 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning-Based Adaptive IRS Control with Limited Feedback Codebooks
May 07, 2022
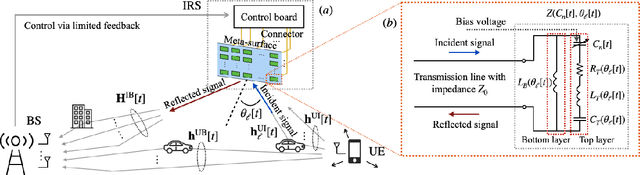

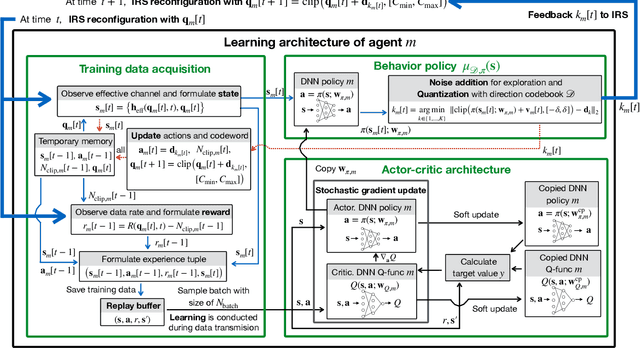
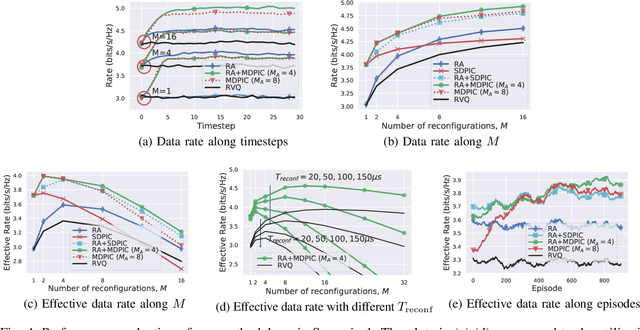
Intelligent reflecting surfaces (IRS) consist of configurable meta-atoms, which can alter the wireless propagation environment through design of their reflection coefficients. We consider adaptive IRS control in the practical setting where (i) the IRS reflection coefficients are attained by adjusting tunable elements embedded in the meta-atoms, (ii) the IRS reflection coefficients are affected by the incident angles of the incoming signals, (iii) the IRS is deployed in multi-path, time-varying channels, and (iv) the feedback link from the base station (BS) to the IRS has a low data rate. Conventional optimization-based IRS control protocols, which rely on channel estimation and conveying the optimized variables to the IRS, are not practical in this setting due to the difficulty of channel estimation and the low data rate of the feedback channel. To address these challenges, we develop a novel adaptive codebook-based limited feedback protocol to control the IRS. We propose two solutions for adaptive IRS codebook design: (i) random adjacency (RA), which utilizes correlations across the channel realizations, and (ii) deep neural network policy-based IRS control (DPIC), which is based on a deep reinforcement learning. Numerical evaluations show that the data rate and average data rate over one coherence time are improved substantially by the proposed schemes.
