 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Tracking electricity losses and their perceived causes using nighttime light and social media
Oct 18, 2023
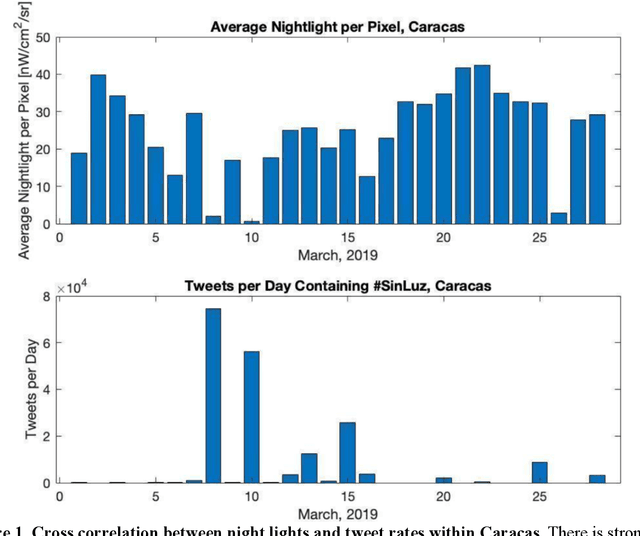
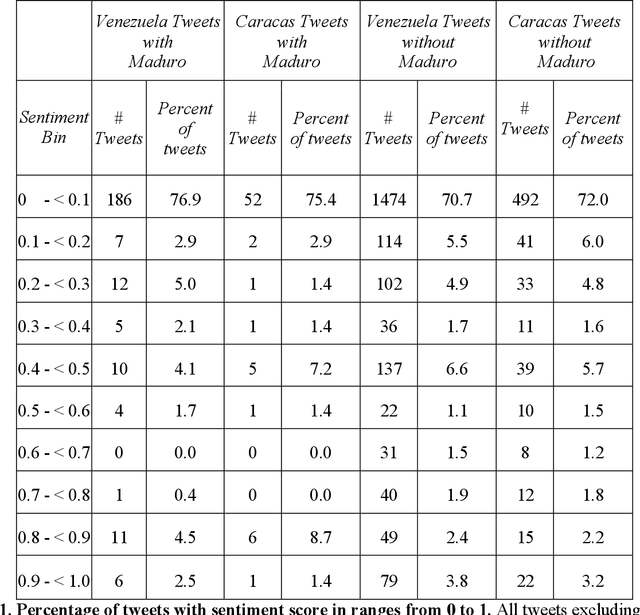

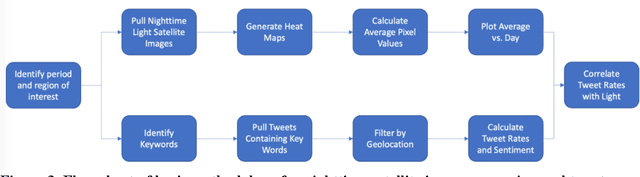
Urban environments are intricate systems where the breakdown of critical infrastructure can impact both the economic and social well-being of communities. Electricity systems hold particular significance, as they are essential for other infrastructure, and disruptions can trigger widespread consequences. Typically, assessing electricity availability requires ground-level data, a challenge in conflict zones and regions with limited access. This study shows how satellite imagery, social media, and information extraction can monitor blackouts and their perceived causes. Night-time light data (in March 2019 for Caracas, Venezuela) is used to indicate blackout regions. Twitter data is used to determine sentiment and topic trends, while statistical analysis and topic modeling delved into public perceptions regarding blackout causes. The findings show an inverse relationship between nighttime light intensity. Tweets mentioning the Venezuelan President displayed heightened negativity and a greater prevalence of blame-related terms, suggesting a perception of government accountability for the outages.
