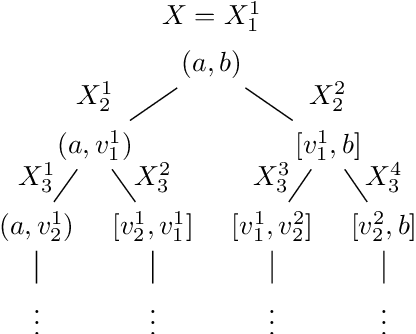
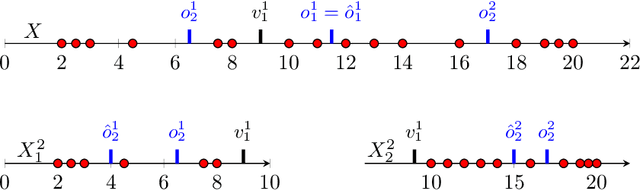
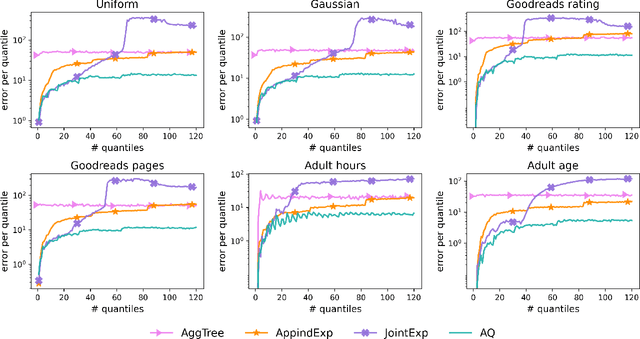
In this work we study the problem of differentially private (DP) quantiles, in which given dataset $X$ and quantiles $q_1, ..., q_m \in [0,1]$, we want to output $m$ quantile estimations which are as close as possible to the true quantiles and preserve DP. We describe a simple recursive DP algorithm, which we call ApproximateQuantiles (AQ), for this task. We give a worst case upper bound on its error, and show that its error is much lower than of previous implementations on several different datasets. Furthermore, it gets this low error while running time two orders of magnitude faster that the best previous implementation.
Automated Detection of Patients in Hospital Video Recordings
Nov 28, 2021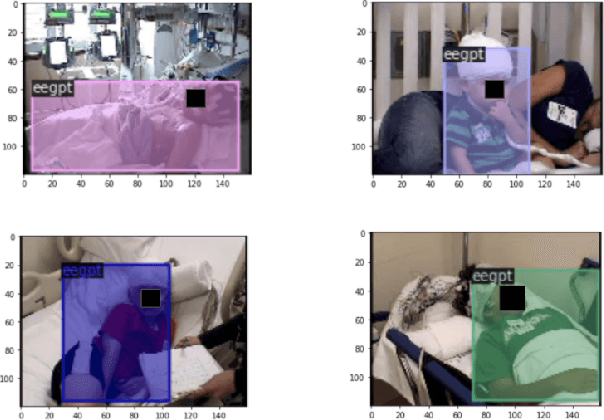
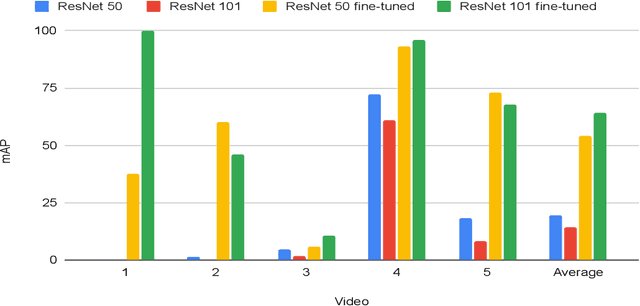
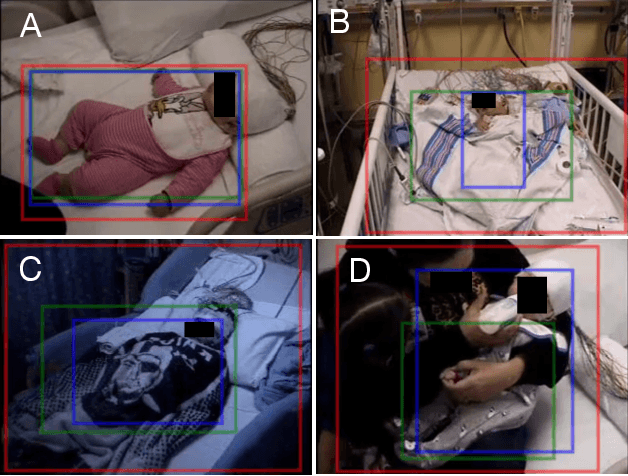
In a clinical setting, epilepsy patients are monitored via video electroencephalogram (EEG) tests. A video EEG records what the patient experiences on videotape while an EEG device records their brainwaves. Currently, there are no existing automated methods for tracking the patient's location during a seizure, and video recordings of hospital patients are substantially different from publicly available video benchmark datasets. For example, the camera angle can be unusual, and patients can be partially covered with bedding sheets and electrode sets. Being able to track a patient in real-time with video EEG would be a promising innovation towards improving the quality of healthcare. Specifically, an automated patient detection system could supplement clinical oversight and reduce the resource-intensive efforts of nurses and doctors who need to continuously monitor patients. We evaluate an ImageNet pre-trained Mask R-CNN, a standard deep learning model for object detection, on the task of patient detection using our own curated dataset of 45 videos of hospital patients. The dataset was aggregated and curated for this work. We show that without fine-tuning, ImageNet pre-trained Mask R-CNN models perform poorly on such data. By fine-tuning the models with a subset of our dataset, we observe a substantial improvement in patient detection performance, with a mean average precision of 0.64. We show that the results vary substantially depending on the video clip.
