 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Understanding the Interplay of Generative Artificial Intelligence and the Internet
Jun 08, 2023

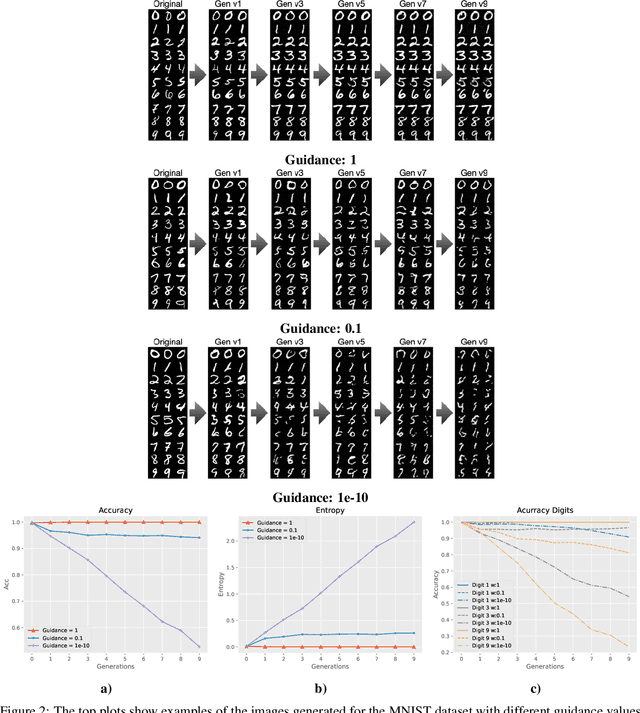
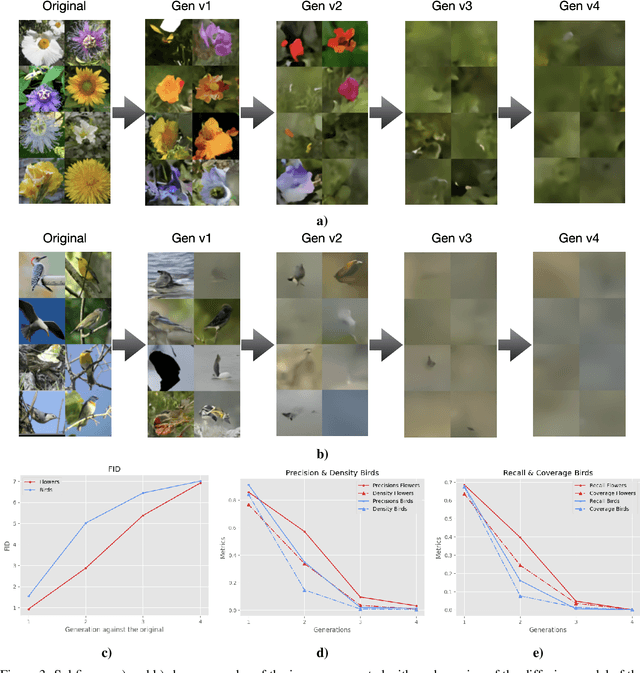
The rapid adoption of generative Artificial Intelligence (AI) tools that can generate realistic images or text, such as DALL-E, MidJourney, or ChatGPT, have put the societal impacts of these technologies at the center of public debate. These tools are possible due to the massive amount of data (text and images) that is publicly available through the Internet. At the same time, these generative AI tools become content creators that are already contributing to the data that is available to train future models. Therefore, future versions of generative AI tools will be trained with a mix of human-created and AI-generated content, causing a potential feedback loop between generative AI and public data repositories. This interaction raises many questions: how will future versions of generative AI tools behave when trained on a mixture of real and AI generated data? Will they evolve and improve with the new data sets or on the contrary will they degrade? Will evolution introduce biases or reduce diversity in subsequent generations of generative AI tools? What are the societal implications of the possible degradation of these models? Can we mitigate the effects of this feedback loop? In this document, we explore the effect of this interaction and report some initial results using simple diffusion models trained with various image datasets. Our results show that the quality and diversity of the generated images can degrade over time suggesting that incorporating AI-created data can have undesired effects on future versions of generative models.