Cross-Attention is Not Enough: Incongruity-Aware Multimodal Sentiment Analysis and Emotion Recognition
May 23, 2023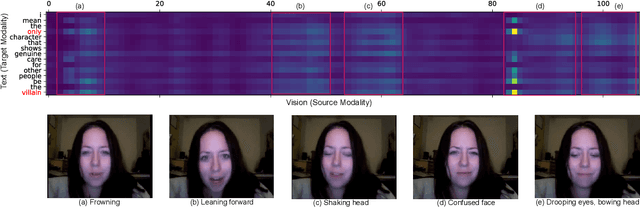


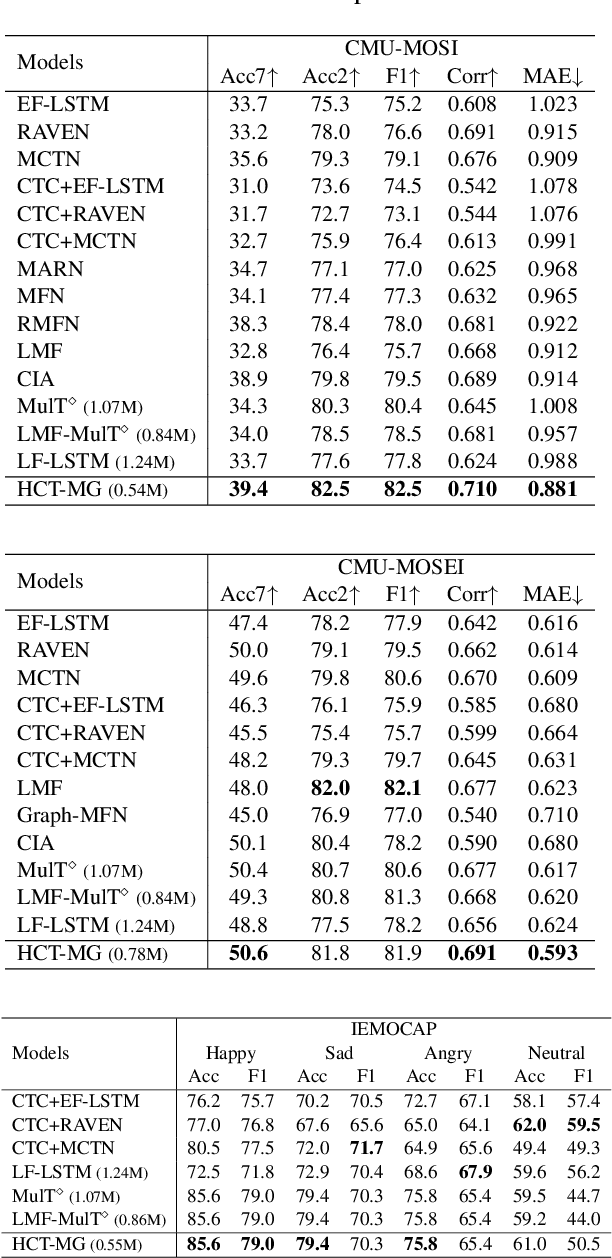
Fusing multiple modalities for affective computing tasks has proven effective for performance improvement. However, how multimodal fusion works is not well understood, and its use in the real world usually results in large model sizes. In this work, on sentiment and emotion analysis, we first analyze how the salient affective information in one modality can be affected by the other in crossmodal attention. We find that inter-modal incongruity exists at the latent level due to crossmodal attention. Based on this finding, we propose a lightweight model via Hierarchical Crossmodal Transformer with Modality Gating (HCT-MG), which determines a primary modality according to its contribution to the target task and then hierarchically incorporates auxiliary modalities to alleviate inter-modal incongruity and reduce information redundancy. The experimental evaluation on three benchmark datasets: CMU-MOSI, CMU-MOSEI, and IEMOCAP verifies the efficacy of our approach, showing that it: 1) outperforms major prior work by achieving competitive results and can successfully recognize hard samples; 2) mitigates the inter-modal incongruity at the latent level when modalities have mismatched affective tendencies; 3) reduces model size to less than 1M parameters while outperforming existing models of similar sizes.
