 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contextual Dynamic Pricing with Strategic Buyers
Jul 08, 2023
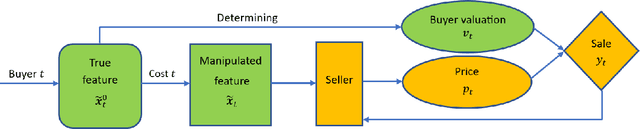
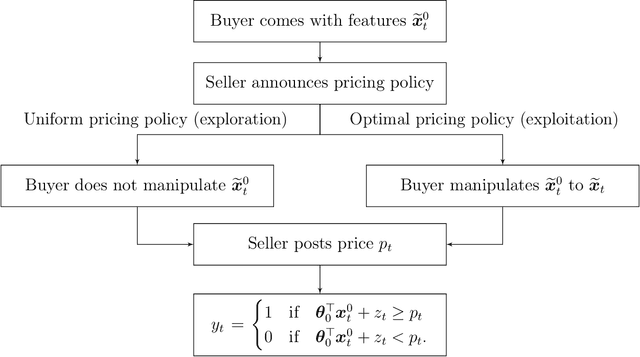
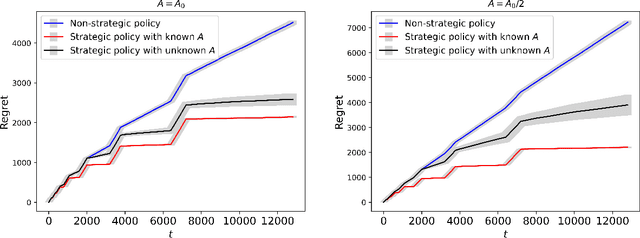
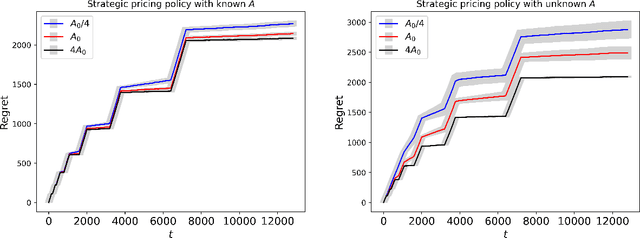
Personalized pricing, which involves tailoring prices based on individual characteristics, is commonly used by firms to implement a consumer-specific pricing policy. In this process, buyers can also strategically manipulate their feature data to obtain a lower price, incurring certain manipulation costs. Such strategic behavior can hinder firms from maximizing their profits. In this paper, we study the contextual dynamic pricing problem with strategic buyers. The seller does not observe the buyer's true feature, but a manipulated feature according to buyers' strategic behavior. In addition, the seller does not observe the buyers' valuation of the product, but only a binary response indicating whether a sale happens or not. Recognizing these challenges, we propose a strategic dynamic pricing policy that incorporates the buyers' strategic behavior into the online learning to maximize the seller's cumulative revenue. We first prove that existing non-strategic pricing policies that neglect the buyers' strategic behavior result in a linear $\Omega(T)$ regret with $T$ the total time horizon, indicating that these policies are not better than a random pricing policy. We then establish that our proposed policy achieves a sublinear regret upper bound of $O(\sqrt{T})$. Importantly, our policy is not a mere amalgamation of existing dynamic pricing policies and strategic behavior handling algorithms. Our policy can also accommodate the scenario when the marginal cost of manipulation is unknown in advance. To account for it, we simultaneously estimate the valuation parameter and the cost parameter in the online pricing policy, which is shown to also achieve an $O(\sqrt{T})$ regret bound. Extensive experiments support our theoretical developments and demonstrate the superior performance of our policy compared to other pricing policies that are unaware of the strategic behaviors.