Agent Performing Autonomous Stock Trading under Good and Bad Situations
Jun 06, 2023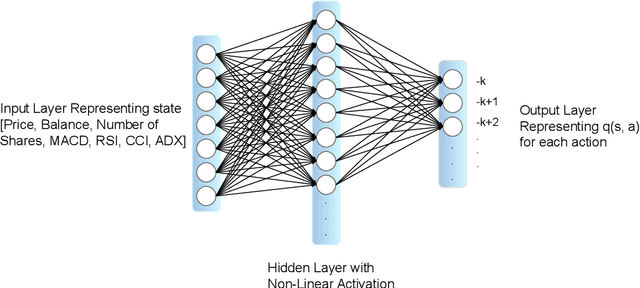

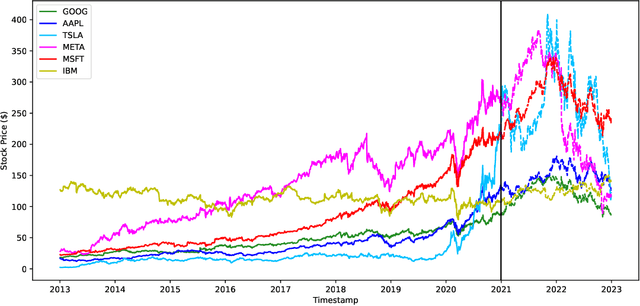
Stock trading is one of the popular ways for financial management. However, the market and the environment of economy is unstable and usually not predictable. Furthermore, engaging in stock trading requires time and effort to analyze, create strategies, and make decisions. It would be convenient and effective if an agent could assist or even do the task of analyzing and modeling the past data and then generate a strategy for autonomous trading. Recently, reinforcement learning has been shown to be robust in various tasks that involve achieving a goal with a decision making strategy based on time-series data. In this project, we have developed a pipeline that simulates the stock trading environment and have trained an agent to automate the stock trading process with deep reinforcement learning methods, including deep Q-learning, deep SARSA, and the policy gradient method. We evaluate our platform during relatively good (before 2021) and bad (2021 - 2022) situations. The stocks we've evaluated on including Google, Apple, Tesla, Meta, Microsoft, and IBM. These stocks are among the popular ones, and the changes in trends are representative in terms of having good and bad situations. We showed that before 2021, the three reinforcement methods we have tried always provide promising profit returns with total annual rates around $70\%$ to $90\%$, while maintain a positive profit return after 2021 with total annual rates around 2% to 7%.
Sequential Principal-Agent Problems with Communication: Efficient Computation and Learning
Jun 06, 2023We study a sequential decision making problem between a principal and an agent with incomplete information on both sides. In this model, the principal and the agent interact in a stochastic environment, and each is privy to observations about the state not available to the other. The principal has the power of commitment, both to elicit information from the agent and to provide signals about her own information. The principal and the agent communicate their signals to each other, and select their actions independently based on this communication. Each player receives a payoff based on the state and their joint actions, and the environment moves to a new state. The interaction continues over a finite time horizon, and both players act to optimize their own total payoffs over the horizon. Our model encompasses as special cases stochastic games of incomplete information and POMDPs, as well as sequential Bayesian persuasion and mechanism design problems. We study both computation of optimal policies and learning in our setting. While the general problems are computationally intractable, we study algorithmic solutions under a conditional independence assumption on the underlying state-observation distributions. We present an polynomial-time algorithm to compute the principal's optimal policy up to an additive approximation. Additionally, we show an efficient learning algorithm in the case where the transition probabilities are not known beforehand. The algorithm guarantees sublinear regret for both players.
