 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TEASER: Early and Accurate Time Series Classification
Aug 16, 2019
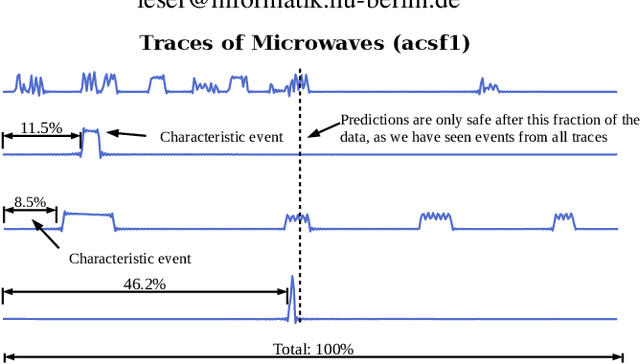
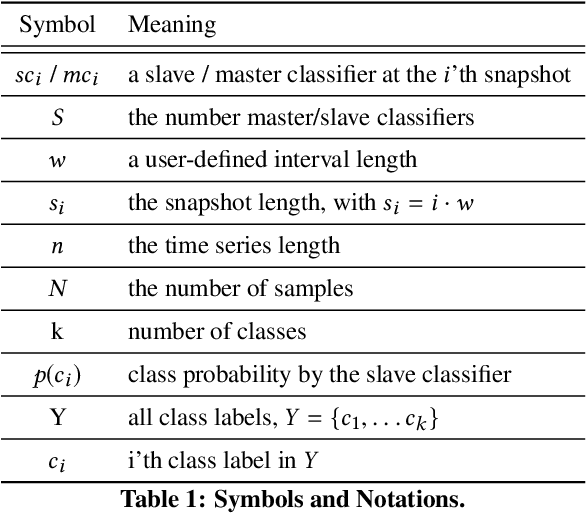
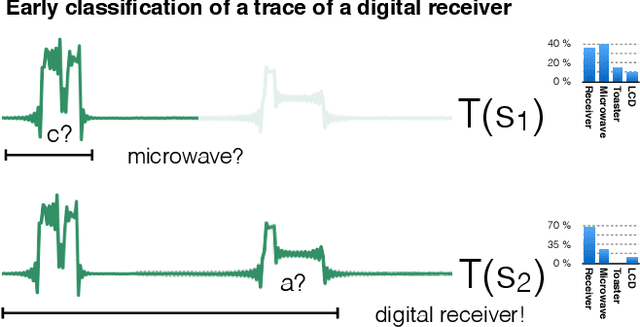

Early time series classification (eTSC) is the problem of classifying a time series after as few measurements as possible with the highest possible accuracy. The most critical issue of any eTSC method is to decide when enough data of a time series has been seen to take a decision: Waiting for more data points usually makes the classification problem easier but delays the time in which a classification is made; in contrast, earlier classification has to cope with less input data, often leading to inferior accuracy. The state-of-the-art eTSC methods compute a fixed optimal decision time assuming that every times series has the same defined start time (like turning on a machine). However, in many real-life applications measurements start at arbitrary times (like measuring heartbeats of a patient), implying that the best time for taking a decision varies heavily between time series. We present TEASER, a novel algorithm that models eTSC as a two two-tier classification problem: In the first tier, a classifier periodically assesses the incoming time series to compute class probabilities. However, these class probabilities are only used as output label if a second-tier classifier decides that the predicted label is reliable enough, which can happen after a different number of measurements. In an evaluation using 45 benchmark datasets, TEASER is two to three times earlier at predictions than its competitors while reaching the same or an even higher classification accuracy. We further show TEASER's superior performance using real-life use cases, namely energy monitoring, and gait detection.
