 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Characterizing References from Different Disciplines: A Perspective of Citation Content Analysis
Jan 19, 2021
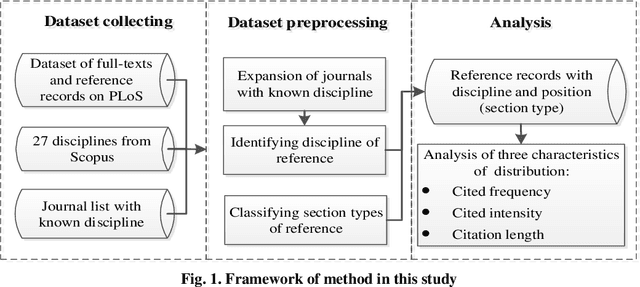
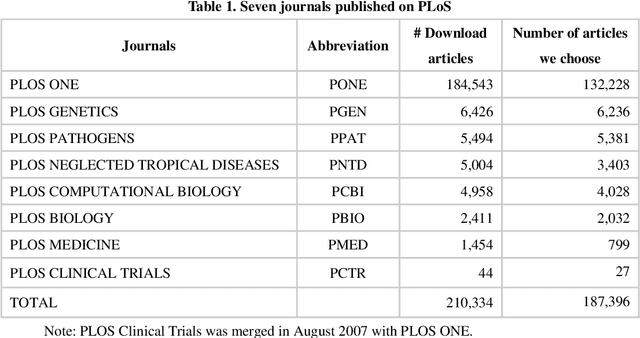
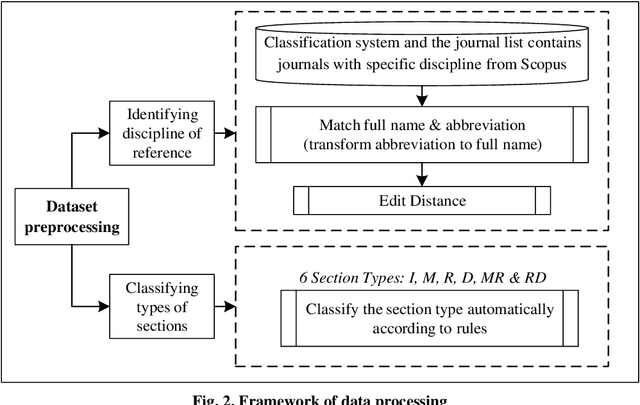
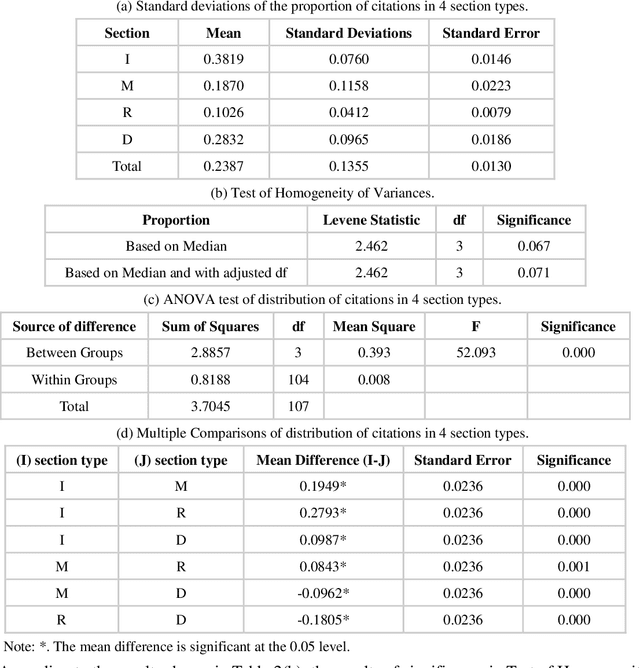
Multidisciplinary cooperation is now common in research since social issues inevitably involve multiple disciplines. In research articles, reference information, especially citation content, is an important representation of communication among different disciplines. Analyzing the distribution characteristics of references from different disciplines in research articles is basic to detecting the sources of referred information and identifying contributions of different disciplines. This work takes articles in PLoS as the data and characterizes the references from different disciplines based on Citation Content Analysis (CCA). First, we download 210,334 full-text articles from PLoS and collect the information of the in-text citations. Then, we identify the discipline of each reference in these academic articles. To characterize the distribution of these references, we analyze three characteristics, namely, the number of citations, the average cited intensity and the average citation length. Finally, we conclude that the distributions of references from different disciplines are significantly different. Although most references come from Natural Science, Humanities and Social Sciences play important roles in the Introduction and Background sections of the articles. Basic disciplines, such as Mathematics, mainly provide research methods in the articles in PLoS. Citations mentioned in the Results and Discussion sections of articles are mainly in-discipline citations, such as citations from Nursing and Medicine in PLoS.
