 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Membership Inference Attacks against Diffusion Models
Feb 07, 2023
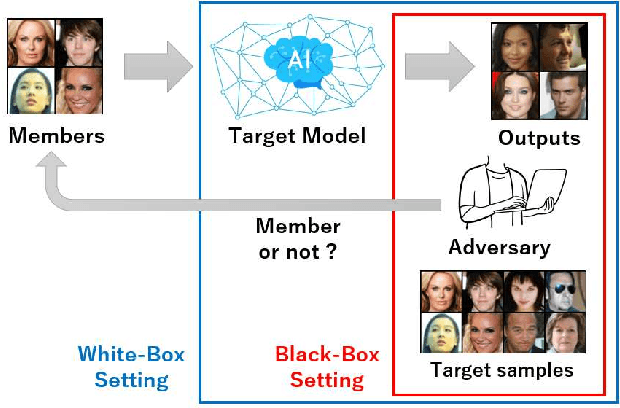
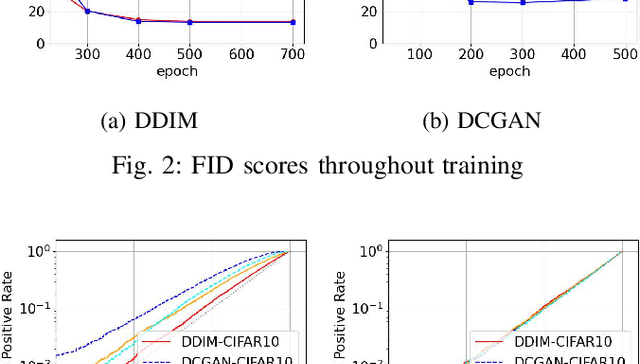
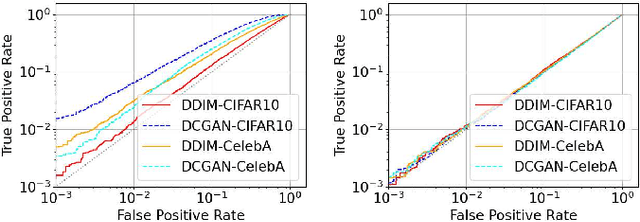
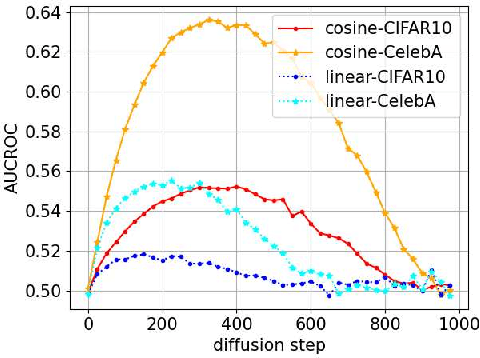
Diffusion models have attracted attention in recent years as innovative generative models. In this paper, we investigate whether a diffusion model is resistant to a membership inference attack, which evaluates the privacy leakage of a machine learning model. We primarily discuss the diffusion model from the standpoints of comparison with a generative adversarial network (GAN) as conventional models and hyperparameters unique to the diffusion model, i.e., time steps, sampling steps, and sampling variances. We conduct extensive experiments with DDIM as a diffusion model and DCGAN as a GAN on the CelebA and CIFAR-10 datasets in both white-box and black-box settings and then confirm if the diffusion model is comparably resistant to a membership inference attack as GAN. Next, we demonstrate that the impact of time steps is significant and intermediate steps in a noise schedule are the most vulnerable to the attack. We also found two key insights through further analysis. First, we identify that DDIM is vulnerable to the attack for small sample sizes instead of achieving a lower FID. Second, sampling steps in hyperparameters are important for resistance to the attack, whereas the impact of sampling variances is quite limited.