Damping Identification of an Operational Offshore Wind Turbine using Enhanced Kalman filter-based Subspace Identification
Jan 19, 2022

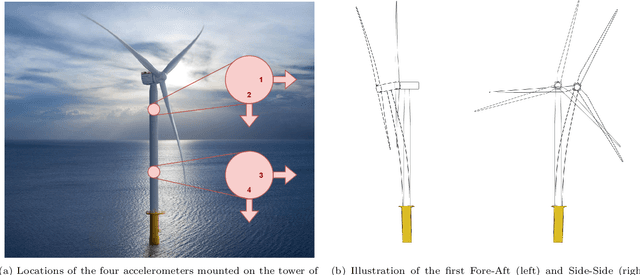

Operational Modal Analysis (OMA) provides essential insights into the structural dynamics of an Offshore Wind Turbine (OWT). In these dynamics, damping is considered an especially important parameter as it governs the magnitude of the response at the natural frequencies. Violation of the stationary white noise excitation requirement of classical OMA algorithms has troubled the identification of operational OWTs due to harmonic excitation caused by rotor rotation. Recently, a novel algorithm was presented that mitigates harmonics by estimating a harmonic subsignal using a Kalman filter and orthogonally removing this signal from the response signal, after which the Stochastic Subspace Identification algorithm is used to identify the system. Although promising results are achieved using this novel algorithm, several shortcomings are still present like the numerical instability of the conventional Kalman filter and the inability to use large or multiple datasets. This paper addresses these shortcomings and applies an enhanced version to a multi-megawatt operational OWT using an economical sensor setup with two accelerometer levels. The algorithm yielded excellent results for the first three tower bending modes with low variance. A comparison of these results against the established time-domain harmonics-mitigating algorithm, Modified LSCE, and the frequency-domain PolyMAX algorithm demonstrated strong agreement in results.
Variational Autoencoders with a Structural Similarity Loss in Time of Flight MRAs
Jan 20, 2021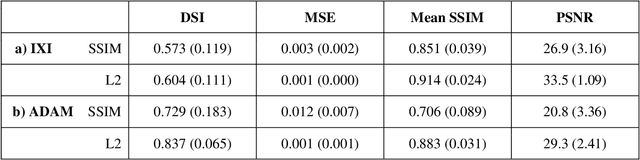
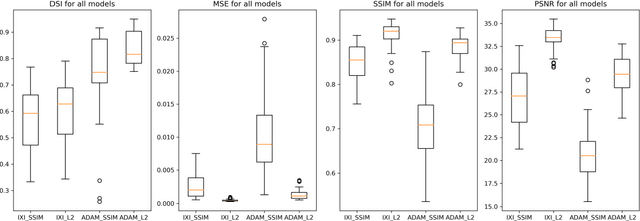
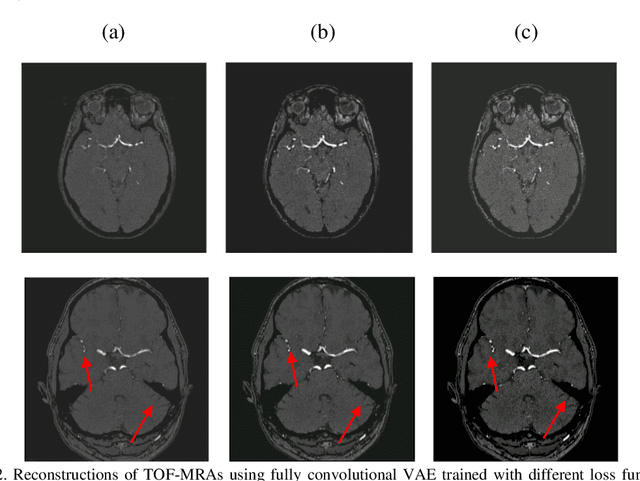
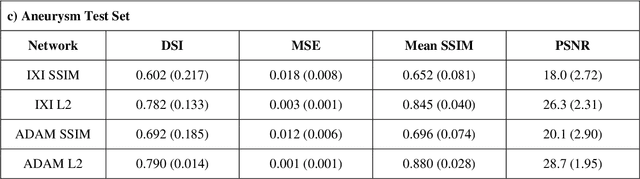