Bosonic Random Walk Networks for Graph Learning
Dec 31, 2020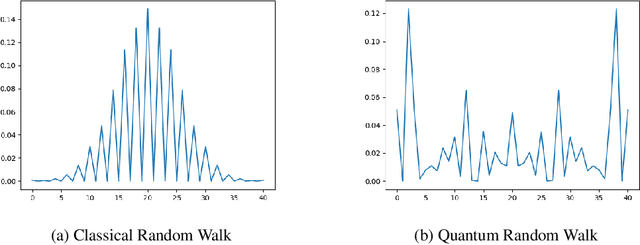
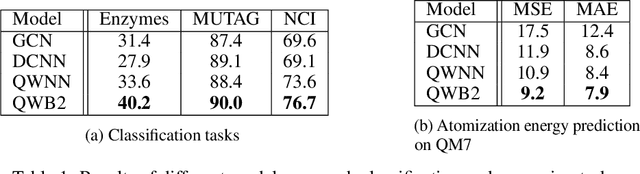
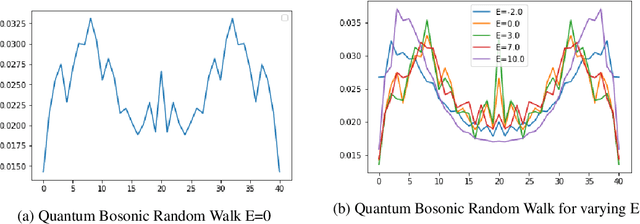
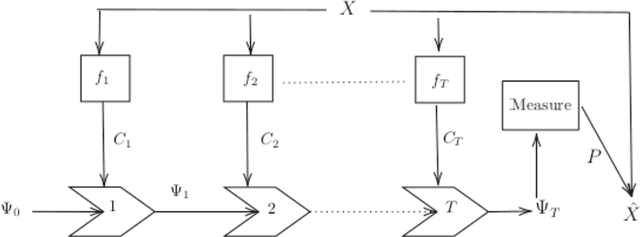
The development of Graph Neural Networks (GNNs) has led to great progress in machine learning on graph-structured data. These networks operate via diffusing information across the graph nodes while capturing the structure of the graph. Recently there has also seen tremendous progress in quantum computing techniques. In this work, we explore applications of multi-particle quantum walks on diffusing information across graphs. Our model is based on learning the operators that govern the dynamics of quantum random walkers on graphs. We demonstrate the effectiveness of our method on classification and regression tasks.
