 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
Analysis and modeling to forecast in time series: a systematic review
Mar 31, 2021
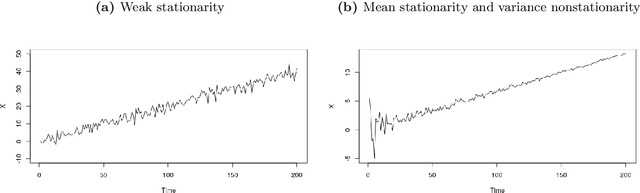

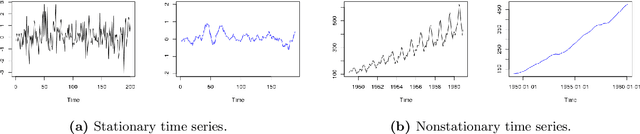
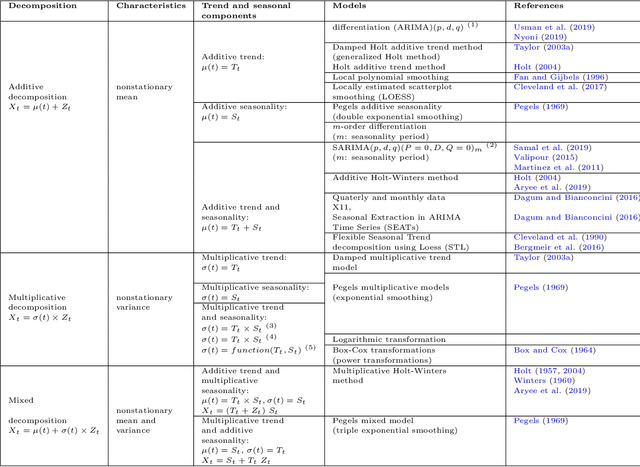
This paper surveys state-of-the-art methods and models dedicated to time series analysis and modeling, with the final aim of prediction. This review aims to offer a structured and comprehensive view of the full process flow, and encompasses time series decomposition, stationary tests, modeling and forecasting. Besides, to meet didactic purposes, a unified presentation has been adopted throughout this survey, to present decomposition frameworks on the one hand and linear and nonlinear time series models on the other hand. First, we decrypt the relationships between stationarity and linearity, and further examine the main classes of methods used to test for weak stationarity. Next, the main frameworks for time series decomposition are presented in a unified way: depending on the time series, a more or less complex decomposition scheme seeks to obtain nonstationary effects (the deterministic components) and a remaining stochastic component. An appropriate modeling of the latter is a critical step to guarantee prediction accuracy. We then present three popular linear models, together with two more flexible variants of the latter. A step further in model complexity, and still in a unified way, we present five major nonlinear models used for time series. Amongst nonlinear models, artificial neural networks hold a place apart as deep learning has recently gained considerable attention. A whole section is therefore dedicated to time series forecasting relying on deep learning approaches. A final section provides a list of R and Python implementations for the methods, models and tests presented throughout this review. In this document, our intention is to bring sufficient in-depth knowledge, while covering a broad range of models and forecasting methods: this compilation spans from well-established conventional approaches to more recent adaptations of deep learning to time series forecasting.