Time-of-Flight Magnetic Resonance Angiographs (TOF-MRAs) enable visualization and analysis of cerebral arteries. This analysis may indicate normal variation of the configuration of the cerebrovascular system or vessel abnormalities, such as aneurysms. A model would be useful to represent normal cerebrovascular structure and variabilities in a healthy population and to differentiate from abnormalities. Current anomaly detection using autoencoding convolutional neural networks usually use a voxelwise mean-error for optimization. We propose optimizing a variational-autoencoder (VAE) with structural similarity loss (SSIM) for TOF-MRA reconstruction. A patch-trained 2D fully-convolutional VAE was optimized for TOF-MRA reconstruction by comparing vessel segmentations of original and reconstructed MRAs. The method was trained and tested on two datasets: the IXI dataset, and a subset from the ADAM challenge. Both trained networks were tested on a dataset including subjects with aneurysms. We compared VAE optimization with L2-loss and SSIM-loss. Performance was evaluated between original and reconstructed MRAs using mean square error, mean-SSIM, peak-signal-to-noise-ratio and dice similarity index (DSI) of segmented vessels. The L2-optimized VAE outperforms SSIM, with improved reconstruction metrics and DSIs for both datasets. Optimization using SSIM performed best for visual image quality, but with discrepancy in quantitative reconstruction and vascular segmentation. The larger, more diverse IXI dataset had overall better performance. Reconstruction metrics, including SSIM, were lower for MRAs including aneurysms. A SSIM-optimized VAE improved the visual perceptive image quality of TOF-MRA reconstructions. A L2-optimized VAE performed best for TOF-MRA reconstruction, where the vascular segmentation is important. SSIM is a potential metric for anomaly detection of MRAs.
Unsupervised cross domain learning with applications to 7 layer segmentation of OCTs
Nov 23, 2021
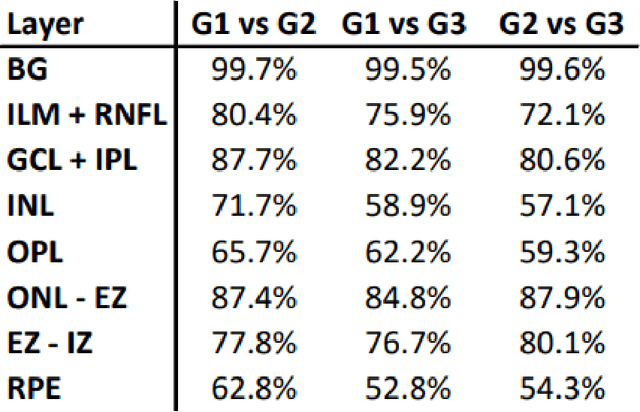
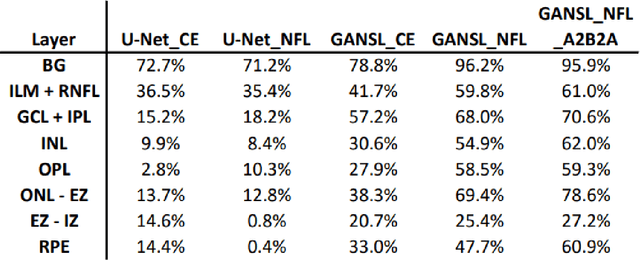
Unsupervised cross domain adaptation for OCT 7 layer segmentation and other medical applications where labeled training data is only available in a source domain and unavailable in the target domain. Our proposed method helps generalize of deep learning to many areas in the medical field where labeled training data are expensive and time consuming to acquire or where target domains are too novel to have had labelling.
