 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Revisiting Deep Subspace Alignment for Unsupervised Domain Adaptation
Jan 05, 2022
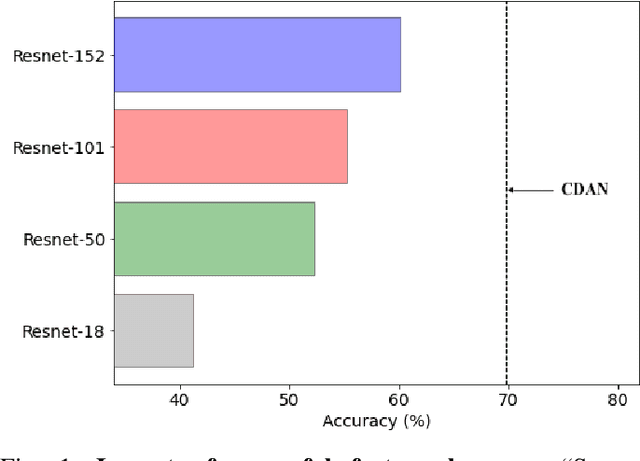
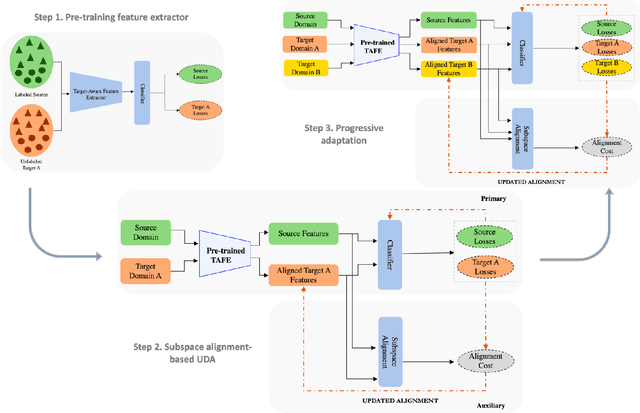
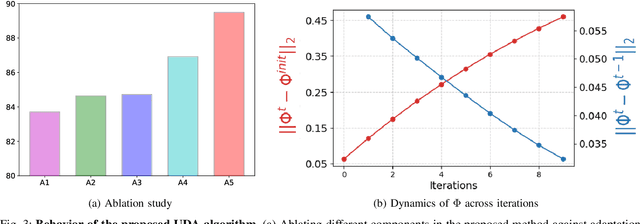
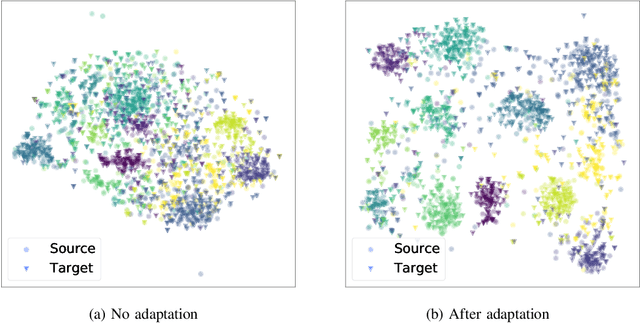
Unsupervised domain adaptation (UDA) aims to transfer and adapt knowledge from a labeled source domain to an unlabeled target domain. Traditionally, subspace-based methods form an important class of solutions to this problem. Despite their mathematical elegance and tractability, these methods are often found to be ineffective at producing domain-invariant features with complex, real-world datasets. Motivated by the recent advances in representation learning with deep networks, this paper revisits the use of subspace alignment for UDA and proposes a novel adaptation algorithm that consistently leads to improved generalization. In contrast to existing adversarial training-based DA methods, our approach isolates feature learning and distribution alignment steps, and utilizes a primary-auxiliary optimization strategy to effectively balance the objectives of domain invariance and model fidelity. While providing a significant reduction in target data and computational requirements, our subspace-based DA performs competitively and sometimes even outperforms state-of-the-art approaches on several standard UDA benchmarks. Furthermore, subspace alignment leads to intrinsically well-regularized models that demonstrate strong generalization even in the challenging partial DA setting. Finally, the design of our UDA framework inherently supports progressive adaptation to new target domains at test-time, without requiring retraining of the model from scratch. In summary, powered by powerful feature learners and an effective optimization strategy, we establish subspace-based DA as a highly effective approach for visual recognition.