The Connection between Discrete- and Continuous-Time Descriptions of Gaussian Continuous Processes
Jan 20, 2021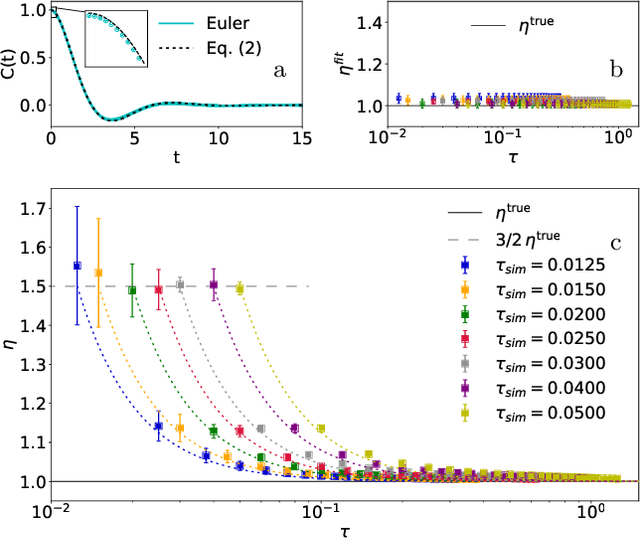
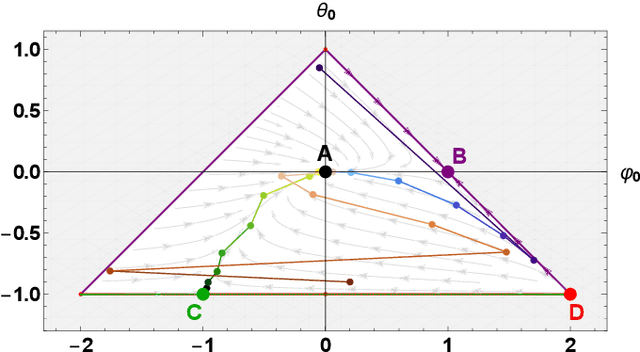

Learning the continuous equations of motion from discrete observations is a common task in all areas of physics. However, not any discretization of a Gaussian continuous-time stochastic process can be adopted in parametric inference. We show that discretizations yielding consistent estimators have the property of `invariance under coarse-graining', and correspond to fixed points of a renormalization group map on the space of autoregressive moving average (ARMA) models (for linear processes). This result explains why combining differencing schemes for derivatives reconstruction and local-in-time inference approaches does not work for time series analysis of second or higher order stochastic differential equations, even if the corresponding integration schemes may be acceptably good for numerical simulations.
Time Series is a Special Sequence: Forecasting with Sample Convolution and Interaction
Jun 17, 2021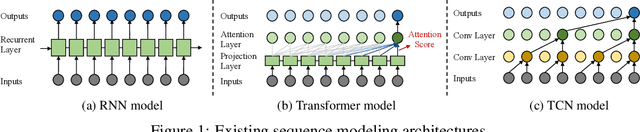

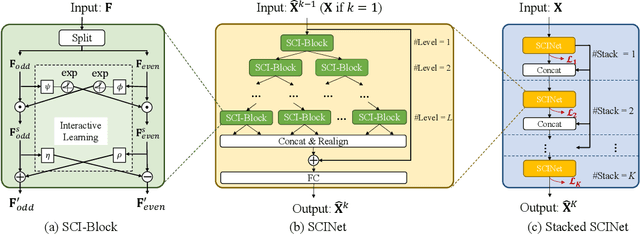
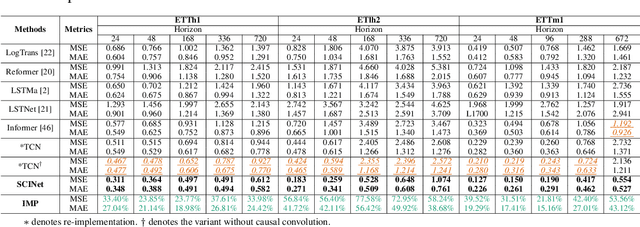
Time series is a special type of sequence data, a set of observations collected at even intervals of time and ordered chronologically. Existing deep learning techniques use generic sequence models (e.g., recurrent neural network, Transformer model, or temporal convolutional network) for time series analysis, which ignore some of its unique properties. For example, the downsampling of time series data often preserves most of the information in the data, while this is not true for general sequence data such as text sequence and DNA sequence. Motivated by the above, in this paper, we propose a novel neural network architecture and apply it for the time series forecasting problem, wherein we conduct sample convolution and interaction at multiple resolutions for temporal modeling. The proposed architecture, namelySCINet, facilitates extracting features with enhanced predictability. Experimental results show that SCINet achieves significant prediction accuracy improvement over existing solutions across various real-world time series forecasting datasets. In particular, it can achieve high fore-casting accuracy for those temporal-spatial datasets without using sophisticated spatial modeling techniques. Our codes and data are presented in the supplemental material.