DyTox: Transformers for Continual Learning with DYnamic TOken eXpansion
Nov 22, 2021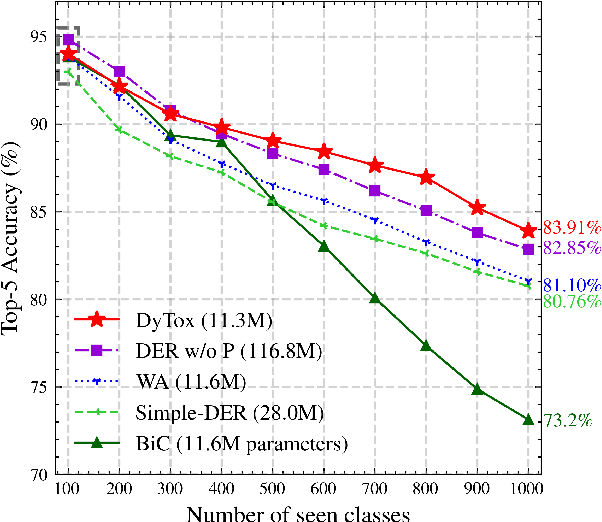
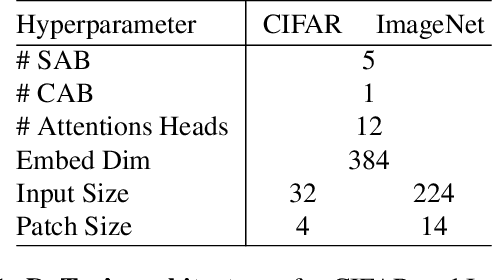
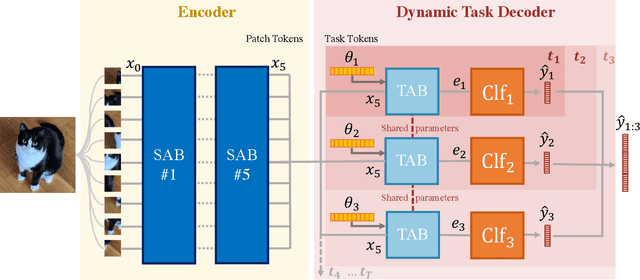
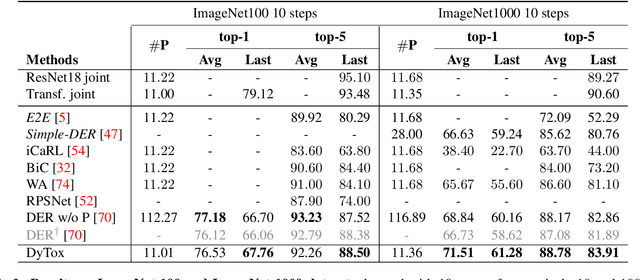
Deep network architectures struggle to continually learn new tasks without forgetting the previous tasks. A recent trend indicates that dynamic architectures based on an expansion of the parameters can reduce catastrophic forgetting efficiently in continual learning. However, existing approaches often require a task identifier at test-time, need complex tuning to balance the growing number of parameters, and barely share any information across tasks. As a result, they struggle to scale to a large number of tasks without significant overhead. In this paper, we propose a transformer architecture based on a dedicated encoder/decoder framework. Critically, the encoder and decoder are shared among all tasks. Through a dynamic expansion of special tokens, we specialize each forward of our decoder network on a task distribution. Our strategy scales to a large number of tasks while having negligible memory and time overheads due to strict control of the parameters expansion. Moreover, this efficient strategy doesn't need any hyperparameter tuning to control the network's expansion. Our model reaches excellent results on CIFAR100 and state-of-the-art performances on the large-scale ImageNet100 and ImageNet1000 while having less parameters than concurrent dynamic frameworks.
RobustTAD: Robust Time Series Anomaly Detection via Decomposition and Convolutional Neural Networks