PillarAcc: Sparse PointPillars Accelerator for Real-Time Point Cloud 3D Object Detection on Edge Devices
May 15, 2023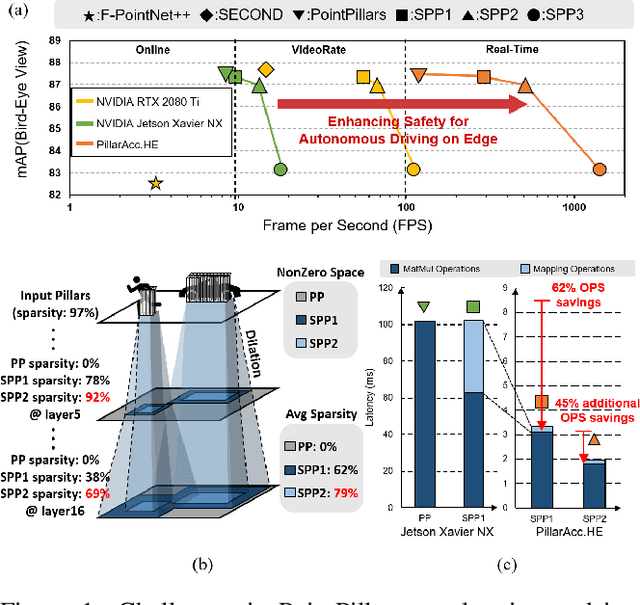
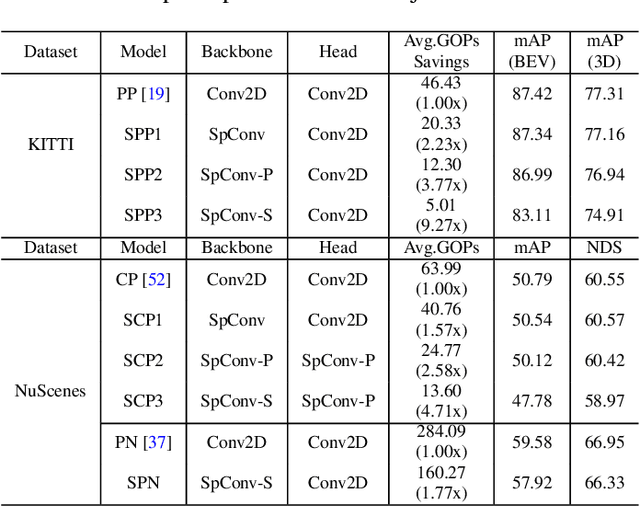
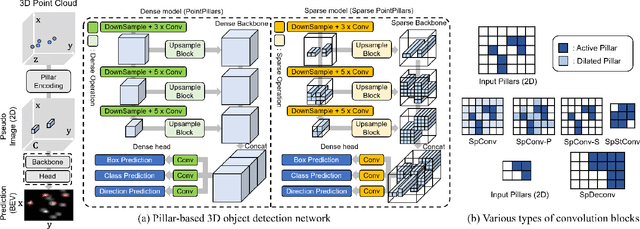
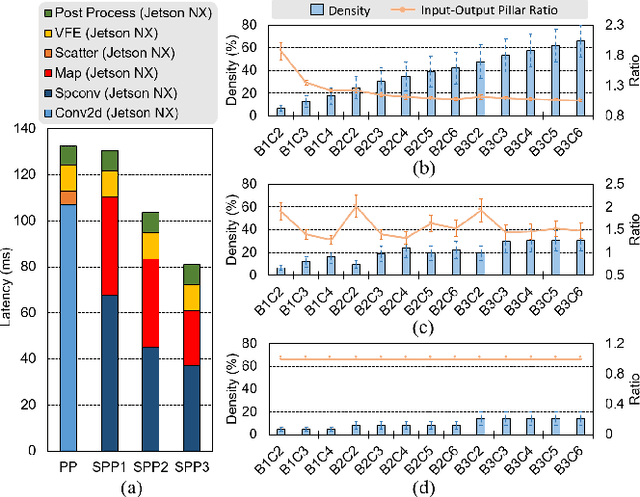
3D object detection using point cloud (PC) data is vital for autonomous driving perception pipelines, where efficient encoding is key to meeting stringent resource and latency requirements. PointPillars, a widely adopted bird's-eye view (BEV) encoding, aggregates 3D point cloud data into 2D pillars for high-accuracy 3D object detection. However, most state-of-the-art methods employing PointPillar overlook the inherent sparsity of pillar encoding, missing opportunities for significant computational reduction. In this study, we propose a groundbreaking algorithm-hardware co-design that accelerates sparse convolution processing and maximizes sparsity utilization in pillar-based 3D object detection networks. We investigate sparsification opportunities using an advanced pillar-pruning method, achieving an optimal balance between accuracy and sparsity. We introduce PillarAcc, a state-of-the-art sparsity support mechanism that enhances sparse pillar convolution through linear complexity input-output mapping generation and conflict-free gather-scatter memory access. Additionally, we propose dataflow optimization techniques, dynamically adjusting the pillar processing schedule for optimal hardware utilization under diverse sparsity operations. We evaluate PillarAcc on various cutting-edge 3D object detection networks and benchmarks, achieving remarkable speedup and energy savings compared to representative edge platforms, demonstrating record-breaking PointPillars speed of 500FPS with minimal compromise in accuracy.