Don't overfit the history -- Recursive time series data augmentation
Jul 06, 2022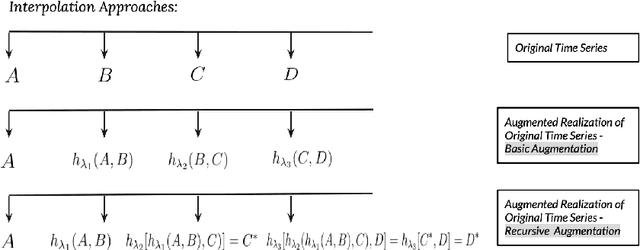

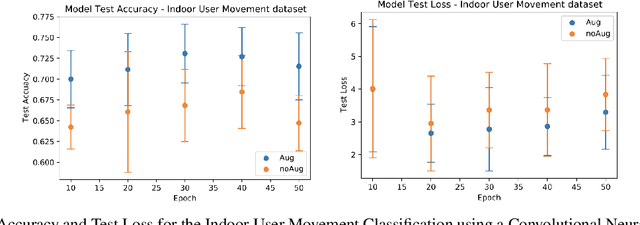
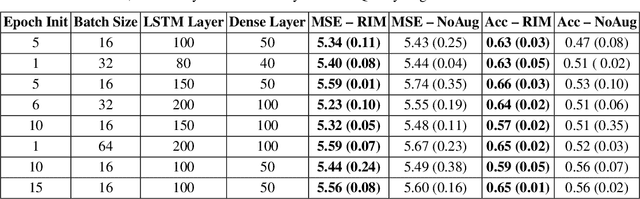
Time series observations can be seen as realizations of an underlying dynamical system governed by rules that we typically do not know. For time series learning tasks, we need to understand that we fit our model on available data, which is a unique realized history. Training on a single realization often induces severe overfitting lacking generalization. To address this issue, we introduce a general recursive framework for time series augmentation, which we call Recursive Interpolation Method, denoted as RIM. New samples are generated using a recursive interpolation function of all previous values in such a way that the enhanced samples preserve the original inherent time series dynamics. We perform theoretical analysis to characterize the proposed RIM and to guarantee its test performance. We apply RIM to diverse real world time series cases to achieve strong performance over non-augmented data on regression, classification, and reinforcement learning tasks.
A prediction perspective on the Wiener-Hopf equations for discrete time series
Jul 11, 2021The Wiener-Hopf equations are a Toeplitz system of linear equations that have several applications in time series. These include the update and prediction step of the stationary Kalman filter equations and the prediction of bivariate time series. The Wiener-Hopf technique is the classical tool for solving the equations, and is based on a comparison of coefficients in a Fourier series expansion. The purpose of this note is to revisit the (discrete) Wiener-Hopf equations and obtain an alternative expression for the solution that is more in the spirit of time series analysis. Specifically, we propose a solution to the Wiener-Hopf equations that combines linear prediction with deconvolution. The solution of the Wiener-Hopf equations requires one to obtain the spectral factorization of the underlying spectral density function. For general spectral density functions this is infeasible. Therefore, it is usually assumed that the spectral density is rational, which allows one to obtain a computationally tractable solution. This leads to an approximation error when the underlying spectral density is not a rational function. We use the proposed solution together with Baxter's inequality to derive an error bound for the rational spectral density approximation.