Dyadic Sex Composition and Task Classification Using fNIRS Hyperscanning Data
Dec 07, 2021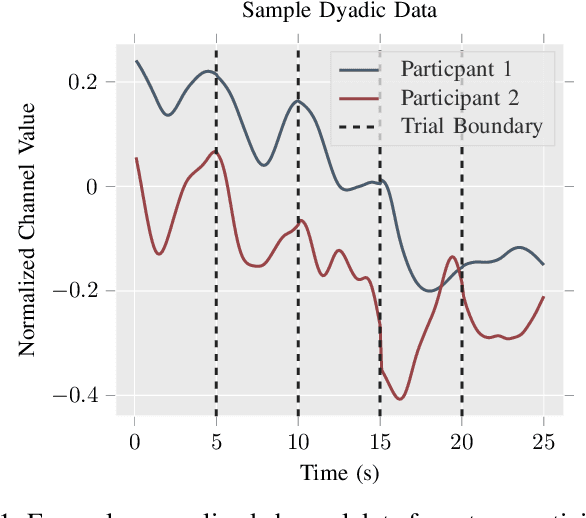
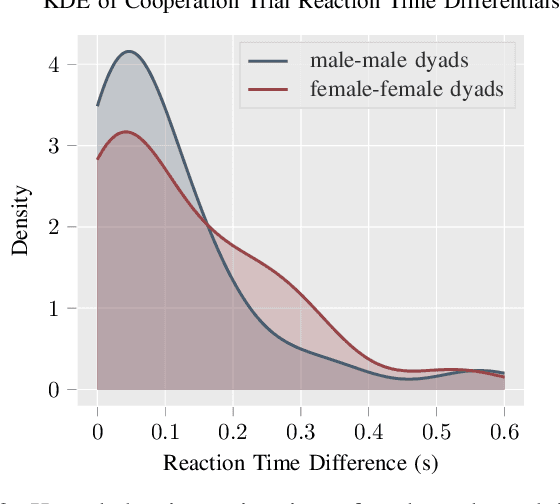
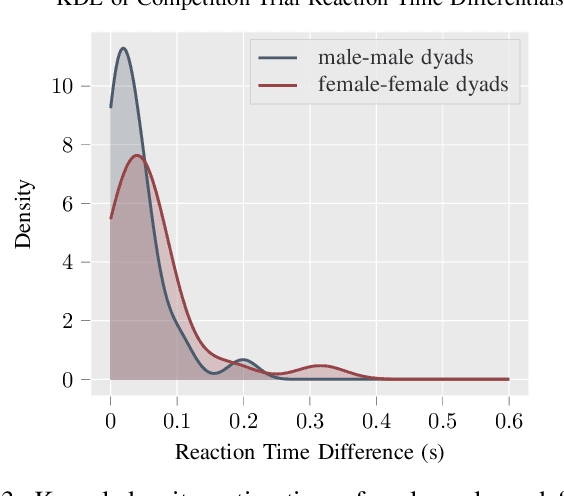
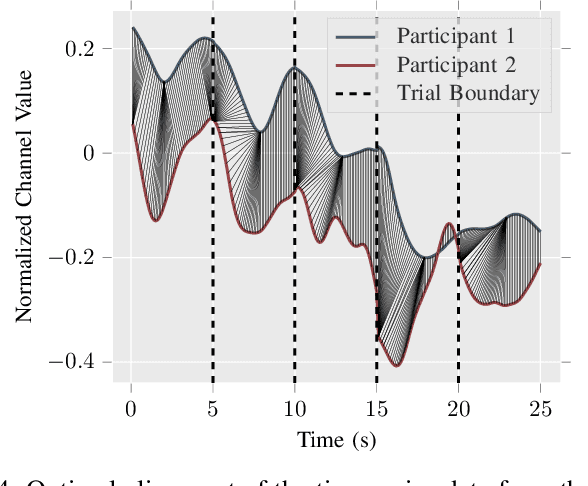
Hyperscanning with functional near-infrared spectroscopy (fNIRS) is an emerging neuroimaging application that measures the nuanced neural signatures underlying social interactions. Researchers have assessed the effect of sex and task type (e.g., cooperation versus competition) on inter-brain coherence during human-to-human interactions. However, no work has yet used deep learning-based approaches to extract insights into sex and task-based differences in an fNIRS hyperscanning context. This work proposes a convolutional neural network-based approach to dyadic sex composition and task classification for an extensive hyperscanning dataset with $N = 222$ participants. Inter-brain signal similarity computed using dynamic time warping is used as the input data. The proposed approach achieves a maximum classification accuracy of greater than $80$ percent, thereby providing a new avenue for exploring and understanding complex brain behavior.