Bottom-Up Grounding in the Probabilistic Logic Programming System Fusemate
Jun 13, 2023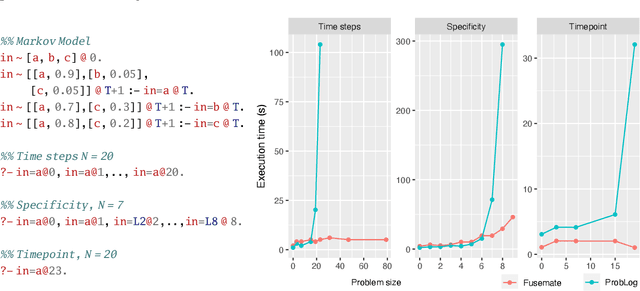
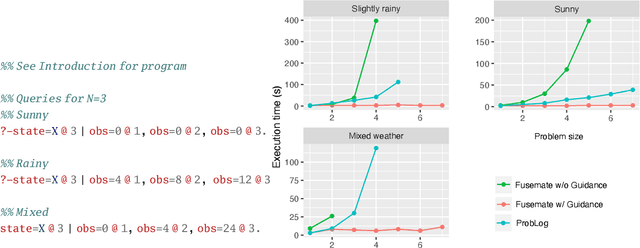
This paper introduces the Fusemate probabilistic logic programming system. Fusemate's inference engine comprises a grounding component and a variable elimination method for probabilistic inference. Fusemate differs from most other systems by grounding the program in a bottom-up way instead of the common top-down way. While bottom-up grounding is attractive for a number of reasons, e.g., for dynamically creating distributions of varying support sizes, it makes it harder to control the amount of ground clauses generated. We address this problem by interleaving grounding with a query-guided relevance test which prunes rules whose bodies are inconsistent with the query. We present our method in detail and demonstrate it with examples that involve "time", such as (hidden) Markov models. Our experiments demonstrate competitive or better performance compared to a state-of-the art probabilistic logic programming system, in particular for high branching problems.
Sea Ice Segmentation From SAR Data by Convolutional Transformer Networks
Jun 13, 2023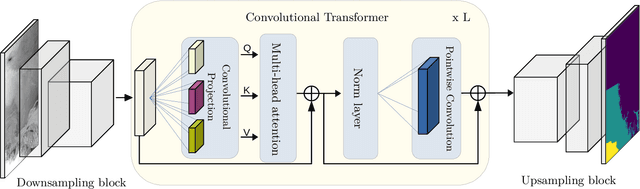
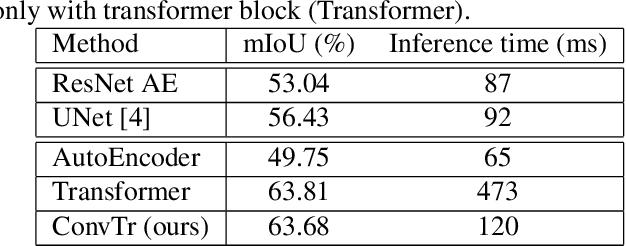
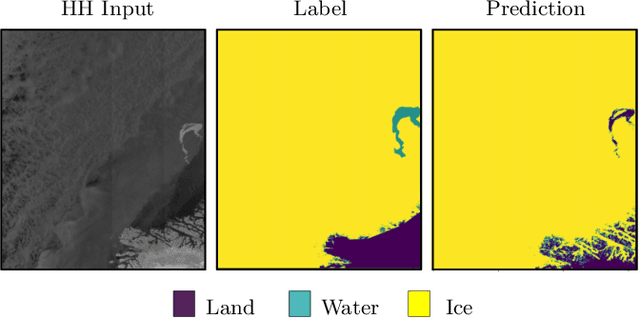
Sea ice is a crucial component of the Earth's climate system and is highly sensitive to changes in temperature and atmospheric conditions. Accurate and timely measurement of sea ice parameters is important for understanding and predicting the impacts of climate change. Nevertheless, the amount of satellite data acquired over ice areas is huge, making the subjective measurements ineffective. Therefore, automated algorithms must be used in order to fully exploit the continuous data feeds coming from satellites. In this paper, we present a novel approach for sea ice segmentation based on SAR satellite imagery using hybrid convolutional transformer (ConvTr) networks. We show that our approach outperforms classical convolutional networks, while being considerably more efficient than pure transformer models. ConvTr obtained a mean intersection over union (mIoU) of 63.68% on the AI4Arctic data set, assuming an inference time of 120ms for a 400 x 400 squared km product.