Development of a Stereo-Vision Based High-Throughput Robotic System for Mouse Tail Vein Injection
May 25, 2022
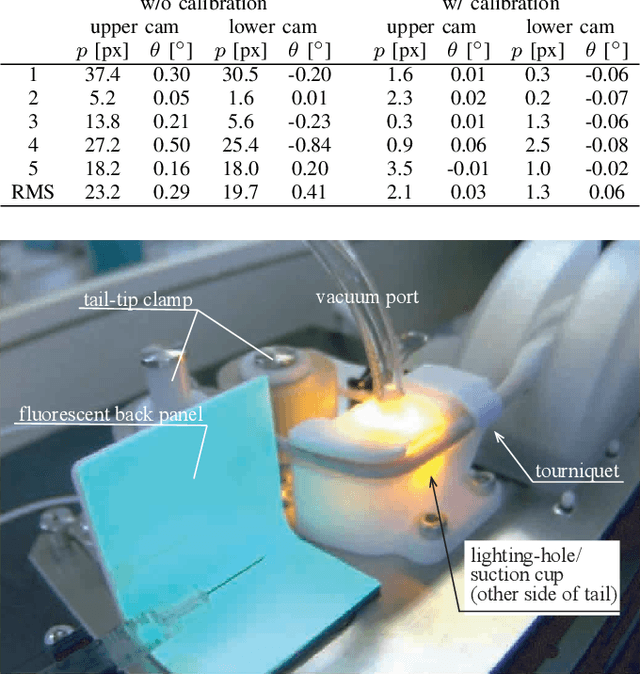

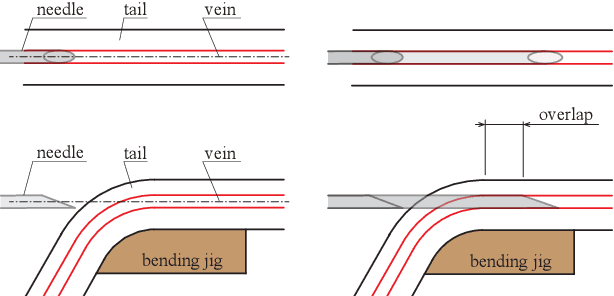
In this paper, we present a robotic device for mouse tail vein injection. We propose a mouse holding mechanism to realize vein injection without anesthetizing the mouse, which consists of a tourniquet, vacuum port, and adaptive tail-end fixture. The position of the target vein in 3D space is reconstructed from a high-resolution stereo vision. The vein is detected by a simple but robust vein line detector. Thanks to the proposed two-staged calibration process, the total time for the injection process is limited to 1.5 minutes, despite that the position of needle and tail vein varies for each trial. We performed an injection experiment targeting 40 mice and succeeded to inject saline to 37 of them, resulting 92.5% success ratio.
Robust Sparse Mean Estimation via Sum of Squares
Jun 07, 2022We study the problem of high-dimensional sparse mean estimation in the presence of an $\epsilon$-fraction of adversarial outliers. Prior work obtained sample and computationally efficient algorithms for this task for identity-covariance subgaussian distributions. In this work, we develop the first efficient algorithms for robust sparse mean estimation without a priori knowledge of the covariance. For distributions on $\mathbb R^d$ with "certifiably bounded" $t$-th moments and sufficiently light tails, our algorithm achieves error of $O(\epsilon^{1-1/t})$ with sample complexity $m = (k\log(d))^{O(t)}/\epsilon^{2-2/t}$. For the special case of the Gaussian distribution, our algorithm achieves near-optimal error of $\tilde O(\epsilon)$ with sample complexity $m = O(k^4 \mathrm{polylog}(d))/\epsilon^2$. Our algorithms follow the Sum-of-Squares based, proofs to algorithms approach. We complement our upper bounds with Statistical Query and low-degree polynomial testing lower bounds, providing evidence that the sample-time-error tradeoffs achieved by our algorithms are qualitatively the best possible.