Meta contrastive label correction for financial time series
Mar 09, 2023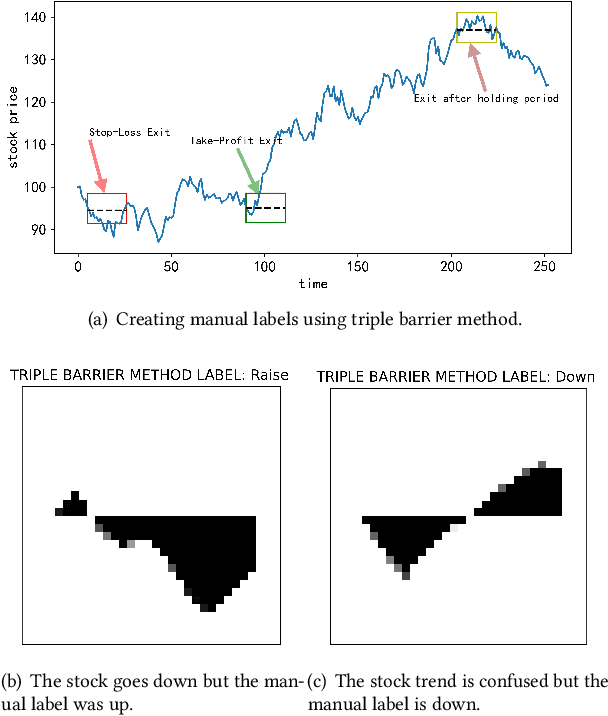
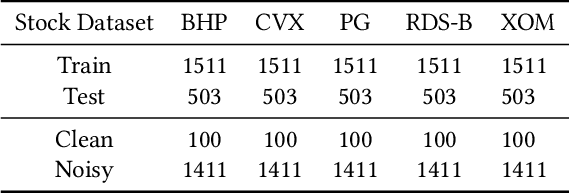
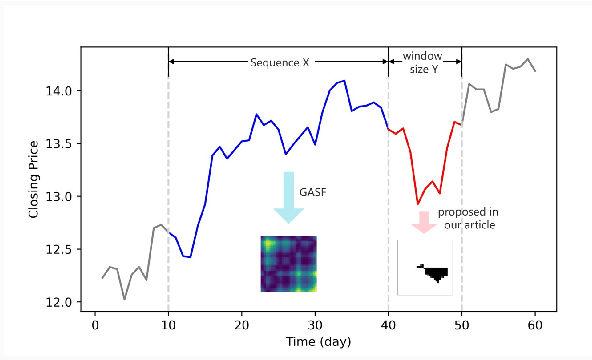

Financial applications such as stock price forecasting, usually face an issue that under the predefined labeling rules, it is hard to accurately predict the directions of stock movement. This is because traditional ways of labeling, taking Triple Barrier Method, for example, usually gives us inaccurate or even corrupted labels. To address this issue, we focus on two main goals. One is that our proposed method can automatically generate correct labels for noisy time series patterns, while at the same time, the method is capable of boosting classification performance on this new labeled dataset. Based on the aforementioned goals, our approach has the following three novelties: First, we fuse a new contrastive learning algorithm into the meta-learning framework to estimate correct labels iteratively when updating the classification model inside. Moreover, we utilize images generated from time series data through Gramian angular field and representative learning. Most important of all, we adopt multi-task learning to forecast temporal-variant labels. In the experiments, we work on 6% clean data and the rest unlabeled data. It is shown that our method is competitive and outperforms a lot compared with benchmarks.