Dynamic Geometry-Based Stochastic Channel Modeling for Polarized MIMO Systems with Moving Scatterers
Jun 07, 2023This paper introduces a four-dimensional (4D) geometry-based stochastic model (GBSM) for polarized multiple-input multiple-output (MIMO) systems with moving scatterers. We propose a novel motion path model with high degrees of freedom based on the Brownian Motion (BM) random process for randomly moving scatterers. This model is capable of analyzing the effect of both deterministically and randomly moving scatterers on channel properties. The mixture of Von Mises Fisher (VMF) distribution is considered for scatterers resulting in a more general and practical model. The proposed motion path model is applied to the clusters of scatterers with the mixture of VMF distribution, and a closed form formula for calculating space time correlation function (STCF) is achieved, allowing the study of the behavior of channel correlation and channel capacity in the time domain with the presence of stationary and moving scatterers. To obtain numerical results for channel capacity, we employed Monte Carlo simulation method for channel realization purpose. The impact of moving scatterers on the performance of polarized MIMO systems is evaluated using 2 by 2 MIMO configurations with various dual polarizations, i.e. V/V, V/H, and slanted 45{\deg} polarizations for different signal-to-noise (SNR) regimes. The proposed motion path model can be applied to study various dynamic systems with moving objects. The presented process and achieved formula are general and can be applied to polarized MIMO systems with any arbitrary number of antennas and polarizations.
Few-shot bioacoustic event detection at the DCASE 2023 challenge
Jun 15, 2023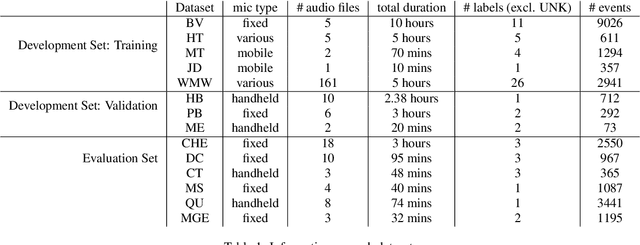
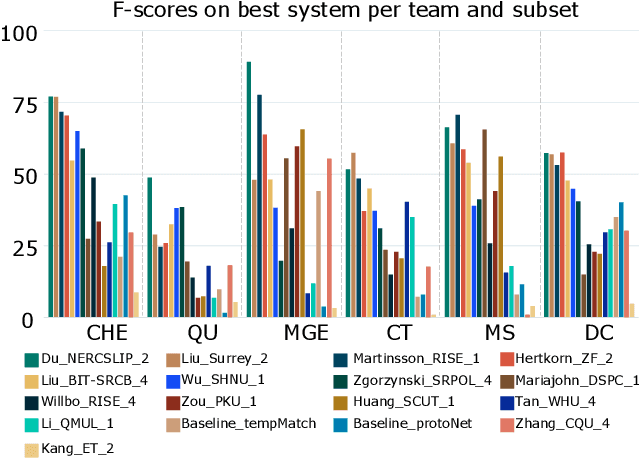
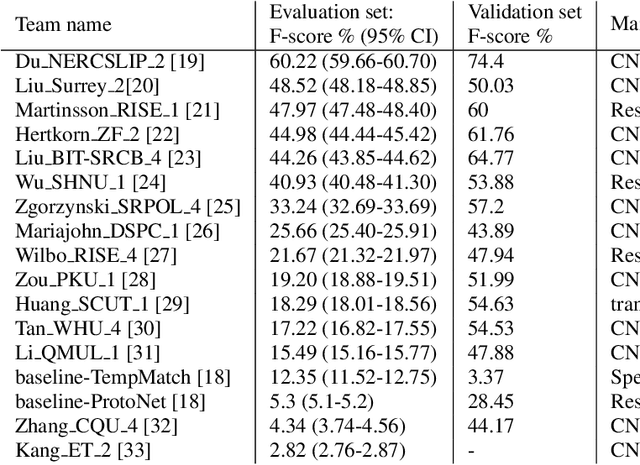
Few-shot bioacoustic event detection consists in detecting sound events of specified types, in varying soundscapes, while having access to only a few examples of the class of interest. This task ran as part of the DCASE challenge for the third time this year with an evaluation set expanded to include new animal species, and a new rule: ensemble models were no longer allowed. The 2023 few shot task received submissions from 6 different teams with F-scores reaching as high as 63% on the evaluation set. Here we describe the task, focusing on describing the elements that differed from previous years. We also take a look back at past editions to describe how the task has evolved. Not only have the F-score results steadily improved (40% to 60% to 63%), but the type of systems proposed have also become more complex. Sound event detection systems are no longer simple variations of the baselines provided: multiple few-shot learning methodologies are still strong contenders for the task.