A Dataset and BERT-based Models for Targeted Sentiment Analysis on Turkish Texts
May 09, 2022
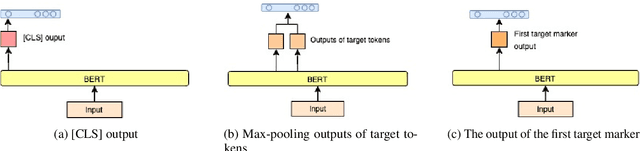


Targeted Sentiment Analysis aims to extract sentiment towards a particular target from a given text. It is a field that is attracting attention due to the increasing accessibility of the Internet, which leads people to generate an enormous amount of data. Sentiment analysis, which in general requires annotated data for training, is a well-researched area for widely studied languages such as English. For low-resource languages such as Turkish, there is a lack of such annotated data. We present an annotated Turkish dataset suitable for targeted sentiment analysis. We also propose BERT-based models with different architectures to accomplish the task of targeted sentiment analysis. The results demonstrate that the proposed models outperform the traditional sentiment analysis models for the targeted sentiment analysis task.
Improving Aspect-Based Sentiment with End-to-End Semantic Role Labeling Model
Jul 27, 2023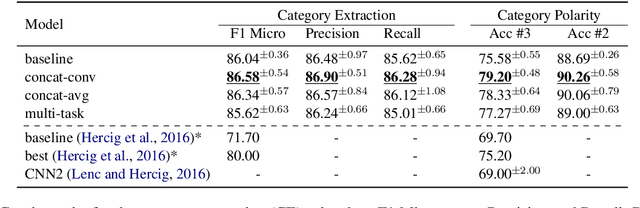
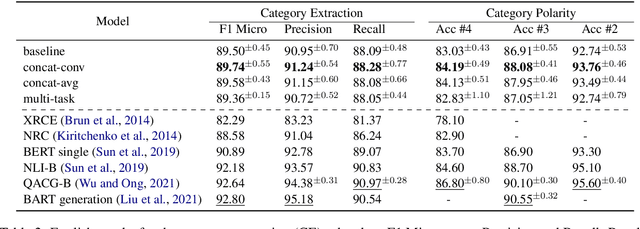
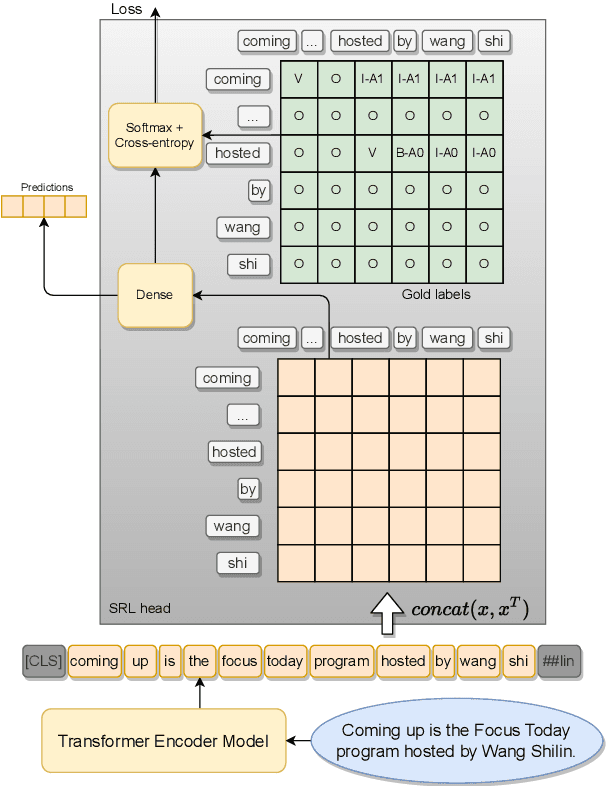
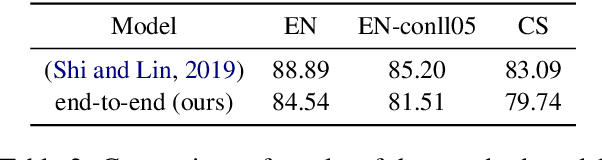
This paper presents a series of approaches aimed at enhancing the performance of Aspect-Based Sentiment Analysis (ABSA) by utilizing extracted semantic information from a Semantic Role Labeling (SRL) model. We propose a novel end-to-end Semantic Role Labeling model that effectively captures most of the structured semantic information within the Transformer hidden state. We believe that this end-to-end model is well-suited for our newly proposed models that incorporate semantic information. We evaluate the proposed models in two languages, English and Czech, employing ELECTRA-small models. Our combined models improve ABSA performance in both languages. Moreover, we achieved new state-of-the-art results on the Czech ABSA.