FREDA: Flexible Relation Extraction Data Annotation
Apr 14, 2022
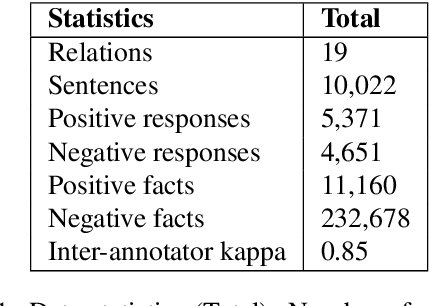
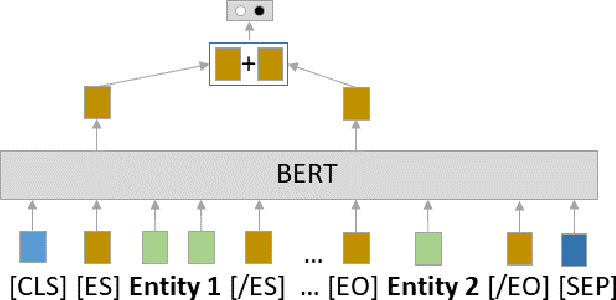
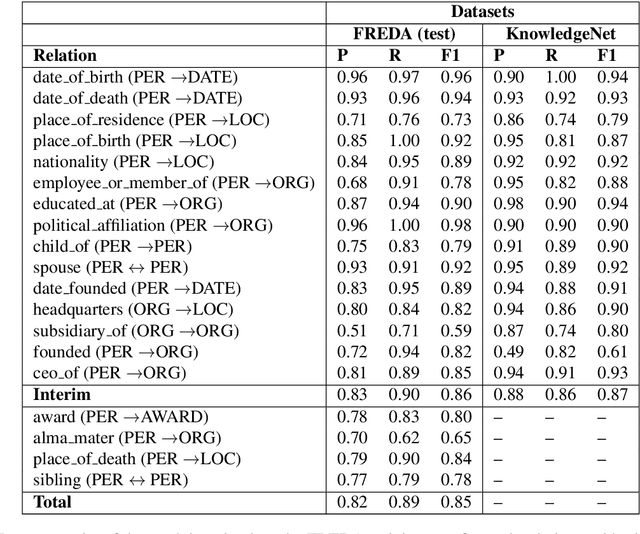
To effectively train accurate Relation Extraction models, sufficient and properly labeled data is required. Adequately labeled data is difficult to obtain and annotating such data is a tricky undertaking. Previous works have shown that either accuracy has to be sacrificed or the task is extremely time-consuming, if done accurately. We are proposing an approach in order to produce high-quality datasets for the task of Relation Extraction quickly. Neural models, trained to do Relation Extraction on the created datasets, achieve very good results and generalize well to other datasets. In our study, we were able to annotate 10,022 sentences for 19 relations in a reasonable amount of time, and trained a commonly used baseline model for each relation.
Revealing Single Frame Bias for Video-and-Language Learning
Jun 07, 2022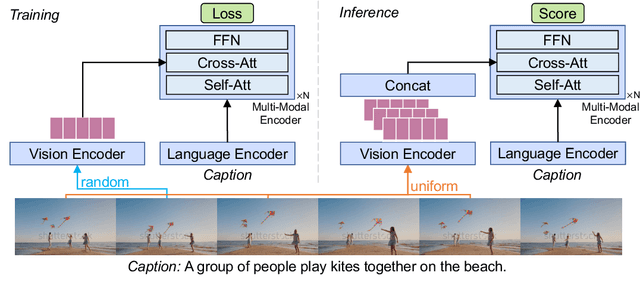
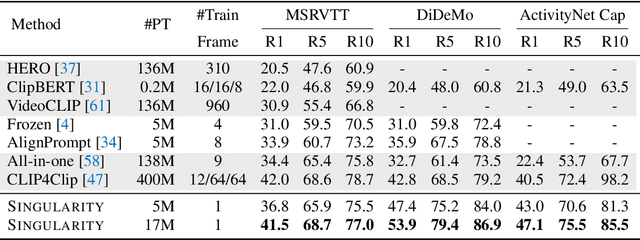
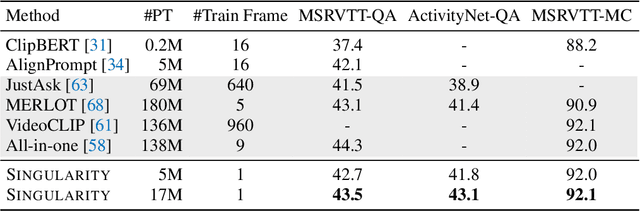

Training an effective video-and-language model intuitively requires multiple frames as model inputs. However, it is unclear whether using multiple frames is beneficial to downstream tasks, and if yes, whether the performance gain is worth the drastically-increased computation and memory costs resulting from using more frames. In this work, we explore single-frame models for video-and-language learning. On a diverse set of video-and-language tasks (including text-to-video retrieval and video question answering), we show