Feb 21, 2020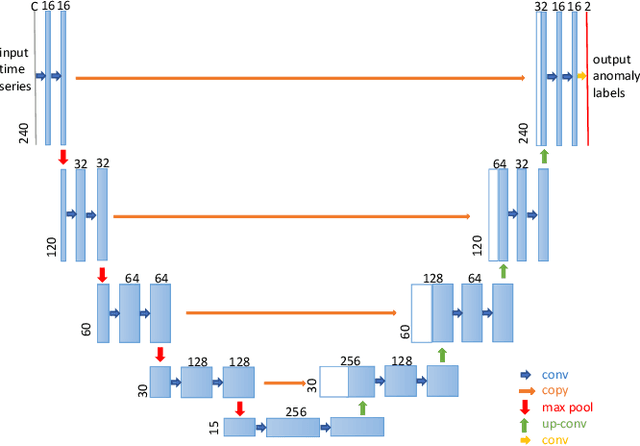
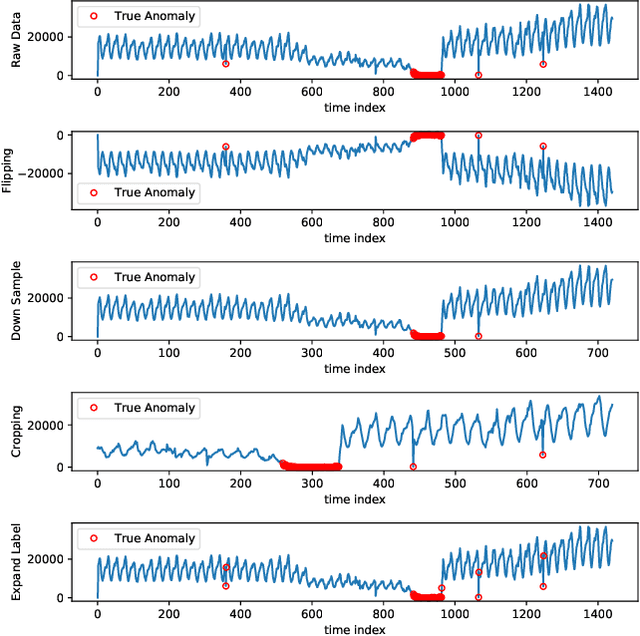
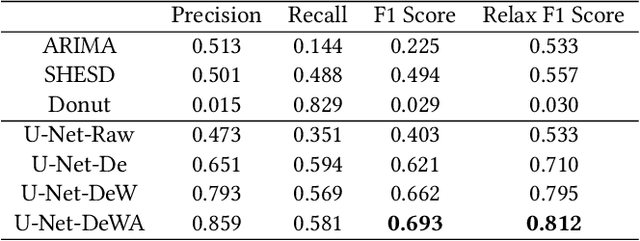
The monitoring and management of numerous and diverse time series data at Alibaba Group calls for an effective and scalable time series anomaly detection service. In this paper, we propose RobustTAD, a Robust Time series Anomaly Detection framework by integrating robust seasonal-trend decomposition and convolutional neural network for time series data. The seasonal-trend decomposition can effectively handle complicated patterns in time series, and meanwhile significantly simplifies the architecture of the neural network, which is an encoder-decoder architecture with skip connections. This architecture can effectively capture the multi-scale information from time series, which is very useful in anomaly detection. Due to the limited labeled data in time series anomaly detection, we systematically investigate data augmentation methods in both time and frequency domains. We also introduce label-based weight and value-based weight in the loss function by utilizing the unbalanced nature of the time series anomaly detection problem. Compared with the widely used forecasting-based anomaly detection algorithms, decomposition-based algorithms, traditional statistical algorithms, as well as recent neural network based algorithms, RobustTAD performs significantly better on public benchmark datasets. It is deployed as a public online service and widely adopted in different business scenarios at Alibaba Group.
Smart Magnetic Microrobots Learn to Swim with Deep Reinforcement Learning