Attend and Diagnose: Clinical Time Series Analysis using Attention Models
Nov 19, 2017
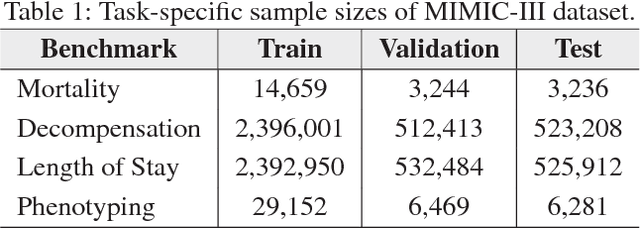
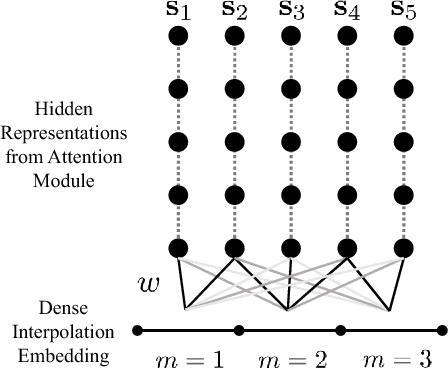
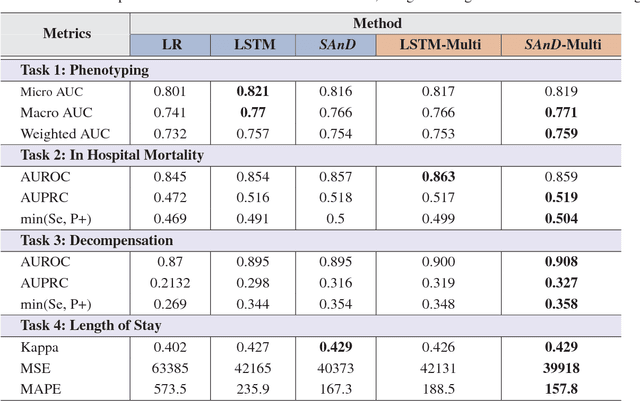
With widespread adoption of electronic health records, there is an increased emphasis for predictive models that can effectively deal with clinical time-series data. Powered by Recurrent Neural Network (RNN) architectures with Long Short-Term Memory (LSTM) units, deep neural networks have achieved state-of-the-art results in several clinical prediction tasks. Despite the success of RNNs, its sequential nature prohibits parallelized computing, thus making it inefficient particularly when processing long sequences. Recently, architectures which are based solely on attention mechanisms have shown remarkable success in transduction tasks in NLP, while being computationally superior. In this paper, for the first time, we utilize attention models for clinical time-series modeling, thereby dispensing recurrence entirely. We develop the \textit{SAnD} (Simply Attend and Diagnose) architecture, which employs a masked, self-attention mechanism, and uses positional encoding and dense interpolation strategies for incorporating temporal order. Furthermore, we develop a multi-task variant of \textit{SAnD} to jointly infer models with multiple diagnosis tasks. Using the recent MIMIC-III benchmark datasets, we demonstrate that the proposed approach achieves state-of-the-art performance in all tasks, outperforming LSTM models and classical baselines with hand-engineered features.
Transfer Learning for Clinical Time Series Analysis using Recurrent Neural Networks
Jul 04, 2018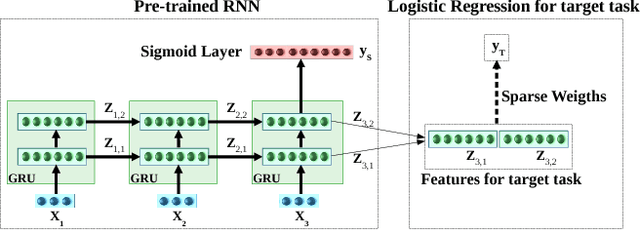

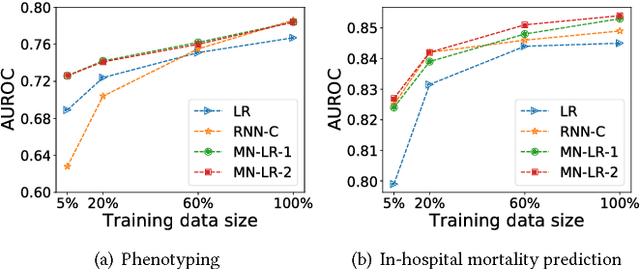

Deep neural networks have shown promising results for various clinical prediction tasks such as diagnosis, mortality prediction, predicting duration of stay in hospital, etc. However, training deep networks -- such as those based on Recurrent Neural Networks (RNNs) -- requires large labeled data, high computational resources, and significant hyperparameter tuning effort. In this work, we investigate as to what extent can transfer learning address these issues when using deep RNNs to model multivariate clinical time series. We consider transferring the knowledge captured in an RNN trained on several source tasks simultaneously using a large labeled dataset to build the model for a target task with limited labeled data. An RNN pre-trained on several tasks provides generic features, which are then used to build simpler linear models for new target tasks without training task-specific RNNs. For evaluation, we train a deep RNN to identify several patient phenotypes on time series from MIMIC-III database, and then use the features extracted using that RNN to build classifiers for identifying previously unseen phenotypes, and also for a seemingly unrelated task of in-hospital mortality. We demonstrate that (i) models trained on features extracted using pre-trained RNN outperform or, in the worst case, perform as well as task-specific RNNs; (ii) the models using features from pre-trained models are more robust to the size of labeled data than task-specific RNNs; and (iii) features extracted using pre-trained RNN are generic enough and perform better than typical statistical hand-crafted features.