the surprising result that, with large-scale pre-training and a proper frame ensemble strategy at inference time, a single-frame trained model that does not consider temporal information can achieve better performance than existing methods that use multiple frames for training. This result reveals the existence of a strong "static appearance bias" in popular video-and-language datasets. Therefore, to allow for a more comprehensive evaluation of video-and-language models, we propose two new retrieval tasks based on existing fine-grained action recognition datasets that encourage temporal modeling. Our code is available at https://github.com/jayleicn/singularity
Open Environment Machine Learning
Jun 01, 2022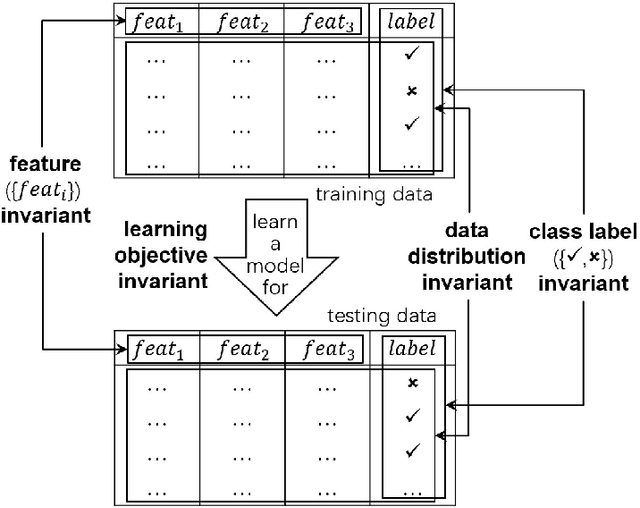
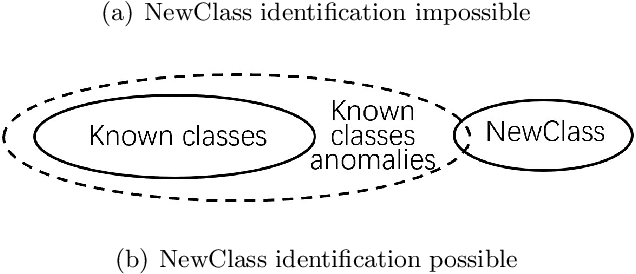
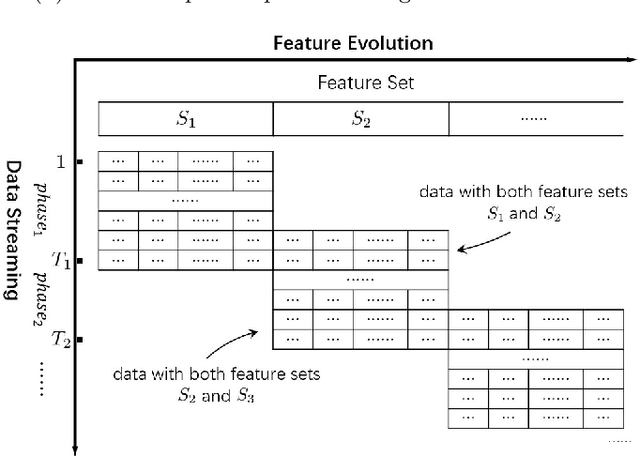
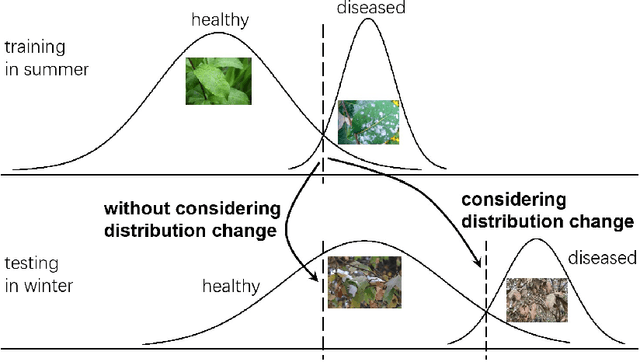
Conventional machine learning studies generally assume close world scenarios where important factors of the learning process hold invariant. With the great success of machine learning, nowadays, more and more practical tasks, particularly those involving open world scenarios where important factors are subject to change, called open environment machine learning (Open ML) in this article, are present to the community. Evidently it is a grand challenge for machine learning turning from close world to open world. It becomes even more challenging since, in various big data tasks, data are usually accumulated with time, like streams, while it is hard to train the machine learning model after collecting all data as in conventional studies. This article briefly introduces some advances in this line of research, focusing on techniques concerning emerging new classes, decremental/incremental features, changing data distributions, varied learning objectives, and discusses some theoretical issues.