Accelerating Deep Learning Classification with Error-controlled Approximate-key Caching
Dec 13, 2021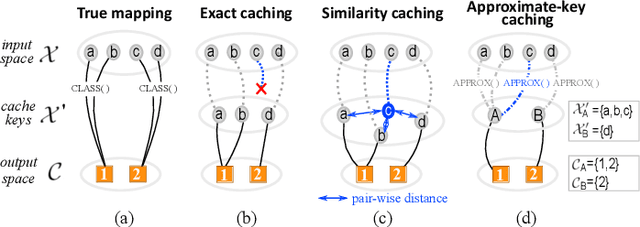
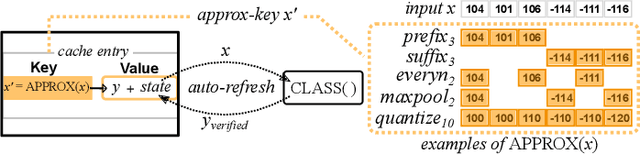


While Deep Learning (DL) technologies are a promising tool to solve networking problems that map to classification tasks, their computational complexity is still too high with respect to real-time traffic measurements requirements. To reduce the DL inference cost, we propose a novel caching paradigm, that we named approximate-key caching, which returns approximate results for lookups of selected input based on cached DL inference results. While approximate cache hits alleviate DL inference workload and increase the system throughput, they however introduce an approximation error. As such, we couple approximate-key caching with an error-correction principled algorithm, that we named auto-refresh. We analytically model our caching system performance for classic LRU and ideal caches, we perform a trace-driven evaluation of the expected performance, and we compare the benefits of our proposed approach with the state-of-the-art similarity caching -- testifying the practical interest of our proposal.
An unsupervised framework for tracing textual sources of moral change
Sep 01, 2021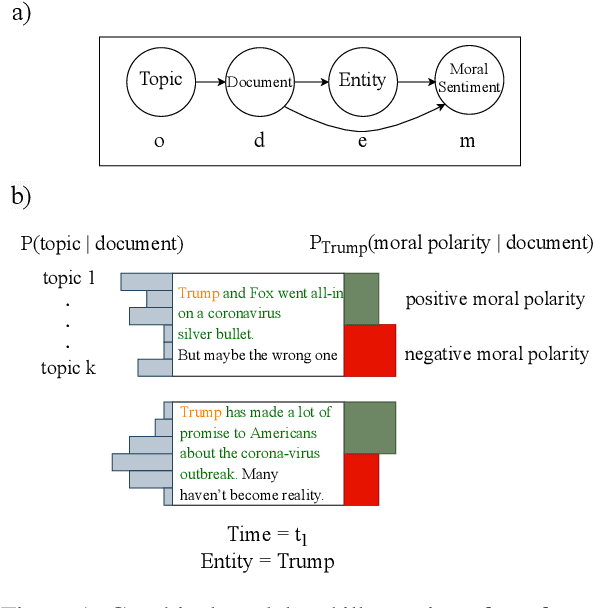
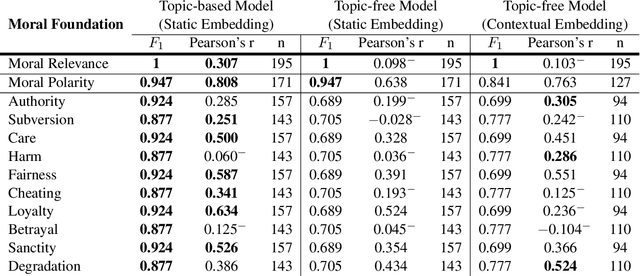
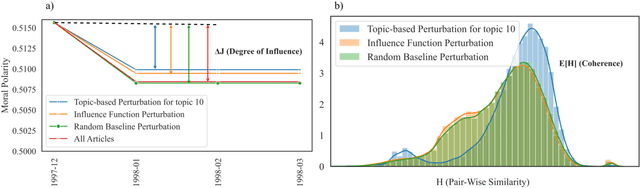
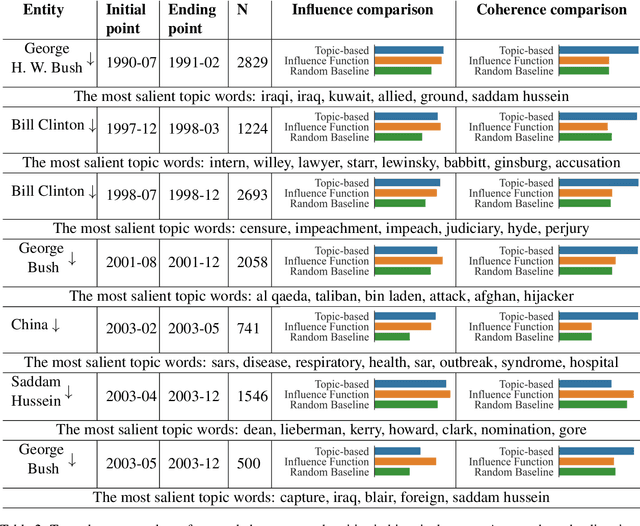
Morality plays an important role in social well-being, but people's moral perception is not stable and changes over time. Recent advances in natural language processing have shown that text is an effective medium for informing moral change, but no attempt has been made to quantify the origins