Discrete-time Competing-Risks Regression with or without Penalization
Mar 02, 2023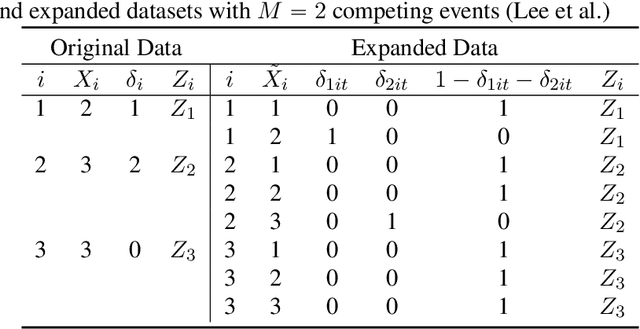
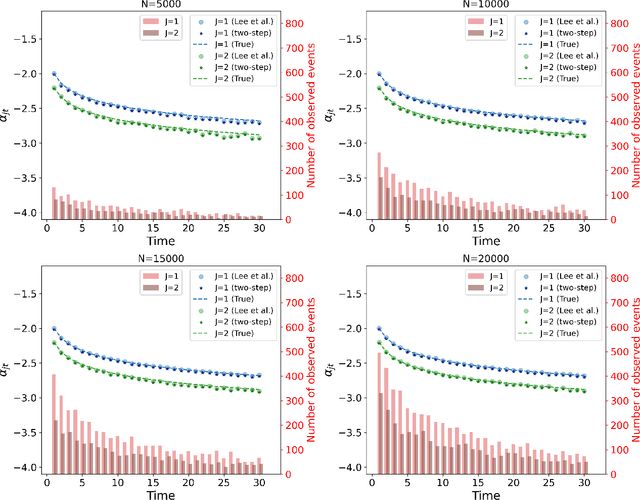
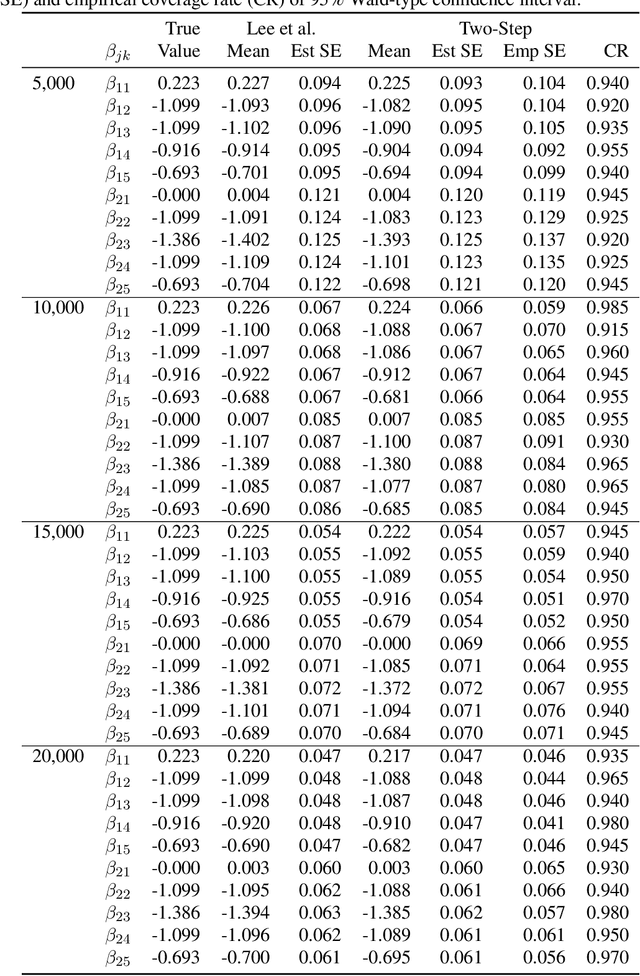
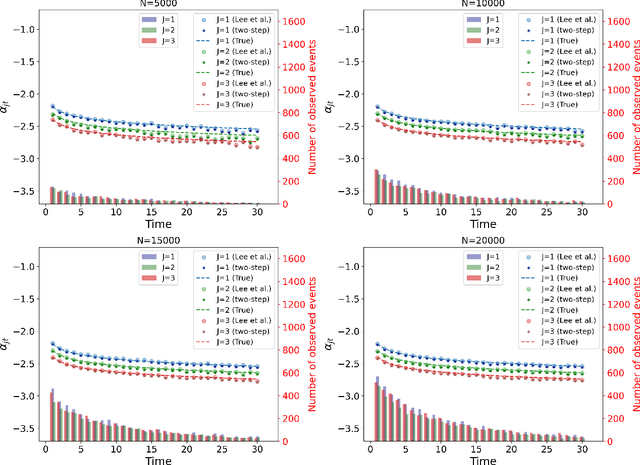
Many studies employ the analysis of time-to-event data that incorporates competing risks and right censoring. Most methods and software packages are geared towards analyzing data that comes from a continuous failure time distribution. However, failure-time data may sometimes be discrete either because time is inherently discrete or due to imprecise measurement. This paper introduces a novel estimation procedure for discrete-time survival analysis with competing events. The proposed approach offers two key advantages over existing procedures: first, it accelerates the estimation process; second, it allows for straightforward integration and application of widely used regularized regression and screening methods. We illustrate the benefits of our proposed approach by conducting a comprehensive simulation study. Additionally, we showcase the utility of our procedure by estimating a survival model for the length of stay of patients hospitalized in the intensive care unit, considering three competing events: discharge to home, transfer to another medical facility, and in-hospital death.