AX-MABSA: A Framework for Extremely Weakly Supervised Multi-label Aspect Based Sentiment Analysis
Nov 07, 2022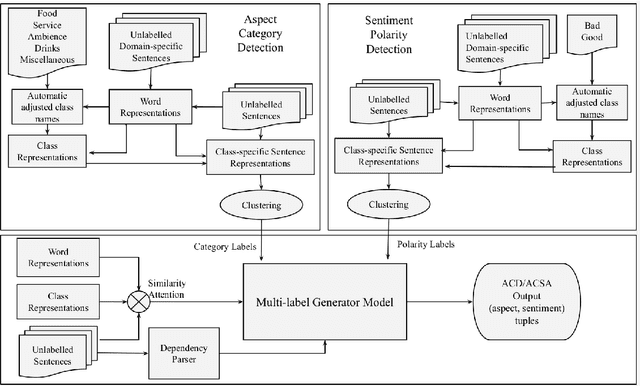
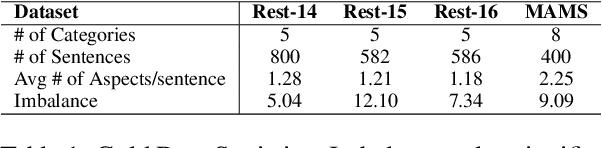

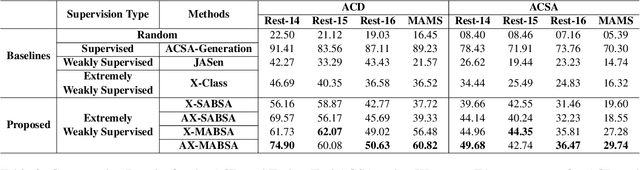
Aspect Based Sentiment Analysis is a dominant research area with potential applications in social media analytics, business, finance, and health. Prior works in this area are primarily based on supervised methods, with a few techniques using weak supervision limited to predicting a single aspect category per review sentence. In this paper, we present an extremely weakly supervised multi-label Aspect Category Sentiment Analysis framework which does not use any labelled data. We only rely on a single word per class as an initial indicative information. We further propose an automatic word selection technique to choose these seed categories and sentiment words. We explore unsupervised language model post-training to improve the overall performance, and propose a multi-label generator model to generate multiple aspect category-sentiment pairs per review sentence. Experiments conducted on four benchmark datasets showcase our method to outperform other weakly supervised baselines by a significant margin.