Evaluating Contrastive Learning on Wearable Timeseries for Downstream Clinical Outcomes
Nov 13, 2021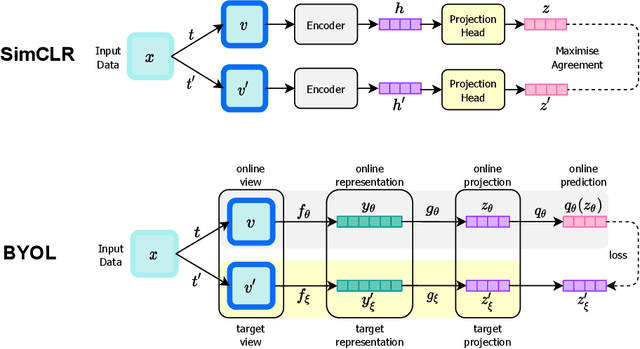
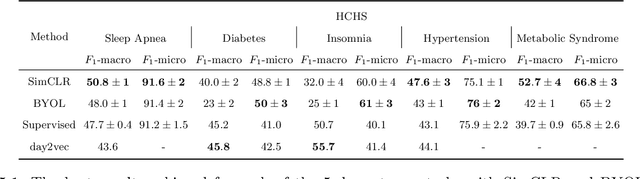
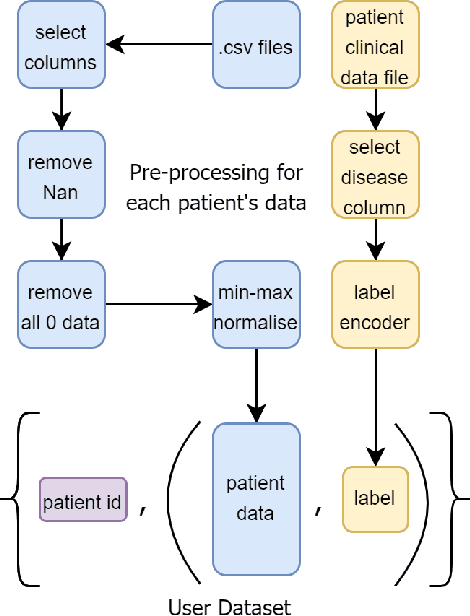
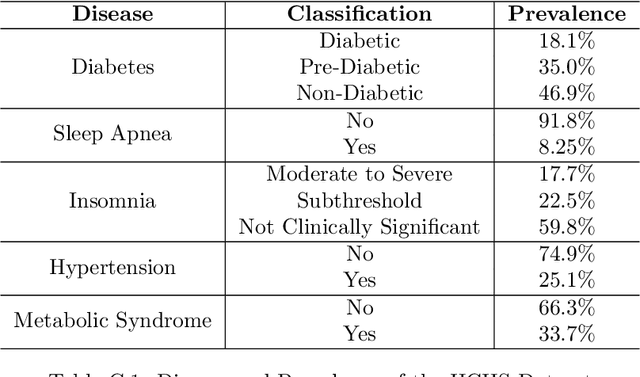
Vast quantities of person-generated health data (wearables) are collected but the process of annotating to feed to machine learning models is impractical. This paper discusses ways in which self-supervised approaches that use contrastive losses, such as SimCLR and BYOL, previously applied to the vision domain, can be applied to high-dimensional health signals for downstream classification tasks of various diseases spanning sleep, heart, and metabolic conditions. To this end, we adapt the data augmentation step and the overall architecture to suit the temporal nature of the data (wearable traces) and evaluate on 5 downstream tasks by comparing other state-of-the-art methods including supervised learning and an adversarial unsupervised representation learning method. We show that SimCLR outperforms the adversarial method and a fully-supervised method in the majority of the downstream evaluation tasks, and that all self-supervised methods outperform the fully-supervised methods. This work provides a comprehensive benchmark for contrastive methods applied to the wearable time-series domain, showing the promise of task-agnostic representations for downstream clinical outcomes.