Reconstructing Perceptive Images from Brain Activity by Shape-Semantic GAN
Jan 28, 2021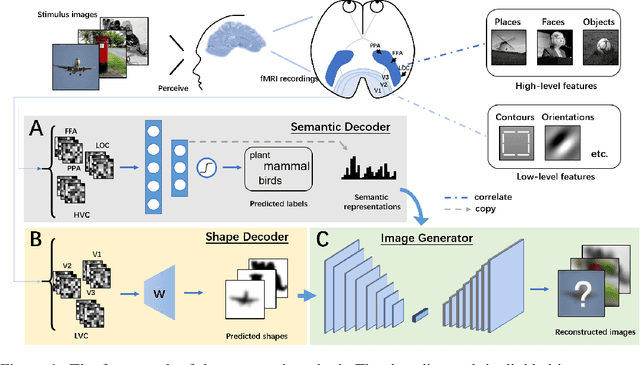
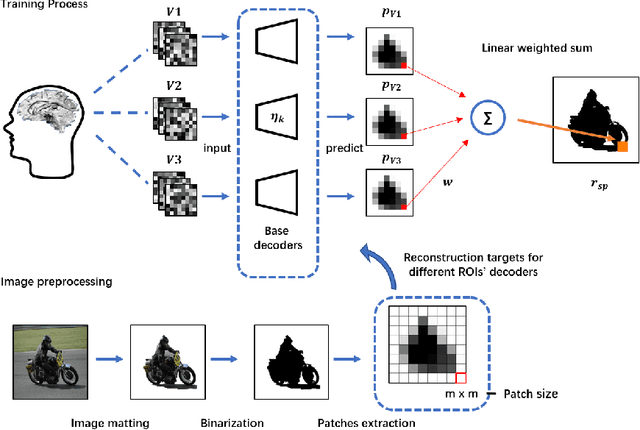
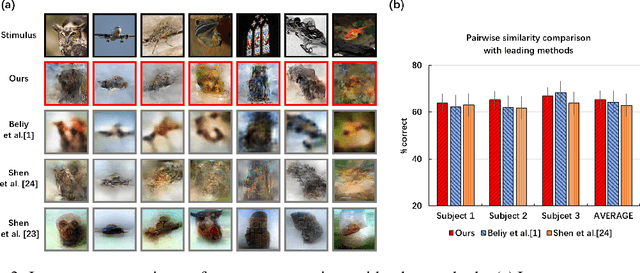
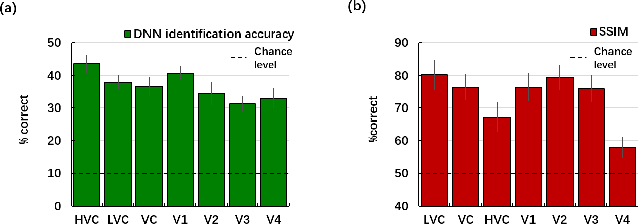
Reconstructing seeing images from fMRI recordings is an absorbing research area in neuroscience and provides a potential brain-reading technology. The challenge lies in that visual encoding in brain is highly complex and not fully revealed. Inspired by the theory that visual features are hierarchically represented in cortex, we propose to break the complex visual signals into multi-level components and decode each component separately. Specifically, we decode shape and semantic representations from the lower and higher visual cortex respectively, and merge the shape and semantic information to images by a generative adversarial network (Shape-Semantic GAN). This 'divide and conquer' strategy captures visual information more accurately. Experiments demonstrate that Shape-Semantic GAN improves the reconstruction similarity and image quality, and achieves the state-of-the-art image reconstruction performance.