Data Collection and Labeling of Real-Time IoT-Enabled Bio-Signals in Everyday Settings for Mental Health Improvement
Aug 02, 2021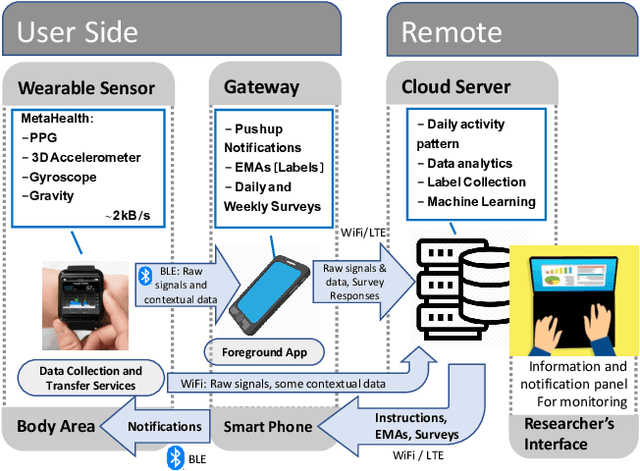
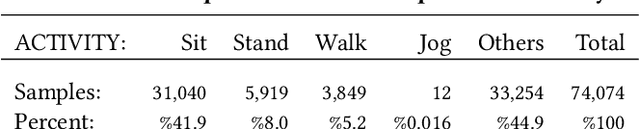
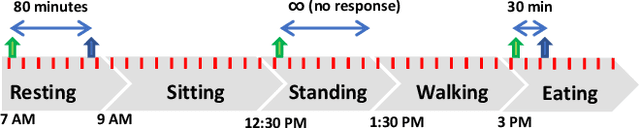

Real-time physiological data collection and analysis play a central role in modern well-being applications. Personalized classifiers and detectors have been shown to outperform general classifiers in many contexts. However, building effective personalized classifiers in everyday settings - as opposed to controlled settings - necessitates the online collection of a labeled dataset by interacting with the user. This need leads to several challenges, ranging from building an effective system for the collection of the signals and labels, to developing strategies to interact with the user and building a dataset that represents the many user contexts that occur in daily life. Based on a stress detection use case, this paper (1) builds a system for the real-time collection and analysis of photoplethysmogram, acceleration, gyroscope, and gravity data from a wearable sensor, as well as self-reported stress labels based on Ecological Momentary Assessment (EMA), and (2) collects and analyzes a dataset to extract statistics of users' response to queries and the quality of the collected signals as a function of the context, here defined as the user's activity and the time of the day.
Preconditioned Gradient Descent for Overparameterized Nonconvex Burer--Monteiro Factorization with Global Optimality Certification
Jun 07, 2022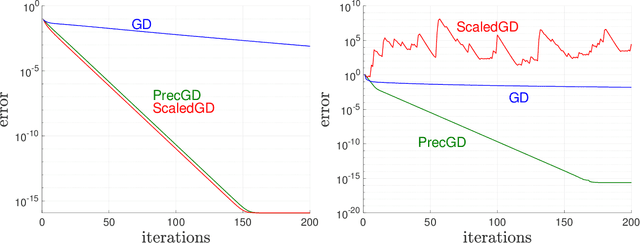
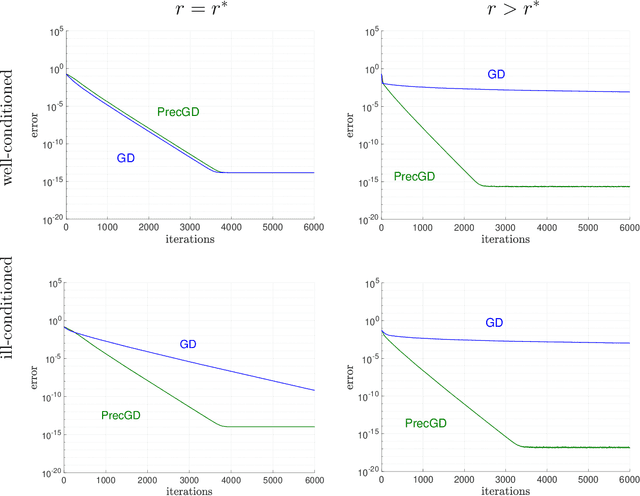
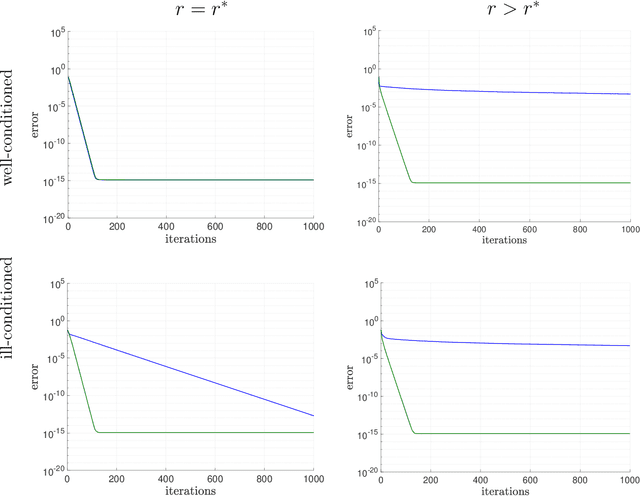
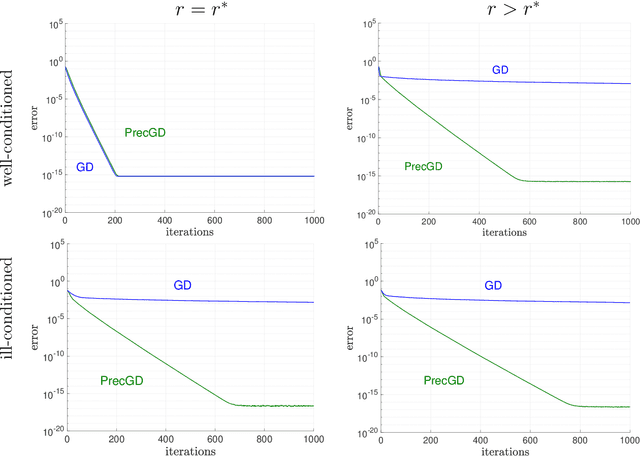