A Comparative Study on TF-IDF feature Weighting Method and its Analysis using Unstructured Dataset
Aug 08, 2023
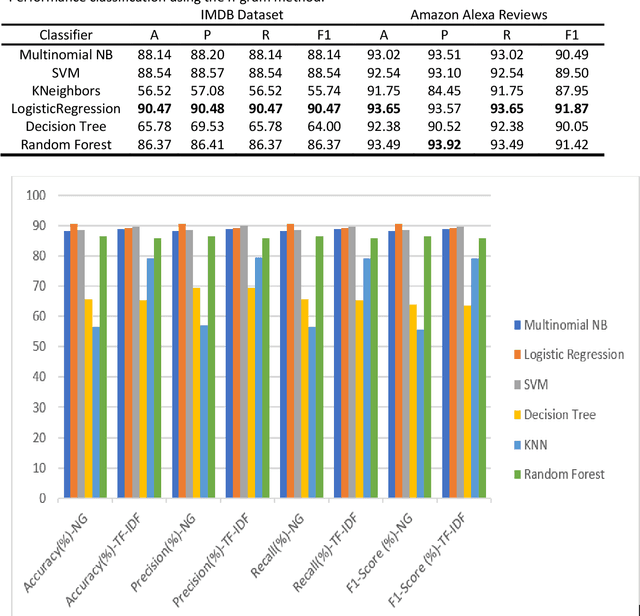
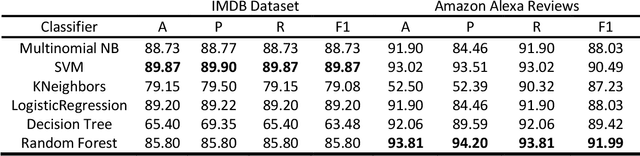
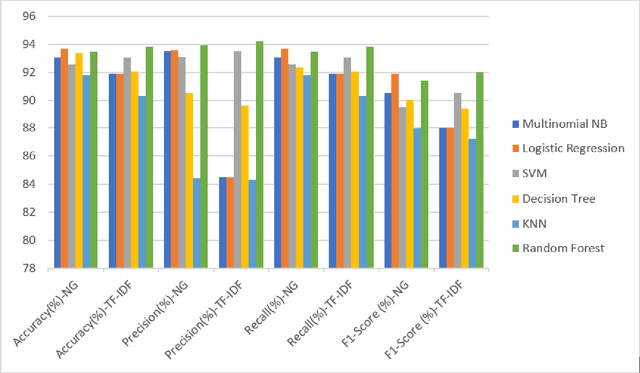
Text Classification is the process of categorizing text into the relevant categories and its algorithms are at the core of many Natural Language Processing (NLP). Term Frequency-Inverse Document Frequency (TF-IDF) and NLP are the most highly used information retrieval methods in text classification. We have investigated and analyzed the feature weighting method for text classification on unstructured data. The proposed model considered two features N-Grams and TF-IDF on the IMDB movie reviews and Amazon Alexa reviews dataset for sentiment analysis. Then we have used the state-of-the-art classifier to validate the method i.e., Support Vector Machine (SVM), Logistic Regression, Multinomial Naive Bayes (Multinomial NB), Random Forest, Decision Tree, and k-nearest neighbors (KNN). From those two feature extractions, a significant increase in feature extraction with TF-IDF features rather than based on N-Gram. TF-IDF got the maximum accuracy (93.81%), precision (94.20%), recall (93.81%), and F1-score (91.99%) value in Random Forest classifier.
Smart Sentiment Analysis-based Search Engine Classification Intelligence
Jun 16, 2023

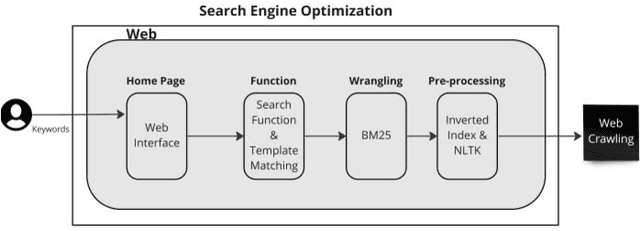
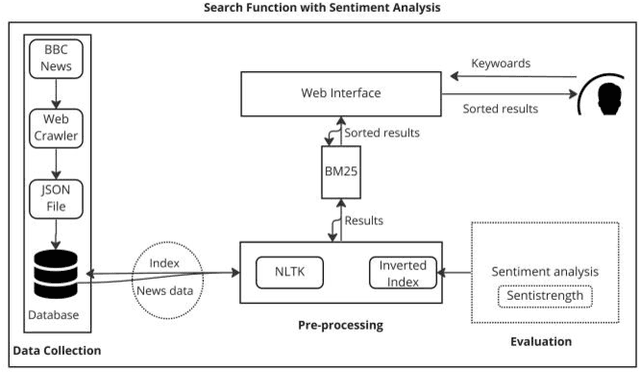
Search engines are widely used for finding information on the internet. However, there are limitations in the current search approach, such as providing popular but not necessarily relevant results. This research addresses the issue of polysemy in search results by implementing a search function that determines the sentimentality of the retrieved information. The study utilizes a web crawler to collect data from the British Broadcasting Corporation (BBC) news site, and the sentimentality of the news articles is determined using the Sentistrength program. The results demonstrate that the proposed search function improves recall value while accurately retrieving nonpolysemous news. Furthermore, Sentistrength outperforms deep learning and clustering methods in classifying search results. The methodology presented in this article can be applied to analyze the sentimentality and reputation of entities on the internet.