Towards Novel Target Discovery Through Open-Set Domain Adaptation
May 06, 2021
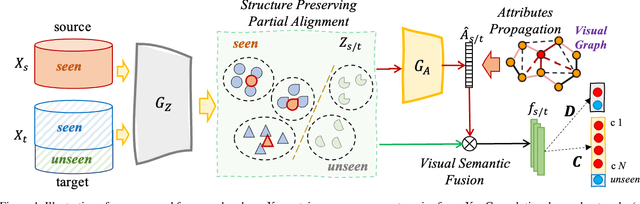
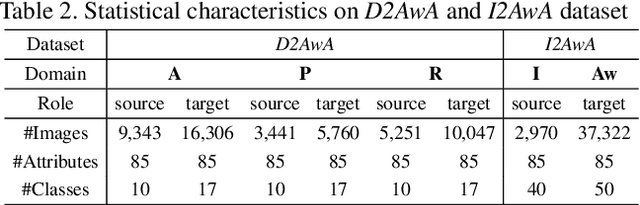
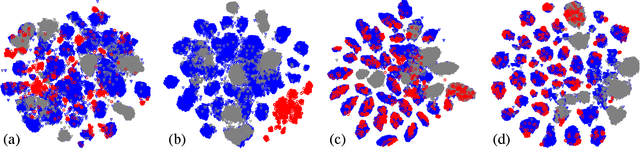
Open-set domain adaptation (OSDA) considers that the target domain contains samples from novel categories unobserved in external source domain. Unfortunately, existing OSDA methods always ignore the demand for the information of unseen categories and simply recognize them as "unknown" set without further explanation. This motivates us to understand the unknown categories more specifically by exploring the underlying structures and recovering their interpretable semantic attributes. In this paper, we propose a novel framework to accurately identify the seen categories in target domain, and effectively recover the semantic attributes for unseen categories. Specifically, structure preserving partial alignment is developed to recognize the seen categories through domain-invariant feature learning. Attribute propagation over visual graph is designed to smoothly transit attributes from seen to unseen categories via visual-semantic mapping. Moreover, two new cross-main benchmarks are constructed to evaluate the proposed framework in the novel and practical challenge. Experimental results on open-set recognition and semantic recovery demonstrate the superiority of the proposed method over other compared baselines.
Dynamic Knowledge Graphs as Semantic Memory Model for Industrial Robots
Jan 06, 2021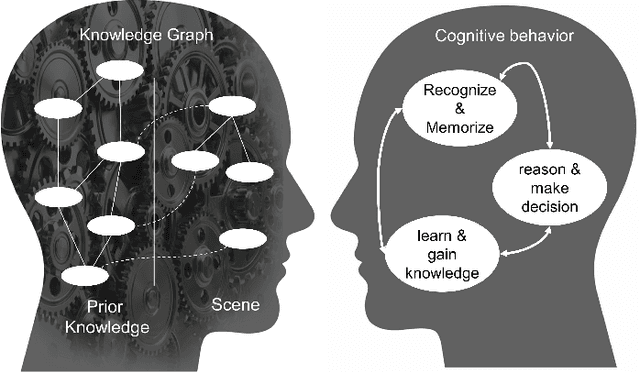
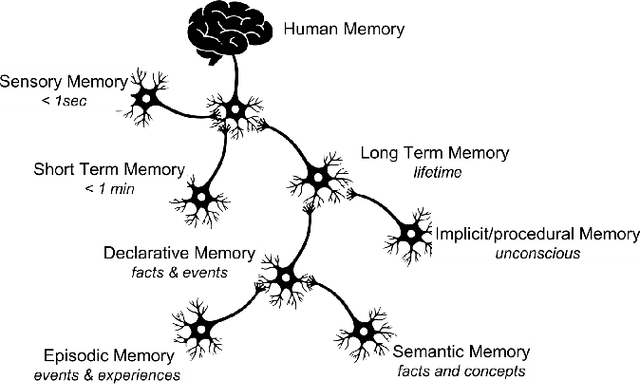
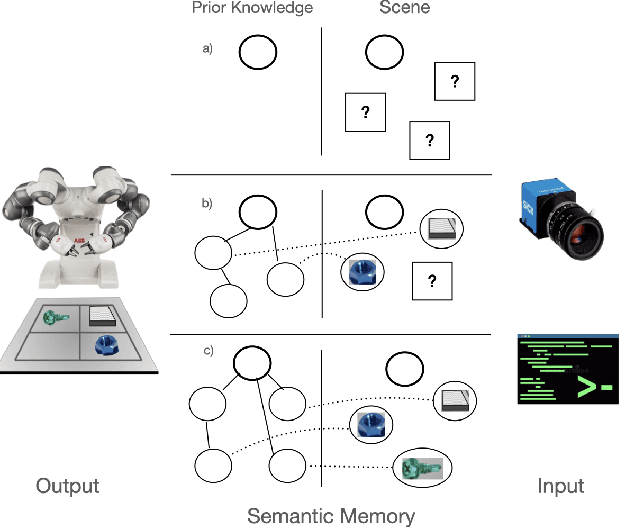
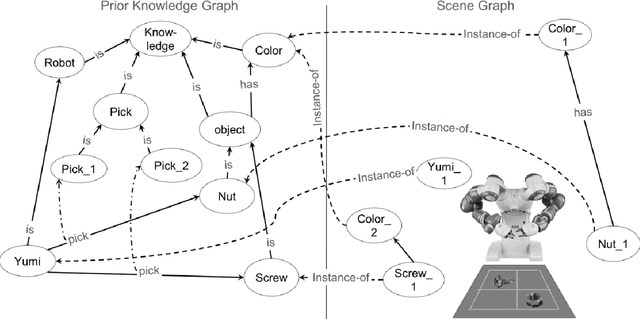