of these changes. We present a novel unsupervised framework for tracing textual sources of moral change toward entities through time. We characterize moral change with probabilistic topical distributions and infer the source text that exerts prominent influence on the moral time course. We evaluate our framework on a diverse set of data ranging from social media to news articles. We show that our framework not only captures fine-grained human moral judgments, but also identifies coherent source topics of moral change triggered by historical events. We apply our methodology to analyze the news in the COVID-19 pandemic and demonstrate its utility in identifying sources of moral change in high-impact and real-time social events.
On the Uncertain Single-View Depths in Endoscopies
Dec 16, 2021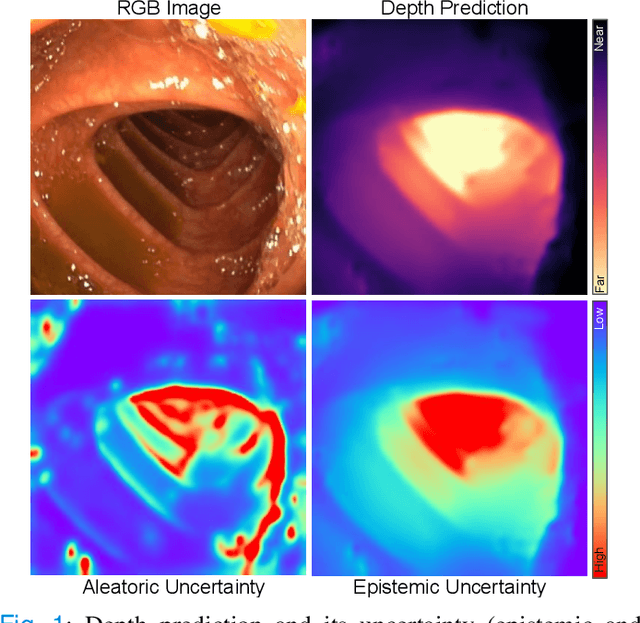
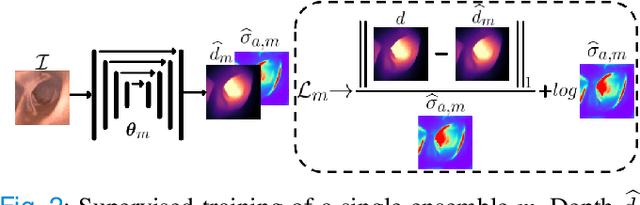
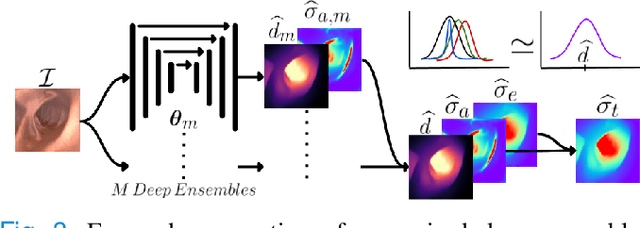
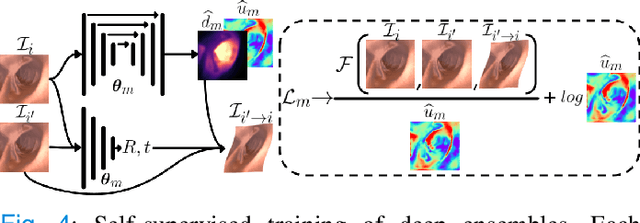
Estimating depth from endoscopic images is a pre-requisite for a wide set of AI-assisted technologies, namely accurate localization, measurement of tumors, or identification of non-inspected areas. As the domain specificity of colonoscopies -- a deformable low-texture environment with fluids, poor lighting conditions and abrupt sensor motions -- pose challenges to multi-view approaches, single-view depth learning stands out as a promising line of research. In this paper, we explore for the first time Bayesian deep networks for single-view depth estimation in colonoscopies. Their uncertainty quantification offers great potential for such a critical application area. Our specific contribution is two-fold: 1) an exhaustive analysis of Bayesian deep networks for