Jan 14, 2022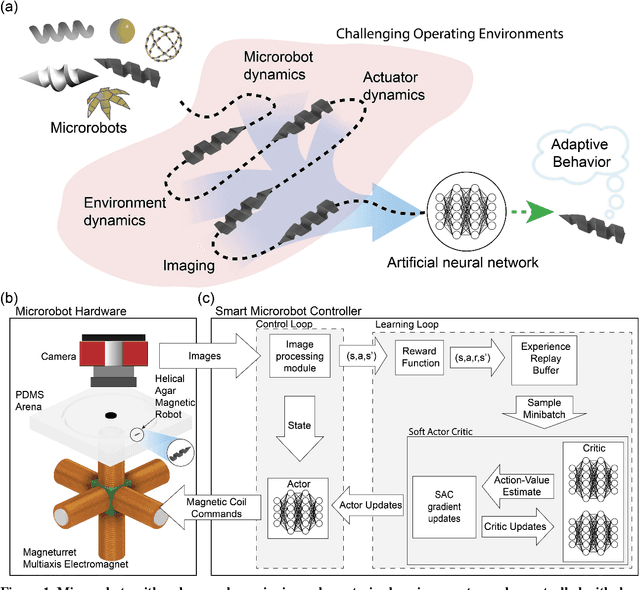
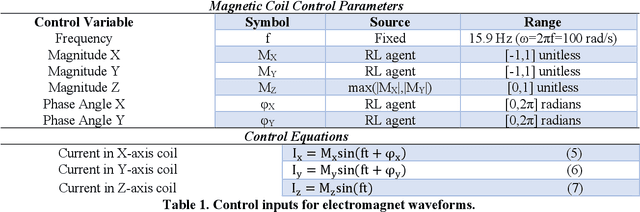
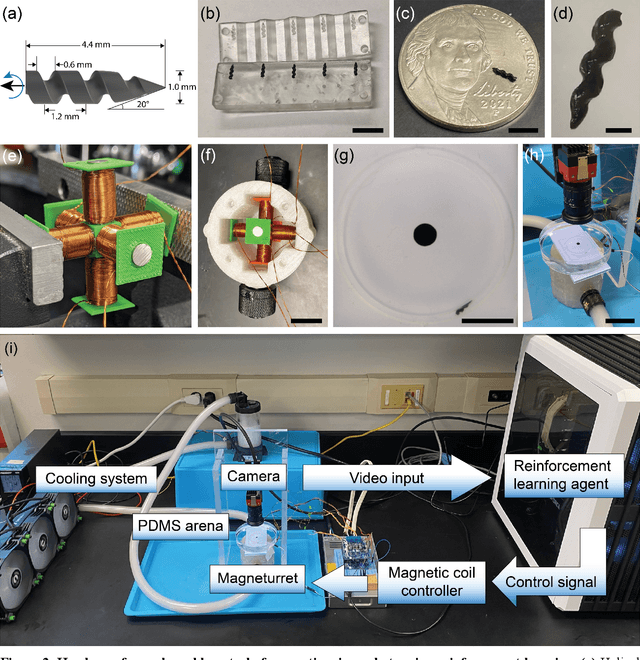
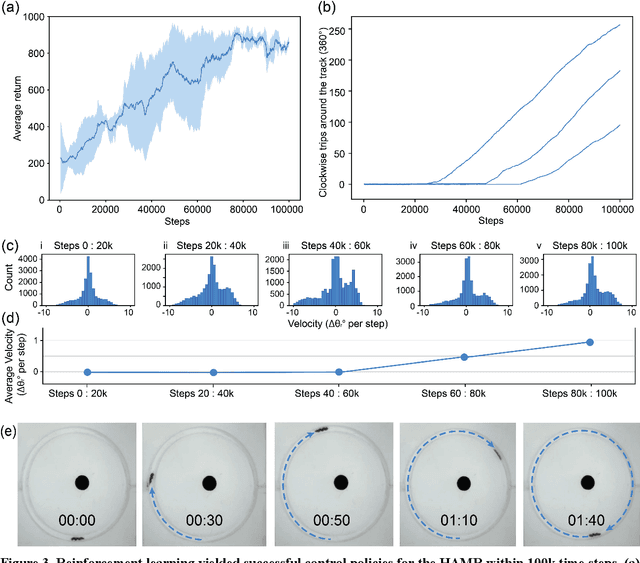
Swimming microrobots are increasingly developed with complex materials and dynamic shapes and are expected to operate in complex environments in which the system dynamics are difficult to model and positional control of the microrobot is not straightforward to achieve. Deep reinforcement learning is a promising method of autonomously developing robust controllers for creating smart microrobots, which can adapt their behavior to operate in uncharacterized environments without the need to model the system dynamics. Here, we report the development of a smart helical magnetic hydrogel microrobot that used the soft actor critic reinforcement learning algorithm to autonomously derive a control policy which allowed the microrobot to swim through an uncharacterized biomimetic fluidic environment under control of a time varying magnetic field generated from a three-axis array of electromagnets. The reinforcement learning agent learned successful control policies with fewer than 100,000 training steps, demonstrating sample efficiency for fast learning. We also demonstrate that we can fine tune the control policies learned by the reinforcement learning agent by fitting mathematical functions to the learned policy's action distribution via regression. Deep reinforcement learning applied to microrobot control is likely to significantly expand the capabilities of the next generation of microrobots.