Fast Training of Diffusion Models with Masked Transformers
Jun 15, 2023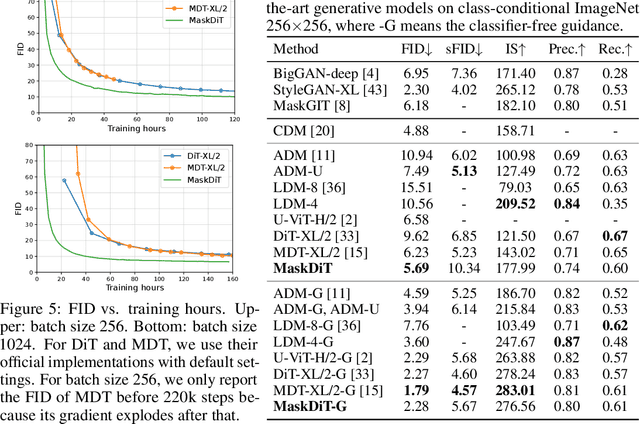
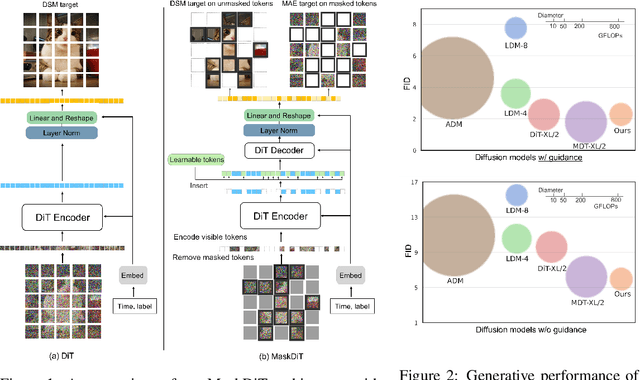
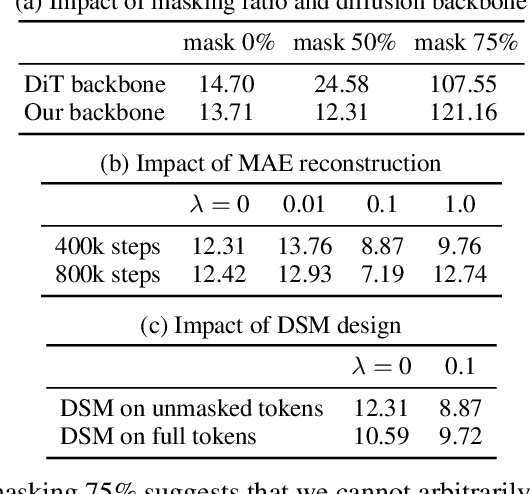

We propose an efficient approach to train large diffusion models with masked transformers. While masked transformers have been extensively explored for representation learning, their application to generative learning is less explored in the vision domain. Our work is the first to exploit masked training to reduce the training cost of diffusion models significantly. Specifically, we randomly mask out a high proportion (\emph{e.g.}, 50\%) of patches in diffused input images during training. For masked training, we introduce an asymmetric encoder-decoder architecture consisting of a transformer encoder that operates only on unmasked patches and a lightweight transformer decoder on full patches. To promote a long-range understanding of full patches, we add an auxiliary task of reconstructing masked patches to the denoising score matching objective that learns the score of unmasked patches. Experiments on ImageNet-256$\times$256 show that our approach achieves the same performance as the state-of-the-art Diffusion Transformer (DiT) model, using only 31\% of its original training time. Thus, our method allows for efficient training of diffusion models without sacrificing the generative performance.