Sentiment Analysis on YouTube Smart Phone Unboxing Video Reviews in Sri Lanka
Feb 04, 2023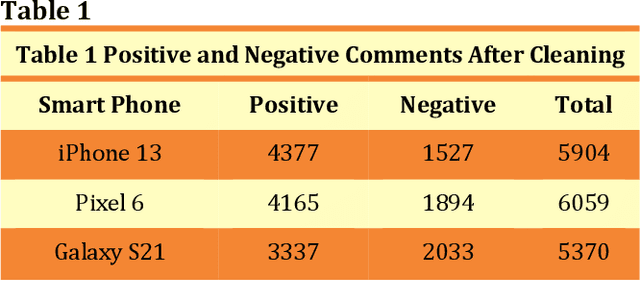
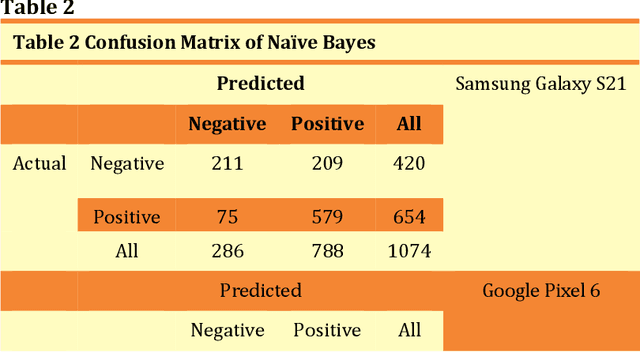


Product-related reviews are based on users' experiences that are mostly shared on videos in YouTube. It is the second most popular website globally in 2021. People prefer to watch videos on recently released products prior to purchasing, in order to gather overall feedback and make worthy decisions. These videos are created by vloggers who are enthusiastic about technical materials and feedback is usually placed by experienced users of the product or its brand. Analyzing the sentiment of the user reviews gives useful insights into the product in general. This study is focused on three smartphone reviews, namely, Apple iPhone 13, Google Pixel 6, and Samsung Galaxy S21 which were released in 2021. VADER, which is a lexicon and rule-based sentiment analysis tool was used to classify each comment to its appropriate positive or negative orientation. All three smartphones show a positive sentiment from the users' perspective and iPhone 13 has the highest number of positive reviews. The resulting models have been tested using N\"aive Bayes, Decision Tree, and Support Vector Machine. Among these three classifiers, Support Vector Machine shows higher accuracies and F1-scores.
How to use LLMs for Text Analysis
Jul 24, 2023This guide introduces Large Language Models (LLM) as a highly versatile text analysis method within the social sciences. As LLMs are easy-to-use, cheap, fast, and applicable on a broad range of text analysis tasks, ranging from text annotation and classification to sentiment analysis and critical discourse analysis, many scholars believe that LLMs will transform how we do text analysis. This how-to guide is aimed at students and researchers with limited programming experience, and offers a simple introduction to how LLMs can be used for text analysis in your own research project, as well as advice on best practices. We will go through each of the steps of analyzing textual data with LLMs using Python: installing the software, setting up the API, loading the data, developing an analysis prompt, analyzing the text, and validating the results. As an illustrative example, we will use the challenging task of identifying populism in political texts, and show how LLMs move beyond the existing state-of-the-art.