In this paper, we present a model for semantic memory that allows machines to collect information and experiences to become more proficient with time. After a semantic analysis of the data, information is stored in a knowledge graph which is used to comprehend instructions, expressed in natural language, and execute the required tasks in a deterministic manner. This imparts industrial robots cognitive behavior and an intuitive user interface, which is most appreciated in an era, when collaborative robots are to work alongside humans. The paper outlines the architecture of the system together with a practical implementation of the proposal.
Probing artificial neural networks: insights from neuroscience
Apr 16, 2021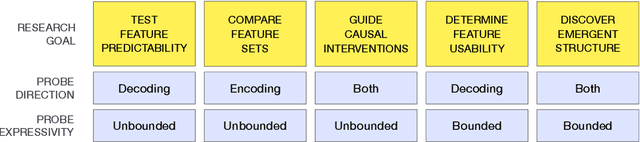
A major challenge in both neuroscience and machine learning is the development of useful tools for understanding complex information processing systems. One such tool is probes, i.e., supervised models that relate features of interest to activation patterns arising in biological or artificial neural networks. Neuroscience has paved the way in using such models through numerous studies conducted in recent decades. In this work, we draw insights from neuroscience to help guide probing research in machine learning. We highlight two important design choices for probes $-$ direction and expressivity $-$ and relate these choices to research goals. We argue that specific research goals play a paramount role when designing a probe and encourage future probing studies to be explicit in stating these goals.
Optimal Program Synthesis Over Noisy Data
Mar 08, 2021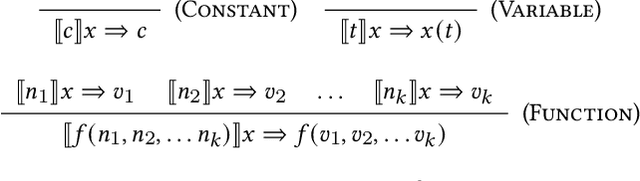
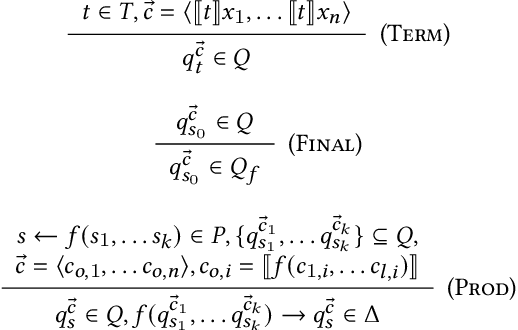
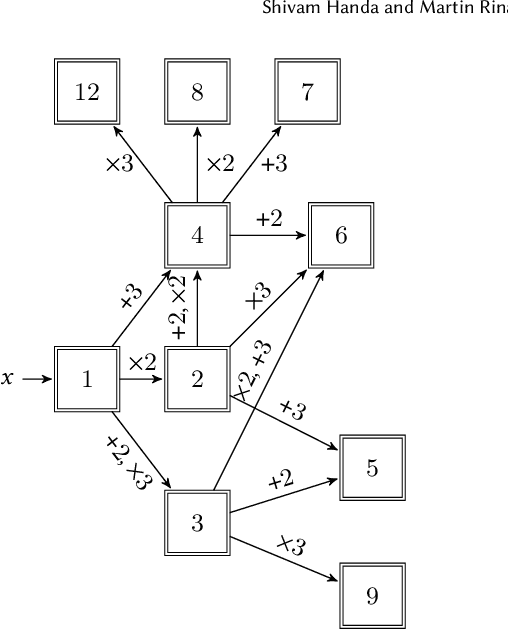
We explore and formalize the task of synthesizing programs over noisy data, i.e., data that may contain corrupted input-output examples. By formalizing the concept of a Noise Source, an Input Source, and a prior distribution over programs, we formalize the probabilistic process which constructs a noisy dataset. This formalism allows us to define the correctness of a synthesis algorithm, in terms of its ability to synthesize the hidden underlying program. The