On reducing the order of arm-passes bandit streaming algorithms under memory bottleneck
Nov 30, 2021
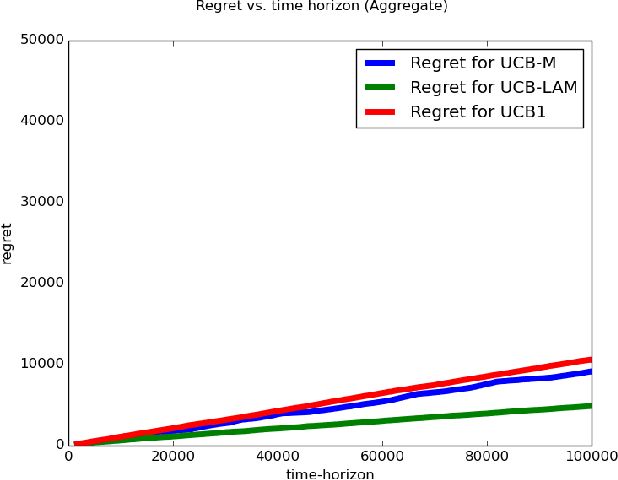
In this work we explore multi-arm bandit streaming model, especially in cases where the model faces resource bottleneck. We build over existing algorithms conditioned by limited arm memory at any instance of time. Specifically, we improve the amount of streaming passes it takes for a bandit algorithm to incur a $O(\sqrt{T\log(T)})$ regret by a logarithmic factor, and also provide 2-pass algorithms with some initial conditions to incur a similar order of regret.
MAC-ReconNet: A Multiple Acquisition Context based Convolutional Neural Network for MR Image Reconstruction using Dynamic Weight Prediction
Nov 09, 2021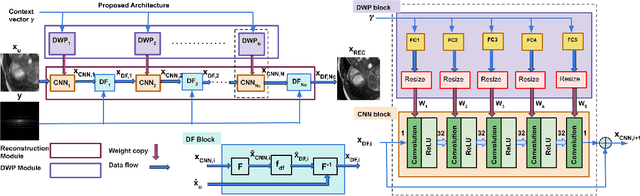

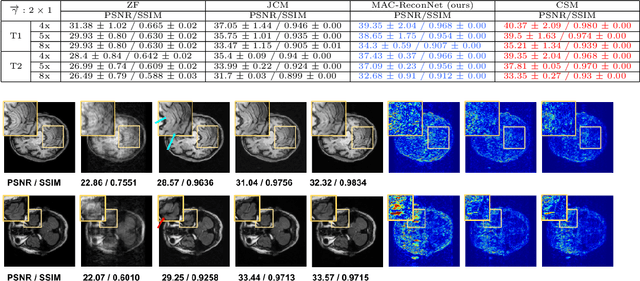
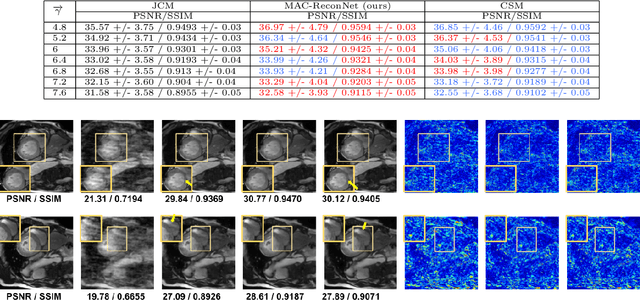
Convolutional Neural network-based MR reconstruction methods have shown to provide fast and high quality reconstructions. A primary drawback with a CNN-based model is that it lacks flexibility and can effectively operate only for a specific acquisition context limiting practical applicability. By acquisition context, we mean a specific combination of three input settings considered namely, the anatomy under study, undersampling mask pattern and acceleration factor for undersampling. The model could be trained jointly on images combining multiple contexts. However the model does not meet the performance of context specific models nor extensible to contexts unseen at train time. This necessitates a modification to the existing architecture in generating context specific weights so as to incorporate flexibility to multiple contexts. We propose a multiple acquisition context based network, called MAC-ReconNet for MRI reconstruction, flexible to multiple acquisition contexts and generalizable to unseen contexts for applicability in real scenarios. The proposed network has an MRI reconstruction module and a dynamic weight prediction (DWP) module. The DWP module takes the corresponding acquisition context information as input and learns the context-specific weights of the reconstruction module which changes dynamically with context at run time. We show that the proposed approach can handle multiple contexts based on cardiac and brain datasets, Gaussian and Cartesian undersampling patterns and five acceleration factors. The proposed network outperforms the naive jointly trained model and gives competitive results with the context-specific models both quantitatively and qualitatively. We also demonstrate the generalizability of our model by testing on contexts unseen at train time.