Robust Dominant Periodicity Detection for Time Series with Missing Data
Mar 06, 2023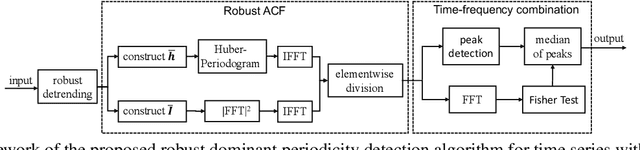
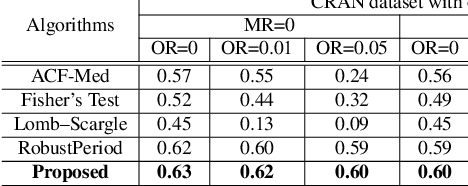
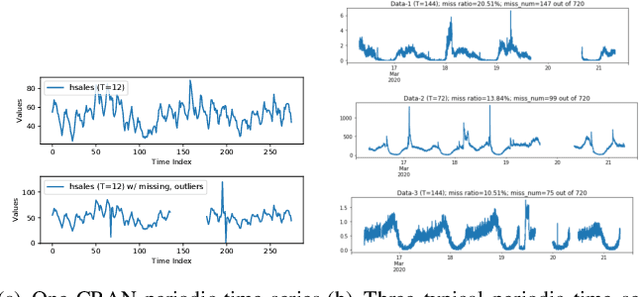
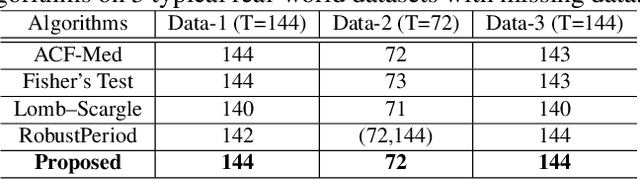
Periodicity detection is an important task in time series analysis, but still a challenging problem due to the diverse characteristics of time series data like abrupt trend change, outlier, noise, and especially block missing data. In this paper, we propose a robust and effective periodicity detection algorithm for time series with block missing data. We first design a robust trend filter to remove the interference of complicated trend patterns under missing data. Then, we propose a robust autocorrelation function (ACF) that can handle missing values and outliers effectively. We rigorously prove that the proposed robust ACF can still work well when the length of the missing block is less than $1/3$ of the period length. Last, by combining the time-frequency information, our algorithm can generate the period length accurately. The experimental results demonstrate that our algorithm outperforms existing periodicity detection algorithms on real-world time series datasets.
* Accepted by 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023)
Theoretical Guarantees of Learning Ensembling Strategies with Applications to Time Series Forecasting
May 26, 2023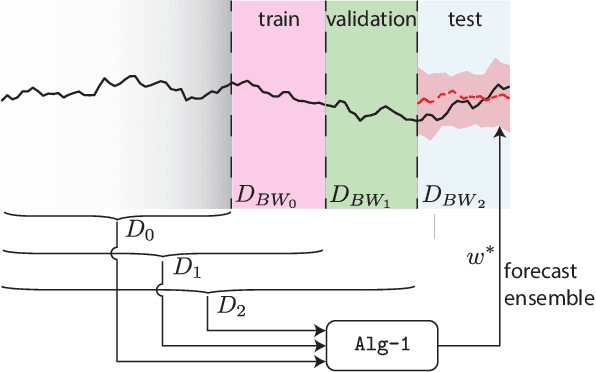
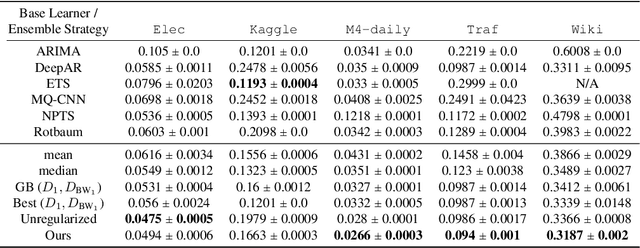
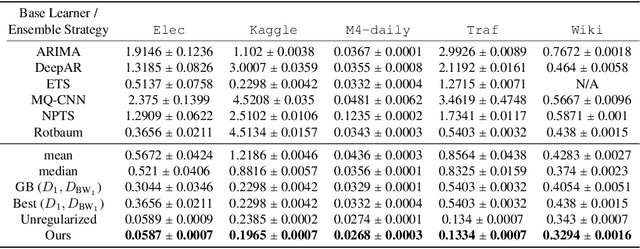
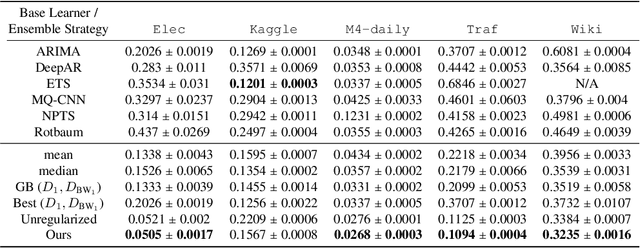
Ensembling is among the most popular tools in machine learning (ML) due to its effectiveness in minimizing variance and thus improving generalization. Most ensembling methods for black-box base learners fall under the umbrella of "stacked generalization," namely training an ML algorithm that takes the inferences from the base learners as input. While stacking has been widely applied in practice, its theoretical properties are poorly understood. In this paper, we prove a novel result, showing that choosing the best stacked generalization from a (finite or finite-dimensional) family of stacked generalizations based on cross-validated performance does not perform "much worse" than the oracle best. Our result strengthens and significantly extends the results in Van der Laan et al. (2007). Inspired by the theoretical analysis, we further propose a particular family of stacked generalizations in the context of probabilistic forecasting, each one with a different sensitivity for how much the ensemble weights are allowed to vary across items, timestamps in the forecast horizon, and quantiles. Experimental results demonstrate the performance gain of the proposed method.