We consider using gradient descent to minimize the nonconvex function $f(X)=\phi(XX^{T})$ over an $n\times r$ factor matrix $X$, in which $\phi$ is an underlying smooth convex cost function defined over $n\times n$ matrices. While only a second-order stationary point $X$ can be provably found in reasonable time, if $X$ is additionally rank deficient, then its rank deficiency certifies it as being globally optimal. This way of certifying global optimality necessarily requires the search rank $r$ of the current iterate $X$ to be overparameterized with respect to the rank $r^{\star}$ of the global minimizer $X^{\star}$. Unfortunately, overparameterization significantly slows down the convergence of gradient descent, from a linear rate with $r=r^{\star}$ to a sublinear rate when $r>r^{\star}$, even when $\phi$ is strongly convex. In this paper, we propose an inexpensive preconditioner that restores the convergence rate of gradient descent back to linear in the overparameterized case, while also making it agnostic to possible ill-conditioning in the global minimizer $X^{\star}$.
Towards Using Promises for Multi-Agent Cooperation in Goal Reasoning
Jun 20, 2022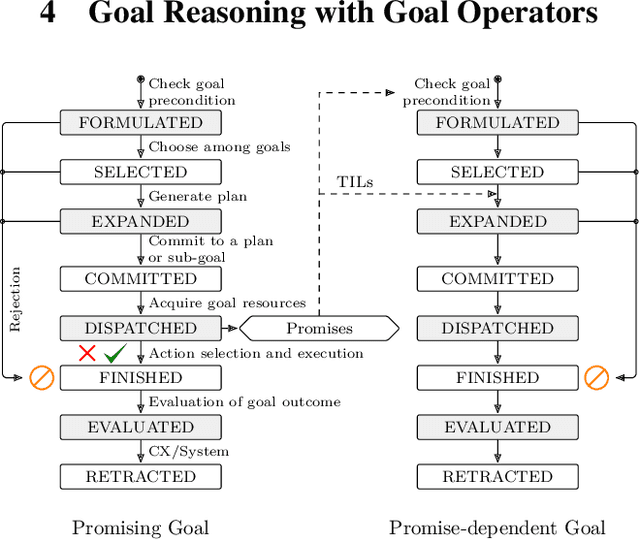

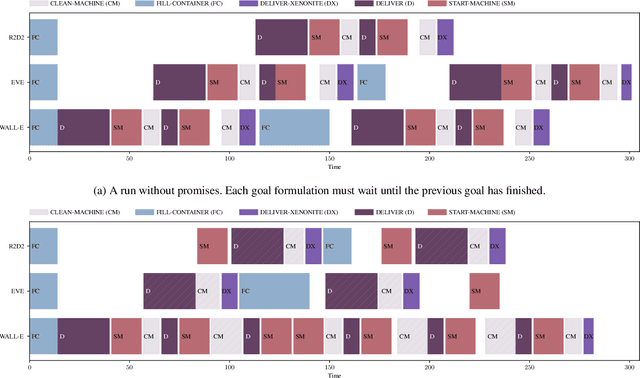
Reasoning and planning for mobile robots is a challenging problem, as the world evolves over time and thus the robot's goals may change. One technique to tackle this problem is goal reasoning, where the agent not only reasons about its actions, but also about which goals to pursue. While goal reasoning for single agents has been researched extensively, distributed, multi-agent goal reasoning comes with additional challenges, especially in a distributed setting. In such a context, some form of coordination is necessary to allow for cooperative behavior. Previous goal reasoning approaches share the agent's world model with the other agents, which already enables basic cooperation. However, the agent's goals, and thus its intentions, are