A Novel Deep Reinforcement Learning Based Stock Direction Prediction using Knowledge Graph and Community Aware Sentiments
Jul 02, 2021

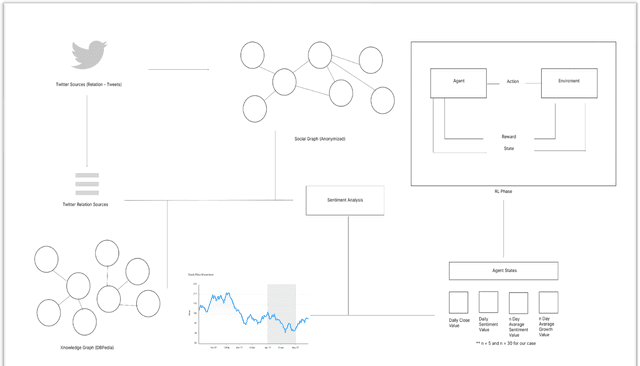
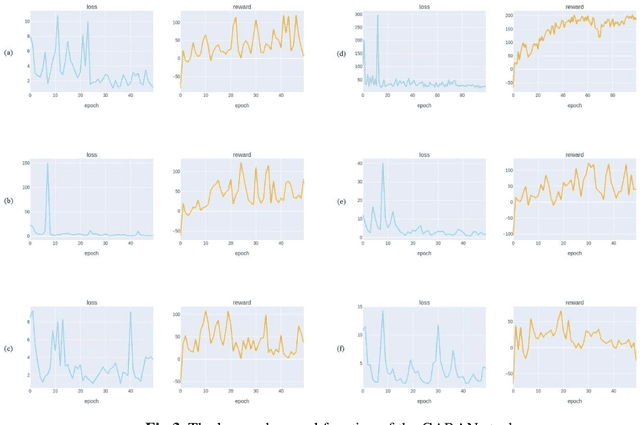
Stock market prediction has been an important topic for investors, researchers, and analysts. Because it is affected by too many factors, stock market prediction is a difficult task to handle. In this study, we propose a novel method that is based on deep reinforcement learning methodologies for the direction prediction of stocks using sentiments of community and knowledge graph. For this purpose, we firstly construct a social knowledge graph of users by analyzing relations between connections. After that, time series analysis of related stock and sentiment analysis is blended with deep reinforcement methodology. Turkish version of Bidirectional Encoder Representations from Transformers (BerTurk) is employed to analyze the sentiments of the users while deep Q-learning methodology is used for the deep reinforcement learning side of the proposed model to construct the deep Q network. In order to demonstrate the effectiveness of the proposed model, Garanti Bank (GARAN), Akbank (AKBNK), T\"urkiye \.I\c{s} Bankas{\i} (ISCTR) stocks in Istanbul Stock Exchange are used as a case study. Experiment results show that the proposed novel model achieves remarkable results for stock market prediction task.