LLM-Assisted Content Analysis: Using Large Language Models to Support Deductive Coding
Jun 23, 2023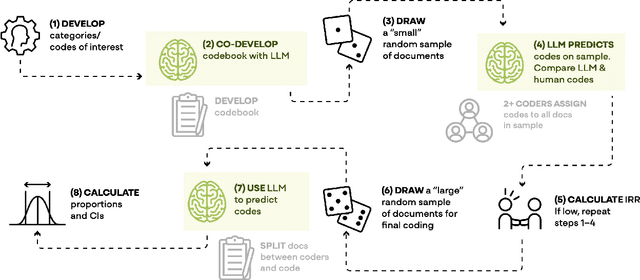
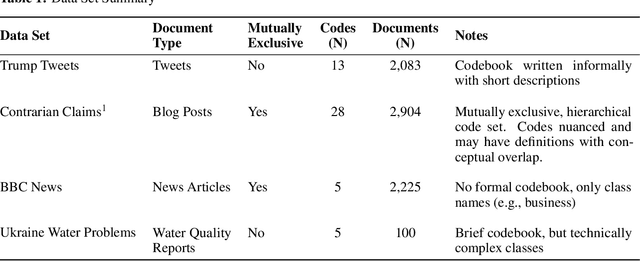
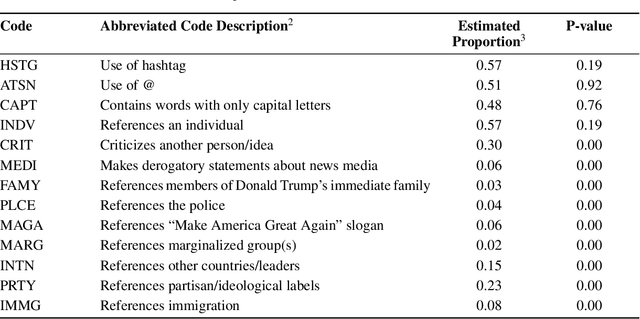

Deductive coding is a widely used qualitative research method for determining the prevalence of themes across documents. While useful, deductive coding is often burdensome and time consuming since it requires researchers to read, interpret, and reliably categorize a large body of unstructured text documents. Large language models (LLMs), like ChatGPT, are a class of quickly evolving AI tools that can perform a range of natural language processing and reasoning tasks. In this study, we explore the use of LLMs to reduce the time it takes for deductive coding while retaining the flexibility of a traditional content analysis. We outline the proposed approach, called LLM-assisted content analysis (LACA), along with an in-depth case study using GPT-3.5 for LACA on a publicly available deductive coding data set. Additionally, we conduct an empirical benchmark using LACA on 4 publicly available data sets to assess the broader question of how well GPT-3.5 performs across a range of deductive coding tasks. Overall, we find that GPT-3.5 can often perform deductive coding at levels of agreement comparable to human coders. Additionally, we demonstrate that LACA can help refine prompts for deductive coding, identify codes for which an LLM is randomly guessing, and help assess when to use LLMs vs. human coders for deductive coding. We conclude with several implications for future practice of deductive coding and related research methods.