depth estimation in three different datasets, highlighting challenges and conclusions regarding synthetic-to-real domain changes and supervised vs. self-supervised methods; and 2) a novel teacher-student approach to deep depth learning that takes into account the teacher uncertainty.
Real-Time Deep Learning Approach to Visual Servo Control and Grasp Detection for Autonomous Robotic Manipulation
Oct 13, 2020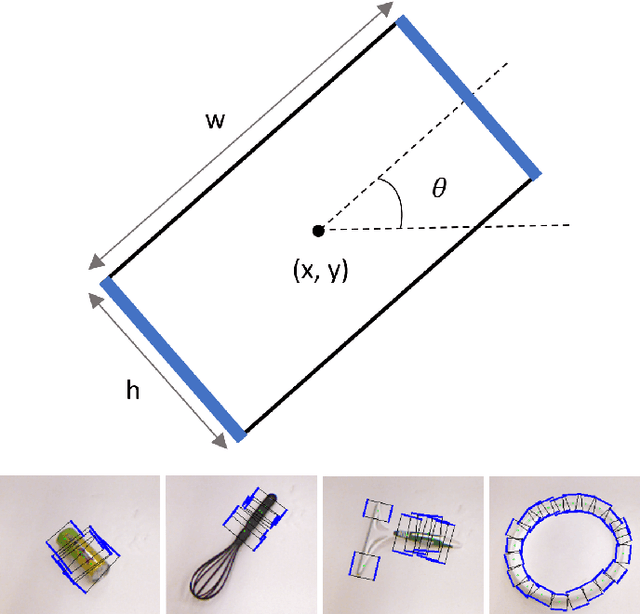
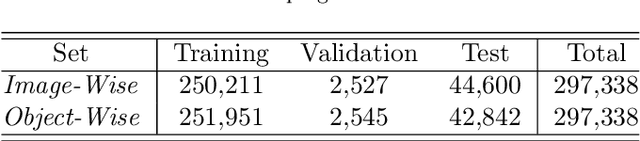
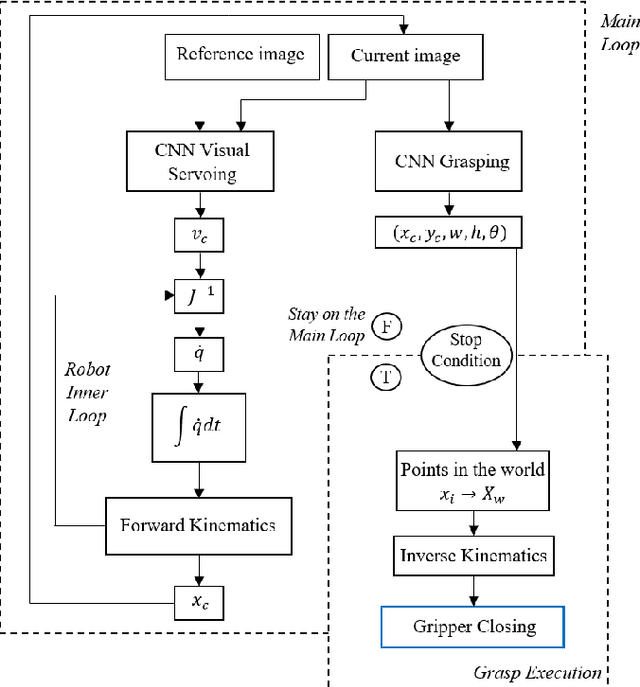
In order to explore robotic grasping in unstructured and dynamic environments, this work addresses the visual perception phase involved in the task. This phase involves the processing of visual data to obtain the location of the object to be grasped, its pose and the points at which the robot`s grippers must make contact to ensure a stable grasp. For this, the Cornell Grasping dataset is used to train a convolutional neural network that, having an image of the robot`s workspace, with a certain object, is able to predict a grasp rectangle that symbolizes the position, orientation and opening of the robot`s grippers before its closing. In addition to this network, which runs in real-time, another one is designed to deal with situations in which the object moves in the environment. Therefore, the second network is trained to perform a visual servo control, ensuring that the object remains in the robot`s field of view. This network predicts the proportional values of the linear and angular velocities that the camera must have so that the object is always in the image processed by the grasp network. The dataset used for training was automatically generated by a Kinova Gen3 manipulator. The