SL-CycleGAN: Blind Motion Deblurring in Cycles using Sparse Learning
Nov 07, 2021



In this paper, we introduce an end-to-end generative adversarial network (GAN) based on sparse learning for single image blind motion deblurring, which we called SL-CycleGAN. For the first time in blind motion deblurring, we propose a sparse ResNet-block as a combination of sparse convolution layers and a trainable spatial pooler k-winner based on HTM (Hierarchical Temporal Memory) to replace non-linearity such as ReLU in the ResNet-block of SL-CycleGAN generators. Furthermore, unlike many state-of-the-art GAN-based motion deblurring methods that treat motion deblurring as a linear end-to-end process, we take our inspiration from the domain-to-domain translation ability of CycleGAN, and we show that image deblurring can be cycle-consistent while achieving the best qualitative results. Finally, we perform extensive experiments on popular image benchmarks both qualitatively and quantitatively and achieve the record-breaking PSNR of 38.087 dB on GoPro dataset, which is 5.377 dB better than the most recent deblurring method.
Time series and machine learning to forecast the water quality from satellite data
Mar 16, 2020
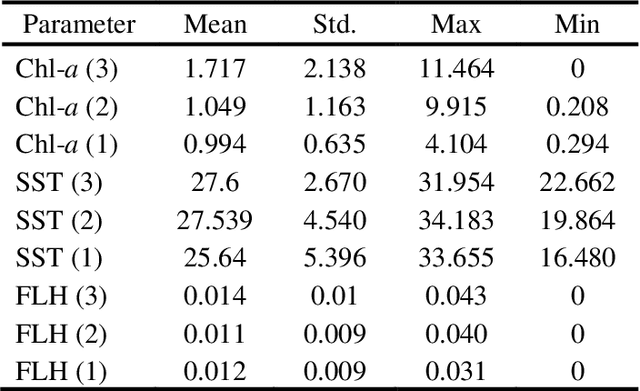
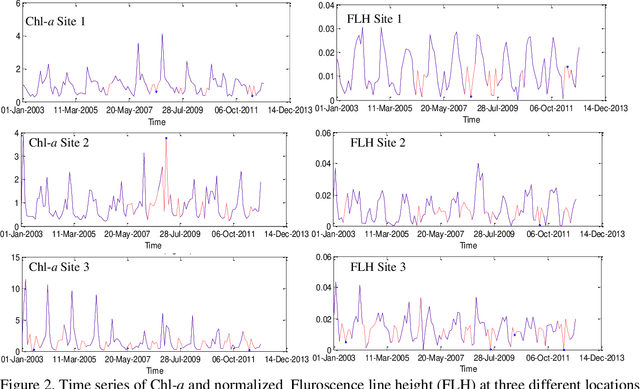
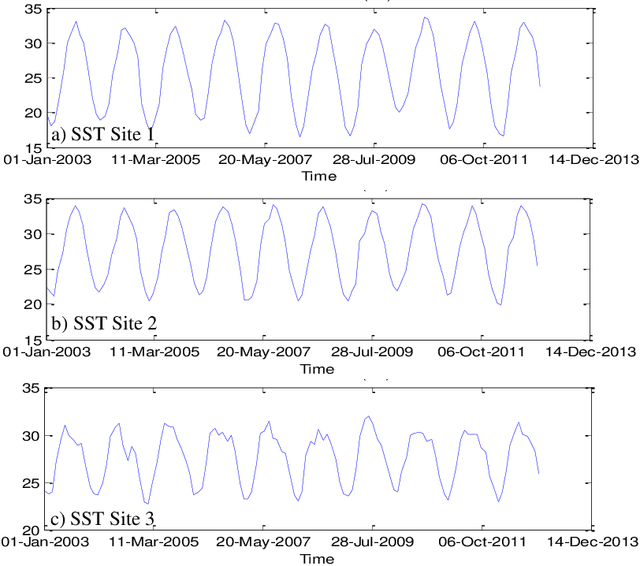
Managing the quality of water for present and future generations of coastal regions should be a central concern of both citizens and public officials. Remote sensing can contribute to the management and monitoring of coastal water and pollutants. Algal blooms are a coastal pollutant that is a cause of concern. Many satellite data, such as MODIS, have been used to generate water-quality products to detect the blooms such as chlorophyll a (Chl-a), a photosynthesis index called fluorescence line height (FLH), and sea surface temperature (SST). It is important to characterize the spatial and temporal variations of these water quality products by using the mathematical models of these products. However, for monitoring, pollution control boards will need nowcasts and forecasts of any pollution. Therefore, we aim to predict the future values of the MODIS Chl-a, FLH, and SST of the water. This will not be limited to one type of water but, rather, will cover different types of water varying in depth and turbidity. This is very significant because the temporal trend of Chl-a, FLH, and SST is dependent on the geospatial and water properties. For this purpose, we will decompose the time series of each pixel into several components: trend, intra-annual variations, seasonal cycle, and stochastic stationary. We explore three such time series machine learning models that can characterize the non-stationary time series data and predict future values, including the Seasonal ARIMA (Auto Regressive Integrated Moving Average) (SARIMA), regression, and neural network. The results indicate that all these methods are effective at modelling Chl-a, FLH, and SST time series and predicting the values reasonably well. However, regression and neural network are found to be the best at predicting Chl-a in all types of water (turbid and shallow). Meanwhile, the SARIMA model provides the best prediction of FLH and SST.