Oral cancer detection and interpretation: Deep multiple instance learning versus conventional deep single instance learning
Feb 03, 2022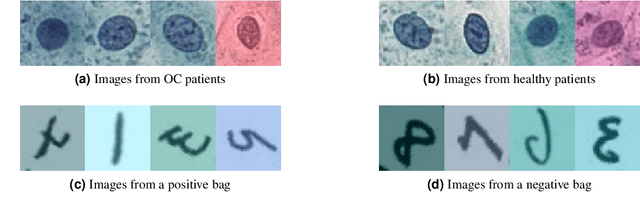
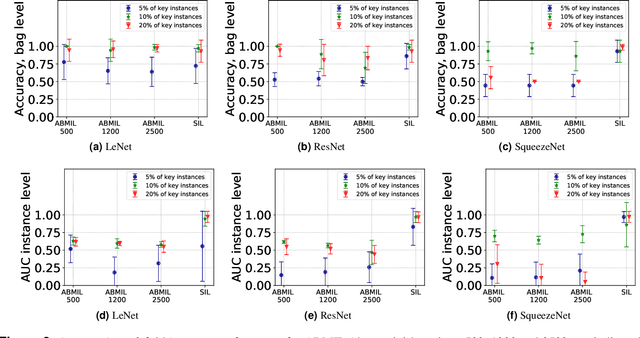

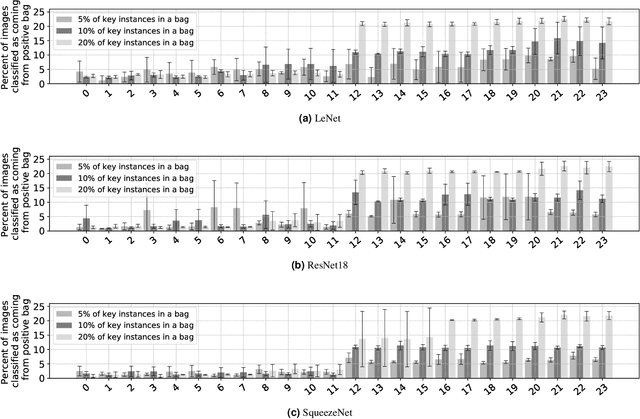
The current medical standard for setting an oral cancer (OC) diagnosis is histological examination of a tissue sample from the oral cavity. This process is time consuming and more invasive than an alternative approach of acquiring a brush sample followed by cytological analysis. Skilled cytotechnologists are able to detect changes due to malignancy, however, to introduce this approach into clinical routine is associated with challenges such as a lack of experts and labour-intensive work. To design a trustworthy OC detection system that would assist cytotechnologists, we are interested in AI-based methods that reliably can detect cancer given only per-patient labels (minimizing annotation bias), and also provide information on which cells are most relevant for the diagnosis (enabling supervision and understanding). We, therefore, perform a comparison of a conventional single instance learning (SIL) approach and a modern multiple instance learning (MIL) method suitable for OC detection and interpretation, utilizing three different neural network architectures. To facilitate systematic evaluation of the considered approaches, we introduce a synthetic PAP-QMNIST dataset, that serves as a model of OC data, while offering access to per-instance ground truth. Our study indicates that on PAP-QMNIST, the SIL performs better, on average, than the MIL approach. Performance at the bag level on real-world cytological data is similar for both methods, yet the single instance approach performs better on average. Visual examination by cytotechnologist indicates that the methods manage to identify cells which deviate from normality, including malignant cells as well as those suspicious for dysplasia. We share the code as open source at https://github.com/MIDA-group/OralCancerMILvsSIL