DTWSSE: Data Augmentation with a Siamese Encoder for Time Series
Aug 23, 2021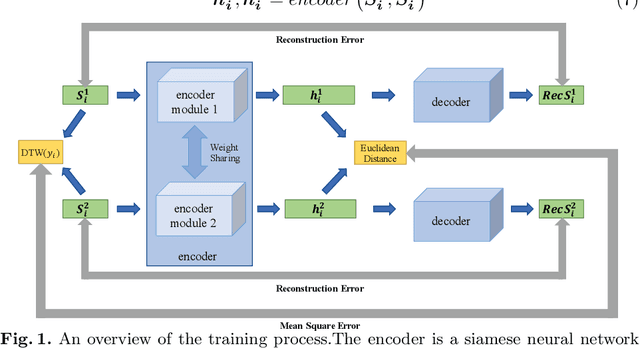
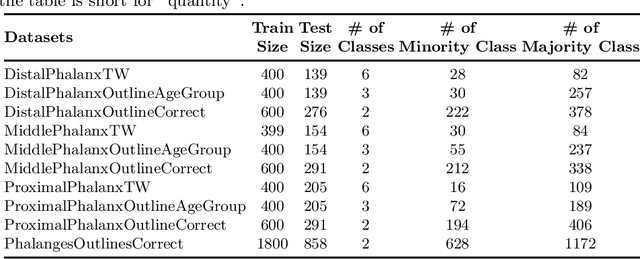
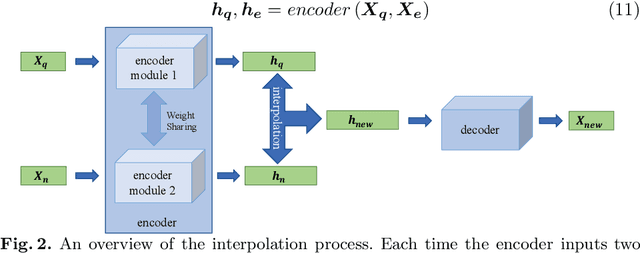
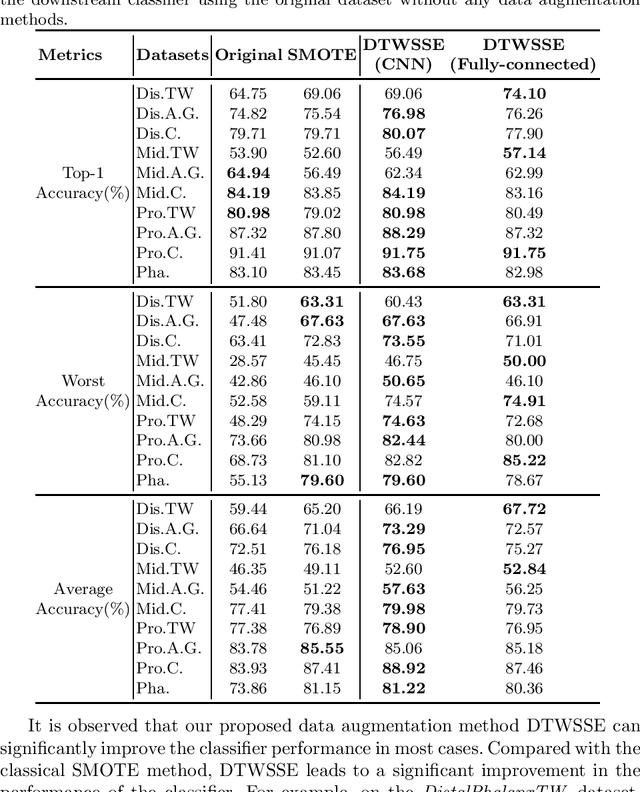
Access to labeled time series data is often limited in the real world, which constrains the performance of deep learning models in the field of time series analysis. Data augmentation is an effective way to solve the problem of small sample size and imbalance in time series datasets. The two key factors of data augmentation are the distance metric and the choice of interpolation method. SMOTE does not perform well on time series data because it uses a Euclidean distance metric and interpolates directly on the object. Therefore, we propose a DTW-based synthetic minority oversampling technique using siamese encoder for interpolation named DTWSSE. In order to reasonably measure the distance of the time series, DTW, which has been verified to be an effective method forts, is employed as the distance metric. To adapt the DTW metric, we use an autoencoder trained in an unsupervised self-training manner for interpolation. The encoder is a Siamese Neural Network for mapping the time series data from the DTW hidden space to the Euclidean deep feature space, and the decoder is used to map the deep feature space back to the DTW hidden space. We validate the proposed methods on a number of different balanced or unbalanced time series datasets. Experimental results show that the proposed method can lead to better performance of the downstream deep learning model.