robot is also used to evaluate the applicability in real-time and obtain practical results from the designed algorithms. Moreover, the offline results obtained through validation sets are also analyzed and discussed regarding their efficiency and processing speed. The developed controller was able to achieve a millimeter accuracy in the final position considering a target object seen for the first time. To the best of our knowledge, we have not found in the literature other works that achieve such precision with a controller learned from scratch. Thus, this work presents a new system for autonomous robotic manipulation with high processing speed and the ability to generalize to several different objects.
A Sensitivity Analysis of the MSMARCO Passage Collection
Dec 06, 2021

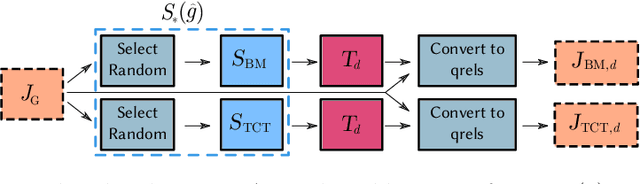
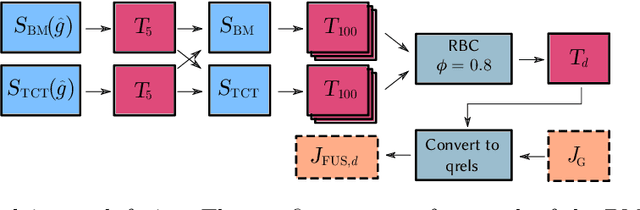
The recent MSMARCO passage retrieval collection has allowed researchers to develop highly tuned retrieval systems. One aspect of this data set that makes it distinctive compared to traditional corpora is that most of the topics only have a single answer passage marked relevant. Here we carry out a "what if" sensitivity study, asking whether a set of systems would still have the same relative performance if more passages per topic were deemed to be "relevant", exploring several mechanisms for identifying sets of passages to be so categorized. Our results show that, in general, while run scores can vary markedly if additional plausible passages are presumed to be relevant, the derived system ordering is relatively insensitive to additional relevance, providing support for the methodology that was used at the time the MSMARCO passage collection was created.