probability of a synthesis algorithm being correct depends upon the match between the Noise Source and the Loss Function used in the synthesis algorithm's optimization process. We formalize the concept of an optimal Loss Function given prior information about the Noise Source. We provide a technique to design optimal Loss Functions given perfect and imperfect information about the Noise Sources. We also formalize the concept and conditions required for convergence, i.e., conditions under which the probability that the synthesis algorithm produces a correct program increases as the size of the noisy data set increases. This paper presents the first formalization of the concept of optimal Loss Functions, the first closed form definition of optimal Loss Functions, and the first conditions that ensure that a noisy synthesis algorithm will have convergence guarantees.
Exploring Explicit and Implicit Visual Relationships for Image Captioning
May 06, 2021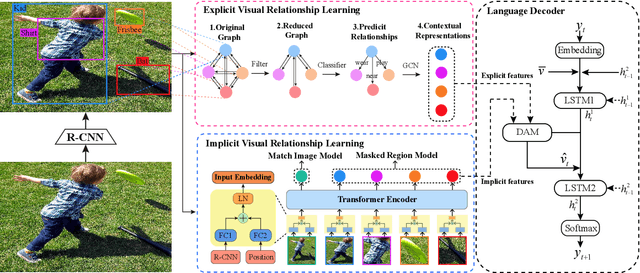
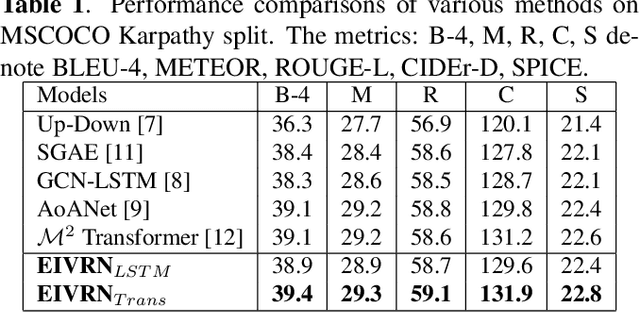
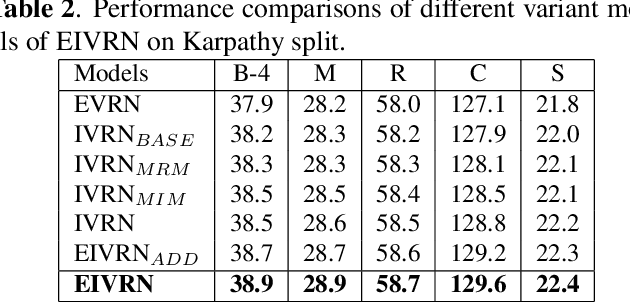
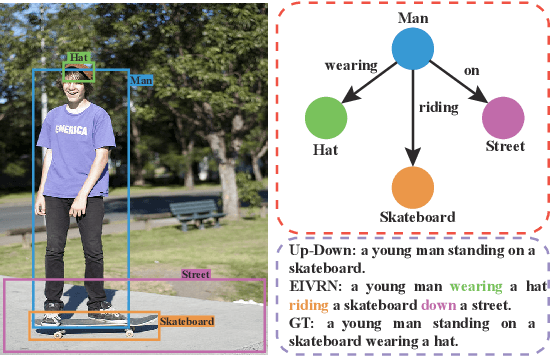
Image captioning is one of the most challenging tasks in AI, which aims to automatically generate textual sentences for an image. Recent methods for image captioning follow encoder-decoder framework that transforms the sequence of salient regions in an image into natural language descriptions. However, these models usually lack the comprehensive understanding of the contextual interactions reflected on various visual relationships between objects. In this paper, we explore explicit and implicit visual relationships to enrich region-level representations for image captioning. Explicitly, we build semantic graph over object pairs and exploit gated graph convolutional networks (Gated GCN) to selectively aggregate local neighbors' information. Implicitly, we draw global interactions among the detected objects