Online Reinforcement Learning with Uncertain Episode Lengths
Feb 07, 2023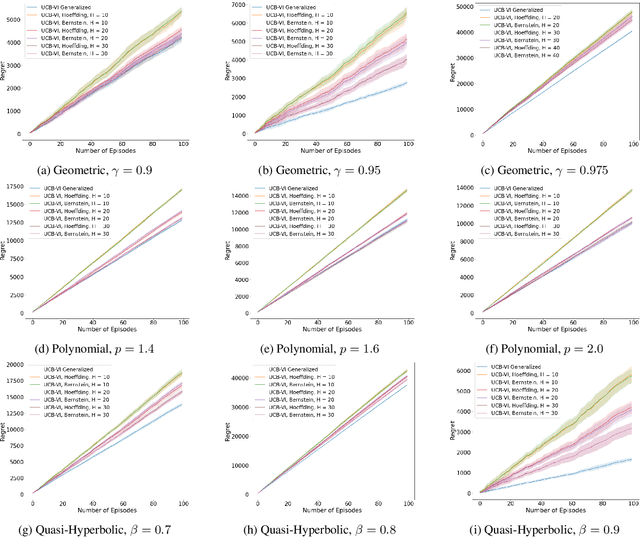
Existing episodic reinforcement algorithms assume that the length of an episode is fixed across time and known a priori. In this paper, we consider a general framework of episodic reinforcement learning when the length of each episode is drawn from a distribution. We first establish that this problem is equivalent to online reinforcement learning with general discounting where the learner is trying to optimize the expected discounted sum of rewards over an infinite horizon, but where the discounting function is not necessarily geometric. We show that minimizing regret with this new general discounting is equivalent to minimizing regret with uncertain episode lengths. We then design a reinforcement learning algorithm that minimizes regret with general discounting but acts for the setting with uncertain episode lengths. We instantiate our general bound for different types of discounting, including geometric and polynomial discounting. We also show that we can obtain similar regret bounds even when the uncertainty over the episode lengths is unknown, by estimating the unknown distribution over time. Finally, we compare our learning algorithms with existing value-iteration based episodic RL algorithms in a grid-world environment.
HE-MAN -- Homomorphically Encrypted MAchine learning with oNnx models
Feb 16, 2023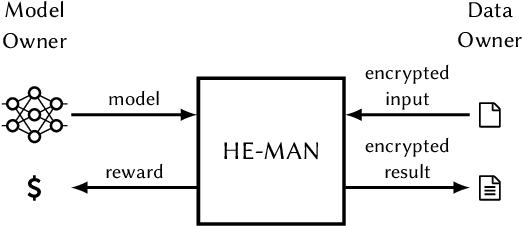
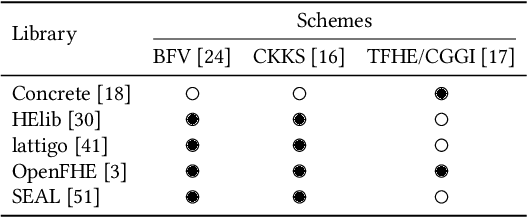
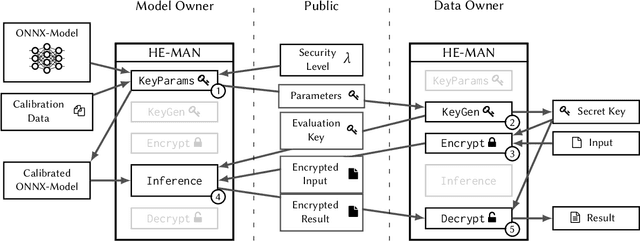

Machine learning (ML) algorithms are increasingly important for the success of products and services, especially considering the growing amount and availability of data. This also holds for areas handling sensitive data, e.g. applications processing medical data or facial images. However, people are reluctant to pass their personal sensitive data to a ML service provider. At the same time, service providers have a strong interest in protecting their intellectual property and therefore refrain from publicly sharing their ML model. Fully homomorphic encryption (FHE) is a promising technique to enable individuals using ML services without giving up privacy and protecting the ML model of service providers at the same time. Despite steady improvements, FHE is still hardly integrated in today's ML applications. We introduce HE-MAN, an open-source two-party machine learning toolset for privacy preserving inference with ONNX models and homomorphically encrypted data. Both the model and the input data do not have to be disclosed. HE-MAN abstracts cryptographic details away from the users, thus expertise in FHE is not required for either party. HE-MAN 's security relies on its underlying FHE schemes. For now, we integrate two different homomorphic encryption schemes, namely Concrete and TenSEAL. Compared to prior work, HE-MAN supports a broad range of ML models in ONNX format out of the box without sacrificing accuracy. We evaluate the performance of our implementation on different network architectures classifying handwritten digits and performing face recognition and report accuracy and latency of the homomorphically encrypted inference. Cryptographic parameters are automatically derived by the tools. We show that the accuracy of HE-MAN is on par with models using plaintext input while inference latency is several orders of magnitude higher compared to the plaintext case.