Continuous Homeostatic Reinforcement Learning for Self-Regulated Autonomous Agents
Sep 14, 2021
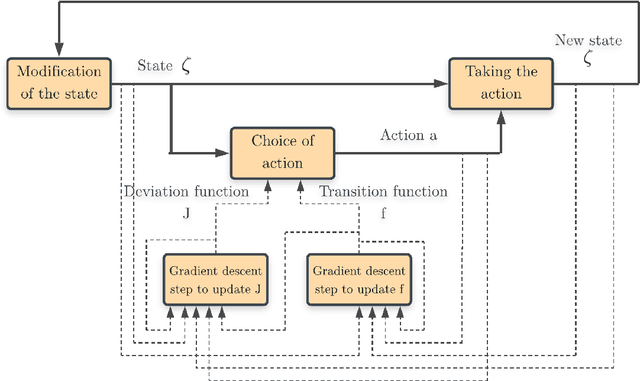
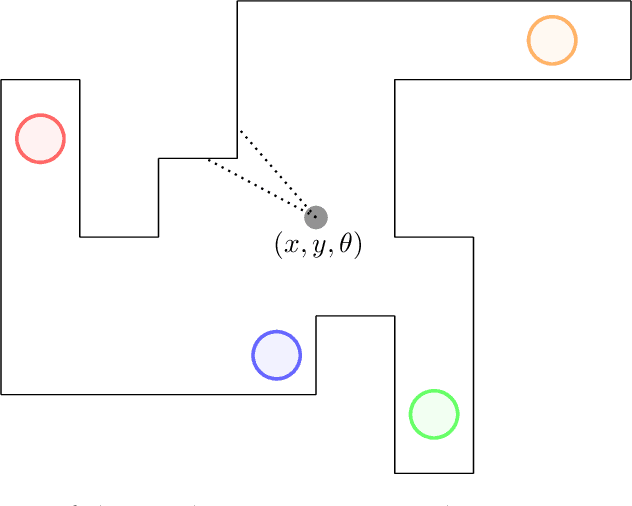

Homeostasis is a prevalent process by which living beings maintain their internal milieu around optimal levels. Multiple lines of evidence suggest that living beings learn to act to predicatively ensure homeostasis (allostasis). A classical theory for such regulation is drive reduction, where a function of the difference between the current and the optimal internal state. The recently introduced homeostatic regulated reinforcement learning theory (HRRL), by defining within the framework of reinforcement learning a reward function based on the internal state of the agent, makes the link between the theories of drive reduction and reinforcement learning. The HRRL makes it possible to explain multiple eating disorders. However, the lack of continuous change in the internal state of the agent with the discrete-time modeling has been so far a key shortcoming of the HRRL theory. Here, we propose an extension of the homeostatic reinforcement learning theory to a continuous environment in space and time, while maintaining the validity of the theoretical results and the behaviors explained by the model in discrete time. Inspired by the self-regulating mechanisms abundantly present in biology, we also introduce a model for the dynamics of the agent internal state, requiring the agent to continuously take actions to maintain homeostasis. Based on the Hamilton-Jacobi-Bellman equation and function approximation with neural networks, we derive a numerical scheme allowing the agent to learn directly how its internal mechanism works, and to choose appropriate action policies via reinforcement learning and an appropriate exploration of the environment. Our numerical experiments show that the agent does indeed learn to behave in a way that is beneficial to its survival in the environment, making our framework promising for modeling animal dynamics and decision-making.