DeDUCE: Generating Counterfactual Explanations Efficiently
Nov 29, 2021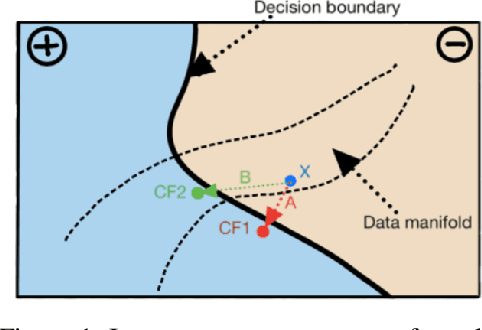

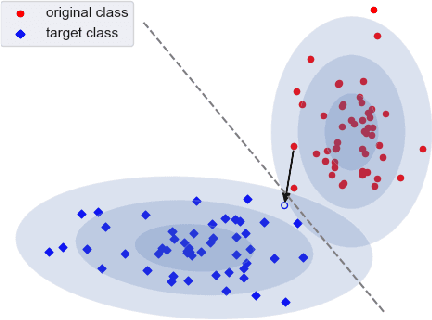

When an image classifier outputs a wrong class label, it can be helpful to see what changes in the image would lead to a correct classification. This is the aim of algorithms generating counterfactual explanations. However, there is no easily scalable method to generate such counterfactuals. We develop a new algorithm providing counterfactual explanations for large image classifiers trained with spectral normalisation at low computational cost. We empirically compare this algorithm against baselines from the literature; our novel algorithm consistently finds counterfactuals that are much closer to the original inputs. At the same time, the realism of these counterfactuals is comparable to the baselines. The code for all experiments is available at https://github.com/benedikthoeltgen/DeDUCE.
Usability and Aesthetics: Better Together for Automated Repair of Web Pages
Jan 01, 2022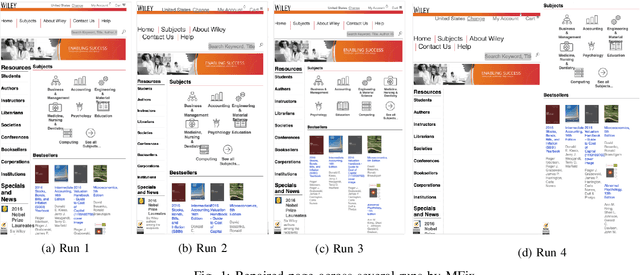
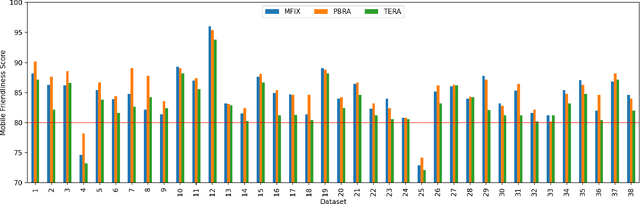
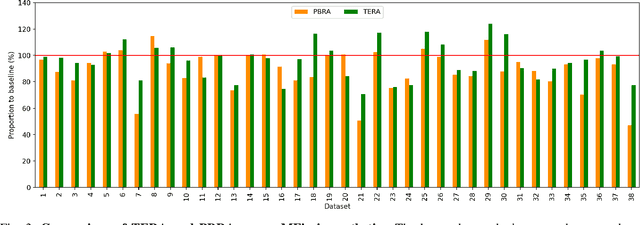
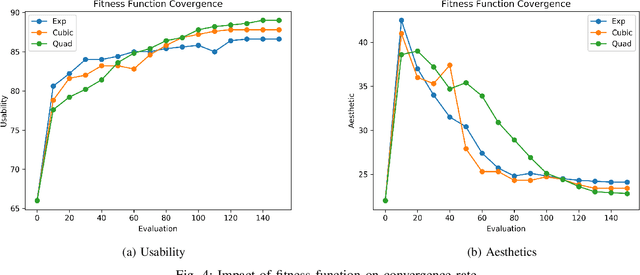
With the recent explosive growth of mobile devices such as smartphones or tablets, guaranteeing consistent web appearance across all environments has become a significant problem. This happens simply because it is hard to keep track of the web appearance on different sizes and types of devices that render the web pages. Therefore, fixing the inconsistent appearance of web pages can be difficult, and the cost incurred can be huge, e.g., poor user experience and financial loss due to it. Recently, automated web repair techniques have been proposed to automatically resolve inconsistent web page appearance, focusing on improving usability. However, generated patches tend to disrupt the webpage's layout, rendering the repaired webpage aesthetically unpleasing, e.g., distorted images or misalignment of components. In this paper, we propose an automated repair approach for web pages based on meta-heuristic algorithms that can assure both usability and aesthetics. The key novelty that empowers our approach is a novel fitness function that allows us to optimistically evolve buggy web pages to find the best solution that optimizes both usability and aesthetics at the same time. Empirical evaluations show that our approach is able to successfully resolve mobile-friendly problems in 94% of the evaluation subjects, significantly outperforming state-of-the-art baseline techniques in terms of both usability and aesthetics.