SC-Block: Supervised Contrastive Blocking within Entity Resolution Pipelines
Mar 06, 2023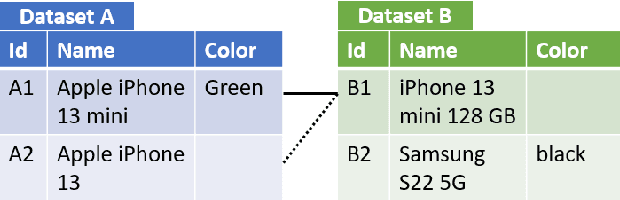

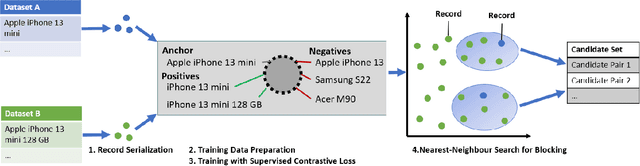
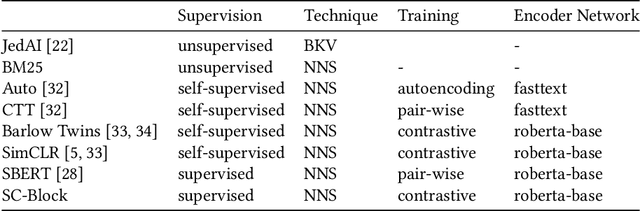
The goal of entity resolution is to identify records in multiple datasets that represent the same real-world entity. However, comparing all records across datasets can be computationally intensive, leading to long runtimes. To reduce these runtimes, entity resolution pipelines are constructed of two parts: a blocker that applies a computationally cheap method to select candidate record pairs, and a matcher that afterwards identifies matching pairs from this set using more expensive methods. This paper presents SC-Block, a blocking method that utilizes supervised contrastive learning for positioning records in the embedding space, and nearest neighbour search for candidate set building. We benchmark SC-Block against eight state-of-the-art blocking methods. In order to relate the training time of SC-Block to the reduction of the overall runtime of the entity resolution pipeline, we combine SC-Block with four matching methods into complete pipelines. For measuring the overall runtime, we determine candidate sets with 98% pair completeness and pass them to the matcher. The results show that SC-Block is able to create smaller candidate sets and pipelines with SC-Block execute 1.5 to 2 times faster compared to pipelines with other blockers, without sacrificing F1 score. Blockers are often evaluated using relatively small datasets which might lead to runtime effects resulting from a large vocabulary size being overlooked. In order to measure runtimes in a more challenging setting, we introduce a new benchmark dataset that requires large numbers of product offers to be blocked. On this large-scale benchmark dataset, pipelines utilizing SC-Block and the best-performing matcher execute 8 times faster than pipelines utilizing another blocker with the same matcher reducing the runtime from 2.5 hours to 18 minutes, clearly compensating for the 5 minutes required for training SC-Block.
Cybersecurity of AI medical devices: risks, legislation, and challenges
Mar 06, 2023Medical devices and artificial intelligence systems rapidly transform healthcare provisions. At the same time, due to their nature, AI in or as medical devices might get exposed to cyberattacks, leading to patient safety and security risks. This book chapter is divided into three parts. The first part starts by setting the scene where we explain the role of cybersecurity in healthcare. Then, we briefly define what we refer to when we talk about AI that is considered a medical device by itself or supports one. To illustrate the risks such medical devices pose, we provide three examples: the poisoning of datasets, social engineering, and data or source code extraction. In the second part, the paper provides an overview of the European Union's regulatory framework relevant for ensuring the cybersecurity of AI as or in medical devices (MDR, NIS Directive, Cybersecurity Act, GDPR, the AI Act proposal and the NIS 2 Directive proposal). Finally, the third part of the paper examines possible challenges stemming from the EU regulatory framework. In particular, we look toward the challenges deriving from the two legislative proposals and their interaction with the existing legislation concerning AI medical devices' cybersecurity. They are structured as answers to the following questions: (1) how will the AI Act interact with the MDR regarding the cybersecurity and safety requirements?; (2) how should we interpret incident notification requirements from the NIS 2 Directive proposal and MDR?; and (3) what are the consequences of the evolving term of critical infrastructures? [This is a draft chapter. The final version will be available in Research Handbook on Health, AI and the Law edited by Barry Solaiman & I. Glenn Cohen, forthcoming 2023, Edward Elgar Publishing Ltd]