Reducing Spurious Correlations for Aspect-Based Sentiment Analysis with Variational Information Bottleneck and Contrastive Learning
Mar 12, 2023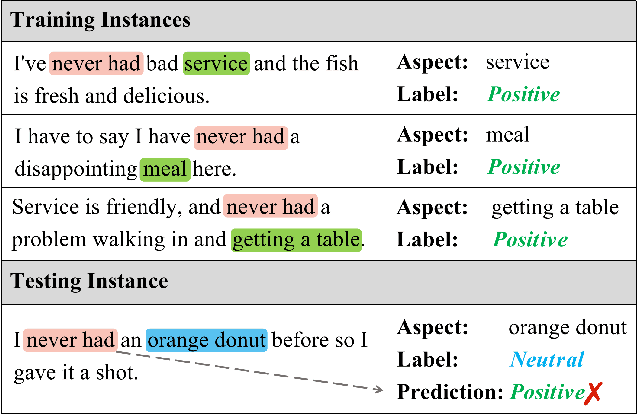

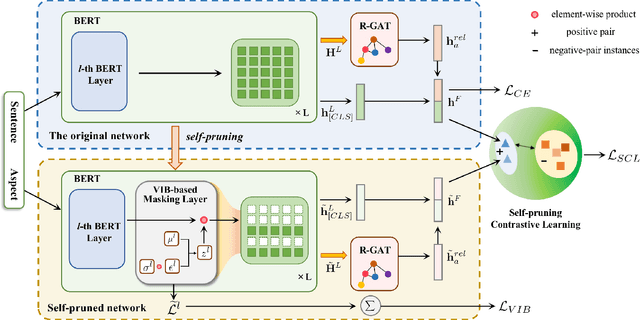
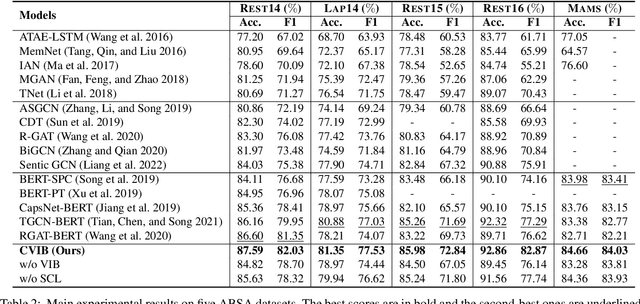
Deep learning techniques have dominated the literature on aspect-based sentiment analysis (ABSA), yielding state-of-the-art results. However, these deep models generally suffer from spurious correlation problems between input features and output labels, which creates significant barriers to robustness and generalization capability. In this paper, we propose a novel Contrastive Variational Information Bottleneck framework (called CVIB) to reduce spurious correlations for ABSA. The proposed CVIB framework is composed of an original network and a self-pruned network, and these two networks are optimized simultaneously via contrastive learning. Concretely, we employ the Variational Information Bottleneck (VIB) principle to learn an informative and compressed network (self-pruned network) from the original network, which discards the superfluous patterns or spurious correlations between input features and prediction labels. Then, self-pruning contrastive learning is devised to pull together semantically similar positive pairs and push away dissimilar pairs, where the representations of the anchor learned by the original and self-pruned networks respectively are regarded as a positive pair while the representations of two different sentences within a mini-batch are treated as a negative pair. To verify the effectiveness of our CVIB method, we conduct extensive experiments on five benchmark ABSA datasets and the experimental results show that our approach achieves better performance than the strong competitors in terms of overall prediction performance, robustness, and generalization.