through region-based bidirectional encoder representations from transformers (Region BERT) without extra relational annotations. To evaluate the effectiveness and superiority of our proposed method, we conduct extensive experiments on Microsoft COCO benchmark and achieve remarkable improvements compared with strong baselines.
Disentangled Recurrent Wasserstein Autoencoder
Jan 19, 2021


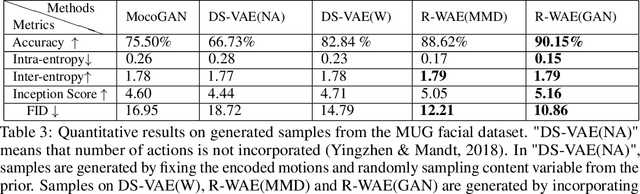
Learning disentangled representations leads to interpretable models and facilitates data generation with style transfer, which has been extensively studied on static data such as images in an unsupervised learning framework. However, only a few works have explored unsupervised disentangled sequential representation learning due to challenges of generating sequential data. In this paper, we propose recurrent Wasserstein Autoencoder (R-WAE), a new framework for generative modeling of sequential data. R-WAE disentangles the representation of an input sequence into static and dynamic factors (i.e., time-invariant and time-varying parts). Our theoretical analysis shows that, R-WAE minimizes an upper bound of a penalized form of the Wasserstein distance between model distribution and sequential data distribution, and simultaneously maximizes the mutual information between input data and different disentangled latent factors, respectively. This is superior to (recurrent) VAE which does not explicitly enforce mutual information maximization between input data and disentangled latent representations. When the number of actions in sequential data is available as weak supervision information, R-WAE is extended to learn a categorical latent representation of actions to improve its disentanglement. Experiments on a variety of datasets show that our models outperform other baselines with the same settings in terms of disentanglement and unconditional video generation both quantitatively and qualitatively.