Enhancing Border Security and Countering Terrorism Through Computer Vision: a Field of Artificial Intelligence
Mar 06, 2023Border security had been a persistent problem in international border especially when it get to the issue of preventing illegal movement of weapons, contraband, drugs, and combating issue of illegal or undocumented immigrant while at the same time ensuring that lawful trade, economic prosperity coupled with national sovereignty across the border is maintained. In this research work, we used open source computer vision (Open CV) and adaboost algorithm to develop a model which can detect a moving object a far off, classify it, automatically snap full image and face of the individual separately, and then run a background check on them against worldwide databases while making a prediction about an individual being a potential threat, intending immigrant, potential terrorists or extremist and then raise sound alarm. Our model can be deployed on any camera device and be mounted at any international border. There are two stages involved, we first developed a model based on open CV computer vision algorithm, with the ability to detect human movement from afar, it will automatically snap both the face and the full image of the person separately, and the second stage is the automatic triggering of background check against the moving object. This ensures it check the moving object against several databases worldwide and is able to determine the admissibility of the person afar off. If the individual is inadmissible, it will automatically alert the border officials with the image of the person and other details, and if the bypass the border officials, the system is able to detect and alert the authority with his images and other details. All these operations will be done afar off by the AI powered camera before the individual reach the border
* 10 pages, 8 figures, Conference publication
Laser Ranging Based Intelligent System for Unknown Environment Mapping
Feb 01, 2023
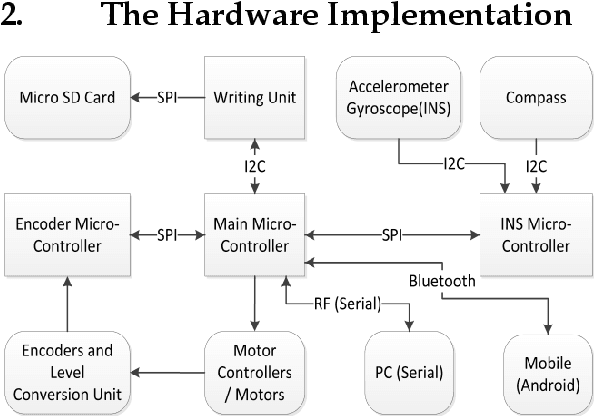
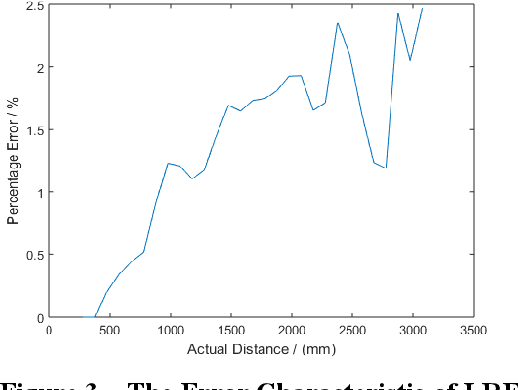
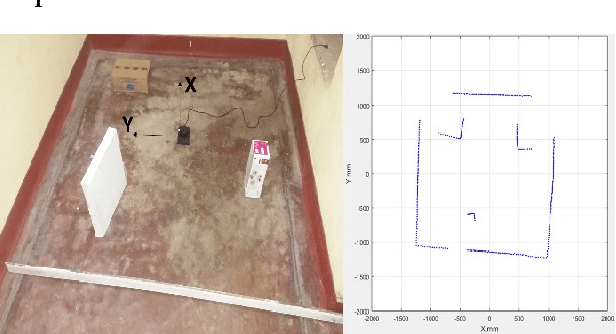
This work describes the implementation of a simple and computationally efficient Intelligent Navigation System (INS) for autonomous systems used in areas where human access is impossible. The system uses Laser Range Finder (LRF) readings as input, making it suitable for mobile platform implementation. The INS pre-processes the LRF readings to remove noise and determines an obstacle-free path for mapping. The system's localization method uses a similarity transform and particle filter. The system was tested in artificially generated environments and emulated in real-time with real-environment data. The system was then implemented in a Raspberry Pi3 on a 3WD Omni-directional mobile platform and tested in real environments. The system was able to generate an accurate 2D map of the area. The proposed methodology was shown to be efficient through a comparative analysis of execution time.