Geometric Algorithms for $k$-NN Poisoning
Jun 21, 2023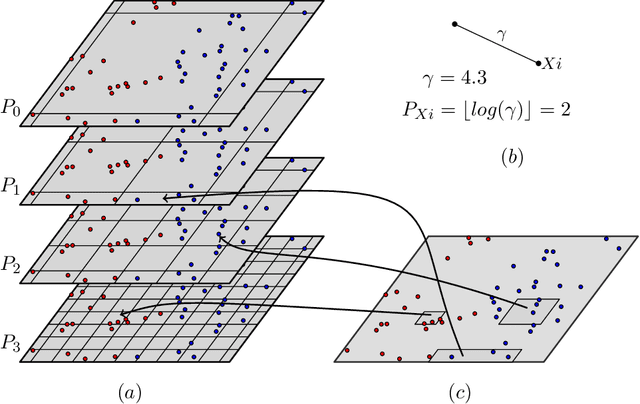
We propose a label poisoning attack on geometric data sets against $k$-nearest neighbor classification. We provide an algorithm that can compute an $\varepsilon n$-additive approximation of the optimal poisoning in $n\cdot 2^{2^{O(d+k/\varepsilon)}}$ time for a given data set $X \in \mathbb{R}^d$, where $|X| = n$. Our algorithm achieves its objectives through the application of multi-scale random partitions.
Nearest Neighbour with Bandit Feedback
Jun 23, 2023In this paper we adapt the nearest neighbour rule to the contextual bandit problem. Our algorithm handles the fully adversarial setting in which no assumptions at all are made about the data-generation process. When combined with a sufficiently fast data-structure for (perhaps approximate) adaptive nearest neighbour search, such as a navigating net, our algorithm is extremely efficient - having a per trial running time polylogarithmic in both the number of trials and actions, and taking only quasi-linear space.
Variational quantum regression algorithm with encoded data structure
Jul 07, 2023Variational quantum algorithms (VQAs) prevail to solve practical problems such as combinatorial optimization, quantum chemistry simulation, quantum machine learning, and quantum error correction on noisy quantum computers. For variational quantum machine learning, a variational algorithm with model interpretability built into the algorithm is yet to be exploited. In this paper, we construct a quantum regression algorithm and identify the direct relation of variational parameters to learned regression coefficients, while employing a circuit that directly encodes the data in quantum amplitudes reflecting the structure of the classical data table. The algorithm is particularly suitable for well-connected qubits. With compressed encoding and digital-analog gate operation, the run time complexity is logarithmically more advantageous than that for digital 2-local gate native hardware with the number of data entries encoded, a decent improvement in noisy intermediate-scale quantum computers and a minor improvement for large-scale quantum computing Our suggested method of compressed binary encoding offers a remarkable reduction in the number of physical qubits needed when compared to the traditional one-hot-encoding technique with the same input data. The algorithm inherently performs linear regression but can also be used easily for nonlinear regression by building nonlinear features into the training data. In terms of measured cost function which distinguishes a good model from a poor one for model training, it will be effective only when the number of features is much less than the number of records for the encoded data structure to be observable. To echo this finding and mitigate hardware noise in practice, the ensemble model training from the quantum regression model learning with important feature selection from regularization is incorporated and illustrated numerically.
Land Cover Segmentation with Sparse Annotations from Sentinel-2 Imagery
Jun 28, 2023

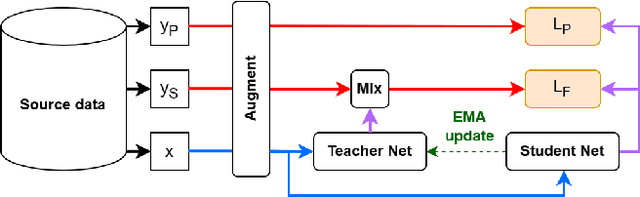
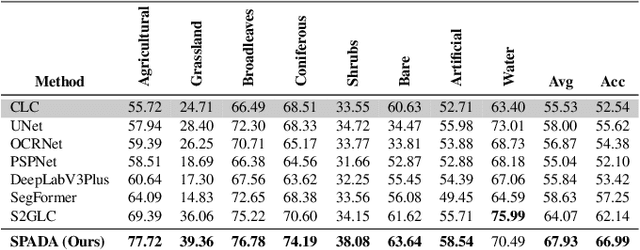
Land cover (LC) segmentation plays a critical role in various applications, including environmental analysis and natural disaster management. However, generating accurate LC maps is a complex and time-consuming task that requires the expertise of multiple annotators and regular updates to account for environmental changes. In this work, we introduce SPADA, a framework for fuel map delineation that addresses the challenges associated with LC segmentation using sparse annotations and domain adaptation techniques for semantic segmentation. Performance evaluations using reliable ground truths, such as LUCAS and Urban Atlas, demonstrate the technique's effectiveness. SPADA outperforms state-of-the-art semantic segmentation approaches as well as third-party products, achieving a mean Intersection over Union (IoU) score of 42.86 and an F1 score of 67.93 on Urban Atlas and LUCAS, respectively.