typically not shared. In this paper, we present a method to tackle this limitation. Extending an existing goal reasoning framework, we propose enabling cooperative behavior between multiple agents through promises, where an agent may promise that certain facts will be true at some point in the future. Sharing these promises allows other agents to not only consider the current state of the world, but also the intentions of other agents when deciding on which goal to pursue next. We describe how promises can be incorporated into the goal life cycle, a commonly used goal refinement mechanism. We then show how promises can be used when planning for a particular goal by connecting them to timed initial literals (TILs) from PDDL planning. Finally, we evaluate our prototypical implementation in a simplified logistics scenario.
Competitive Gradient Optimization
May 27, 2022
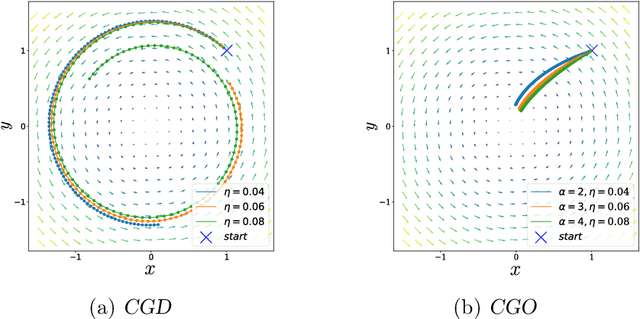
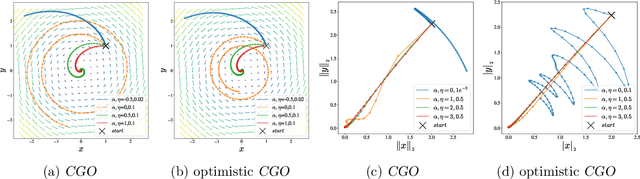
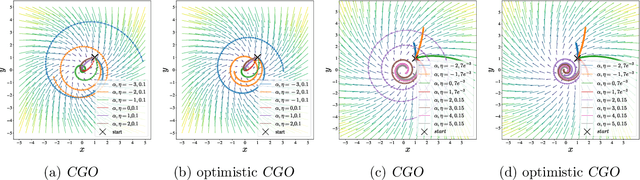
We study the problem of convergence to a stationary point in zero-sum games. We propose competitive gradient optimization (CGO ), a gradient-based method that incorporates the interactions between the two players in zero-sum games for optimization updates. We provide continuous-time analysis of CGO and its convergence properties while showing that in the continuous limit, CGO predecessors degenerate to their gradient descent ascent (GDA) variants. We provide a rate of convergence to stationary points and further propose a generalized class of $\alpha$-coherent function for which we provide convergence analysis. We show that for strictly $\alpha$-coherent functions, our algorithm convergences to a saddle point. Moreover, we propose optimistic CGO (OCGO), an optimistic variant, for which we show convergence rate to saddle points in $\alpha$-coherent class of functions.