DiSProD: Differentiable Symbolic Propagation of Distributions for Planning
Feb 03, 2023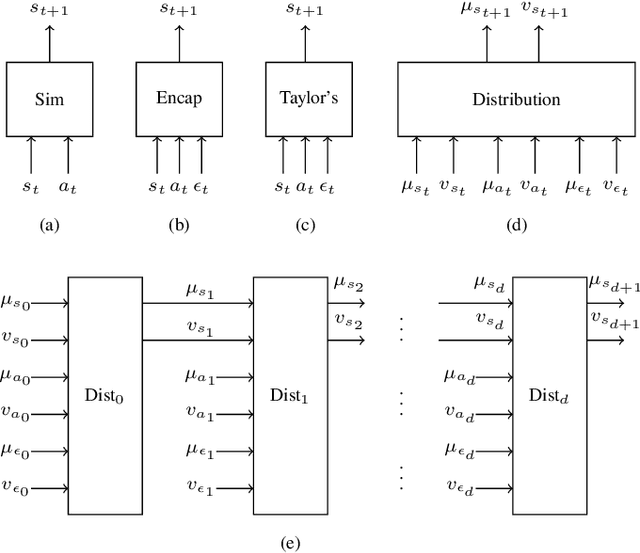

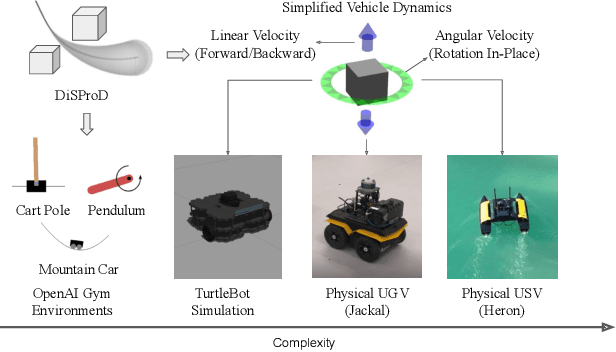
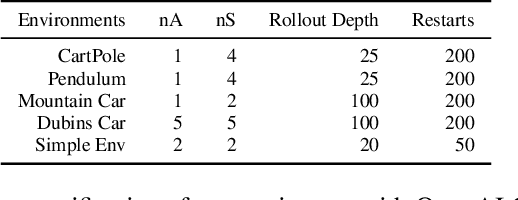
The paper introduces DiSProD, an online planner developed for environments with probabilistic transitions in continuous state and action spaces. DiSProD builds a symbolic graph that captures the distribution of future trajectories, conditioned on a given policy, using independence assumptions and approximate propagation of distributions. The symbolic graph provides a differentiable representation of the policy's value, enabling efficient gradient-based optimization for long-horizon search. The propagation of approximate distributions can be seen as an aggregation of many trajectories, making it well-suited for dealing with sparse rewards and stochastic environments. An extensive experimental evaluation compares DiSProD to state-of-the-art planners in discrete-time planning and real-time control of robotic systems. The proposed method improves over existing planners in handling stochastic environments, sensitivity to search depth, sparsity of rewards, and large action spaces. Additional real-world experiments demonstrate that DiSProD can control ground vehicles and surface vessels to successfully navigate around obstacles.