Approximate Bayesian inference and forecasting in huge-dimensional multi-country VARs
Mar 08, 2021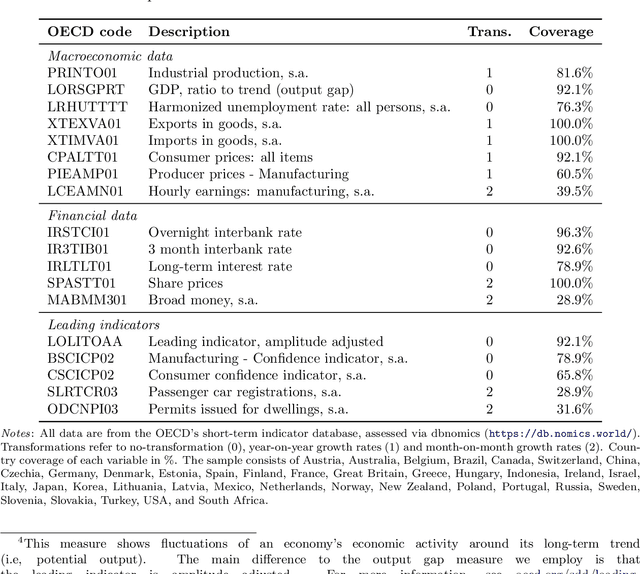
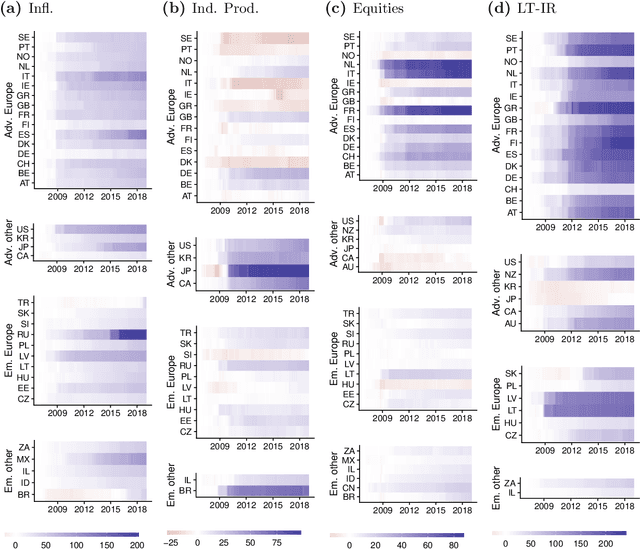

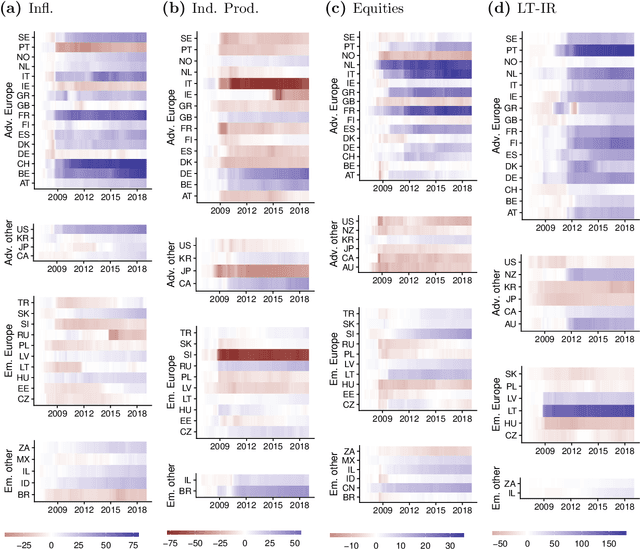
The Panel Vector Autoregressive (PVAR) model is a popular tool for macroeconomic forecasting and structural analysis in multi-country applications since it allows for spillovers between countries in a very flexible fashion. However, this flexibility means that the number of parameters to be estimated can be enormous leading to over-parameterization concerns. Bayesian global-local shrinkage priors, such as the Horseshoe prior used in this paper, can overcome these concerns, but they require the use of Markov Chain Monte Carlo (MCMC) methods rendering them computationally infeasible in high dimensions. In this paper, we develop computationally efficient Bayesian methods for estimating PVARs using an integrated rotated Gaussian approximation (IRGA). This exploits the fact that whereas own country information is often important in PVARs, information on other countries is often unimportant. Using an IRGA, we split the the posterior into two parts: one involving own country coefficients, the other involving other country coefficients. Fast methods such as approximate message passing or variational Bayes can be used on the latter and, conditional on these, the former are estimated with precision using MCMC methods. In a forecasting exercise involving PVARs with up to $18$ variables for each of $38$ countries, we demonstrate that our methods produce good forecasts quickly.