Attention-based Open RAN Slice Management using Deep Reinforcement Learning
Jun 15, 2023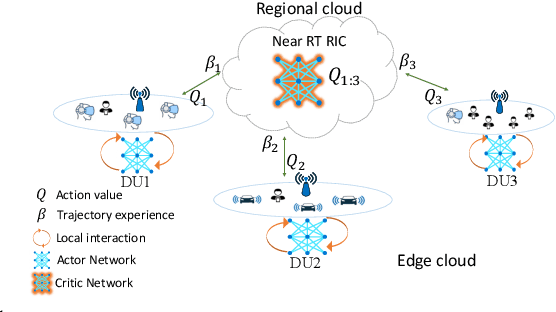
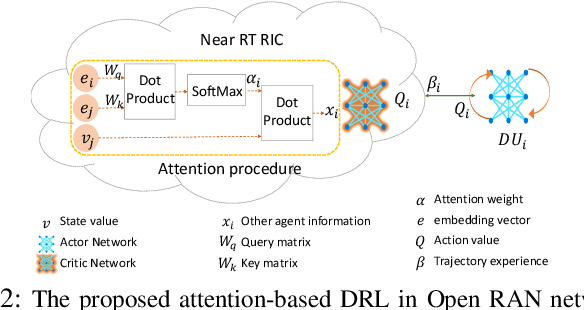
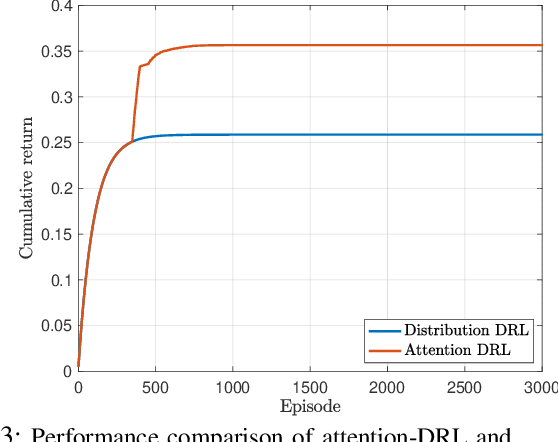
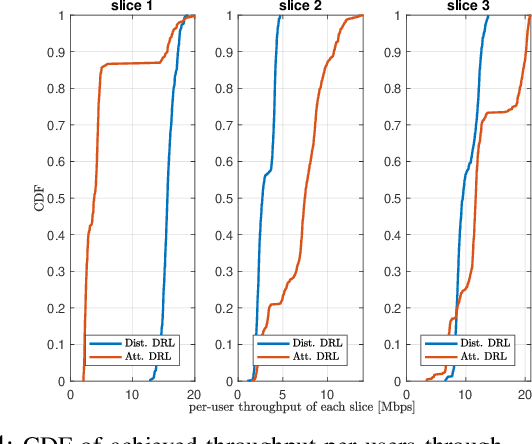
As emerging networks such as Open Radio Access Networks (O-RAN) and 5G continue to grow, the demand for various services with different requirements is increasing. Network slicing has emerged as a potential solution to address the different service requirements. However, managing network slices while maintaining quality of services (QoS) in dynamic environments is a challenging task. Utilizing machine learning (ML) approaches for optimal control of dynamic networks can enhance network performance by preventing Service Level Agreement (SLA) violations. This is critical for dependable decision-making and satisfying the needs of emerging networks. Although RL-based control methods are effective for real-time monitoring and controlling network QoS, generalization is necessary to improve decision-making reliability. This paper introduces an innovative attention-based deep RL (ADRL) technique that leverages the O-RAN disaggregated modules and distributed agent cooperation to achieve better performance through effective information extraction and implementing generalization. The proposed method introduces a value-attention network between distributed agents to enable reliable and optimal decision-making. Simulation results demonstrate significant improvements in network performance compared to other DRL baseline methods.