Reasoning-Based Software Testing
Mar 02, 2023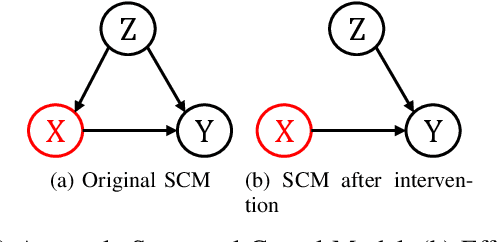
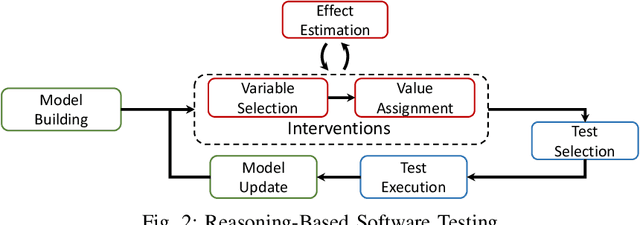
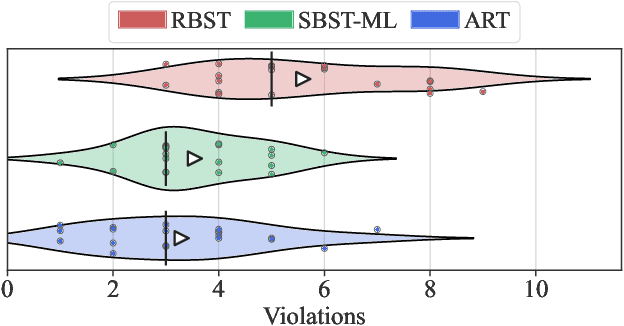
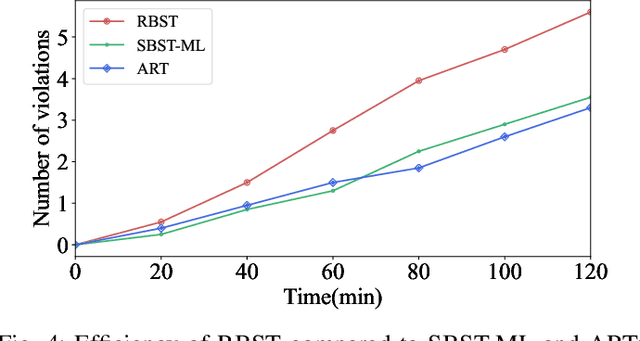
With software systems becoming increasingly pervasive and autonomous, our ability to test for their quality is severely challenged. Many systems are called to operate in uncertain and highly-changing environment, not rarely required to make intelligent decisions by themselves. This easily results in an intractable state space to explore at testing time. The state-of-the-art techniques try to keep the pace, e.g., by augmenting the tester's intuition with some form of (explicit or implicit) learning from observations to search this space efficiently. For instance, they exploit historical data to drive the search (e.g., ML-driven testing) or the tests execution data itself (e.g., adaptive or search-based testing). Despite the indubitable advances, the need for smartening the search in such a huge space keeps to be pressing. We introduce Reasoning-Based Software Testing (RBST), a new way of thinking at the testing problem as a causal reasoning task. Compared to mere intuition-based or state-of-the-art learning-based strategies, we claim that causal reasoning more naturally emulates the process that a human would do to ''smartly" search the space. RBST aims to mimic and amplify, with the power of computation, this ability. The conceptual leap can pave the ground to a new trend of techniques, which can be variously instantiated from the proposed framework, by exploiting the numerous tools for causal discovery and inference. Preliminary results reported in this paper are promising.
Machine Learning-Based Detection of Parkinson's Disease From Resting-State EEG: A Multi-Center Study
Mar 02, 2023
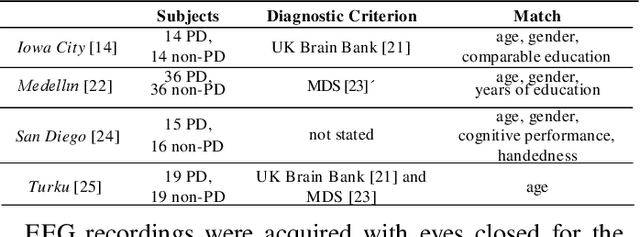


Resting-state EEG (rs-EEG) has been demonstrated to aid in Parkinson's disease (PD) diagnosis. In particular, the power spectral density (PSD) of low-frequency bands ({\delta} and {\theta}) and high-frequency bands ({\alpha} and \b{eta}) has been shown to be significantly different in patients with PD as compared to subjects without PD (non-PD). However, rs-EEG feature extraction and the interpretation thereof can be time-intensive and prone to examiner variability. Machine learning (ML) has the potential to automatize the analysis of rs-EEG recordings and provides a supportive tool for clinicians to ease their workload. In this work, we use rs-EEG recordings of 84 PD and 85 non-PD subjects pooled from four datasets obtained at different centers. We propose an end-to-end pipeline consisting of preprocessing, extraction of PSD features from clinically validated frequency bands, and feature selection before evaluating the classification ability of the features via ML algorithms to stratify between PD and non-PD subjects. Further, we evaluate the effect of feature harmonization, given the multi-center nature of the datasets. Our validation results show, on average, an improvement in PD detection ability (69.6% vs. 75.5% accuracy) by logistic regression when harmonizing the features and performing univariate feature selection (k = 202 features). Our final results show an average global accuracy of 72.2% with balanced accuracy results for all the centers included in the study: 60.6%, 68.7%, 77.7%, and 82.2%, respectively.