* Accepted to ISSRE 2021, Research Track
Chronological Causal Bandits
Dec 03, 2021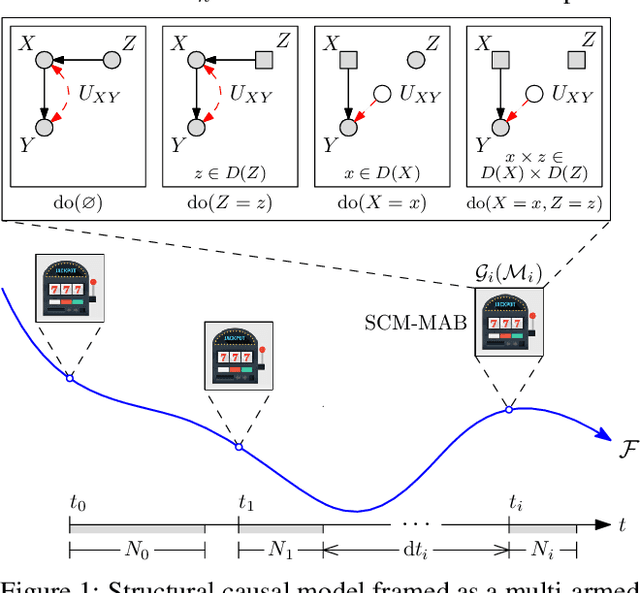
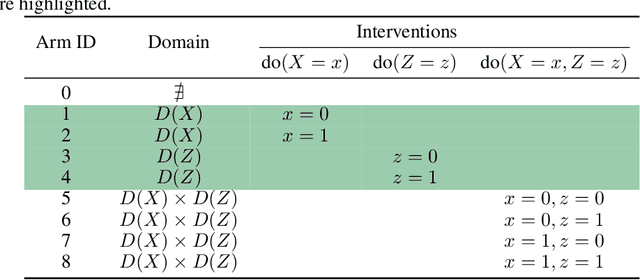
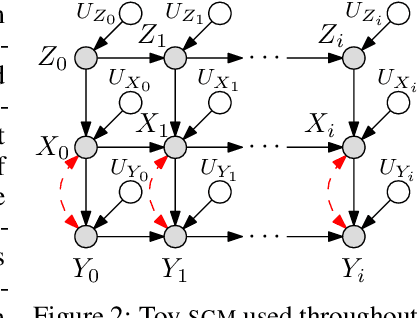

This paper studies an instance of the multi-armed bandit (MAB) problem, specifically where several causal MABs operate chronologically in the same dynamical system. Practically the reward distribution of each bandit is governed by the same non-trivial dependence structure, which is a dynamic causal model. Dynamic because we allow for each causal MAB to depend on the preceding MAB and in doing so are able to transfer information between agents. Our contribution, the Chronological Causal Bandit (CCB), is useful in discrete decision-making settings where the causal effects are changing across time and can be informed by earlier interventions in the same system. In this paper, we present some early findings of the CCB as demonstrated on a toy problem.