 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pruning with Compensation: Efficient Channel Pruning for Deep Convolutional Neural Networks
Aug 31, 2021
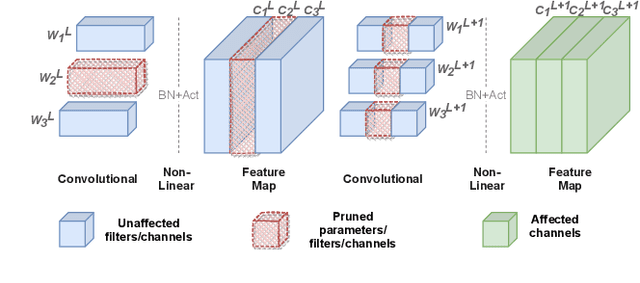
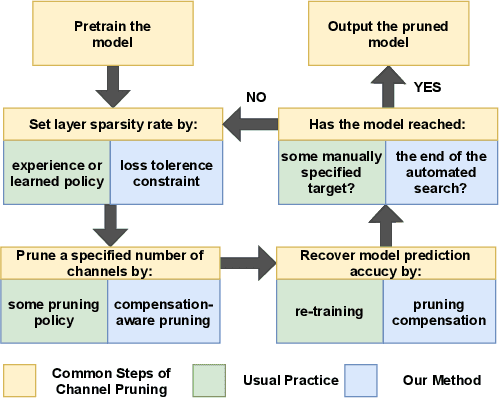
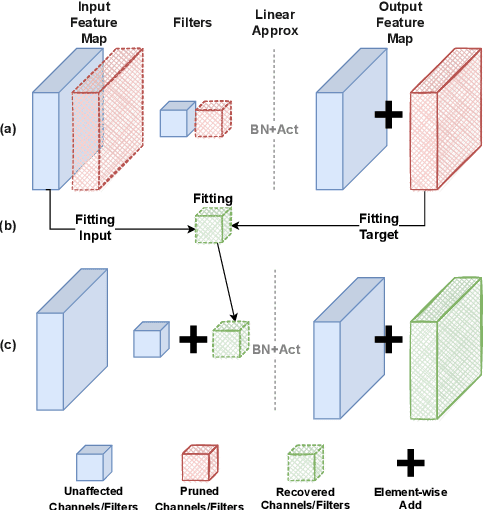
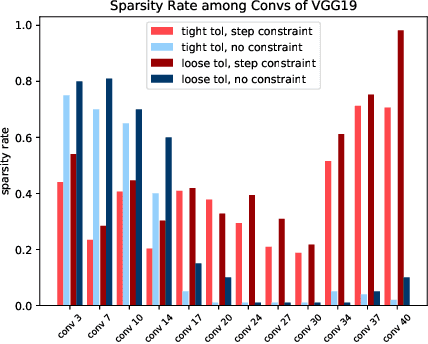
Channel pruning is a promising technique to compress the parameters of deep convolutional neural networks(DCNN) and to speed up the inference. This paper aims to address the long-standing inefficiency of channel pruning. Most channel pruning methods recover the prediction accuracy by re-training the pruned model from the remaining parameters or random initialization. This re-training process is heavily dependent on the sufficiency of computational resources, training data, and human interference(tuning the training strategy). In this paper, a highly efficient pruning method is proposed to significantly reduce the cost of pruning DCNN. The main contributions of our method include: 1) pruning compensation, a fast and data-efficient substitute of re-training to minimize the post-pruning reconstruction loss of features, 2) compensation-aware pruning(CaP), a novel pruning algorithm to remove redundant or less-weighted channels by minimizing the loss of information, and 3) binary structural search with step constraint to minimize human interference. On benchmarks including CIFAR-10/100 and ImageNet, our method shows competitive pruning performance among the state-of-the-art retraining-based pruning methods and, more importantly, reduces the processing time by 95% and data usage by 90%.
ViTA: Visual-Linguistic Translation by Aligning Object Tags
Jun 01, 2021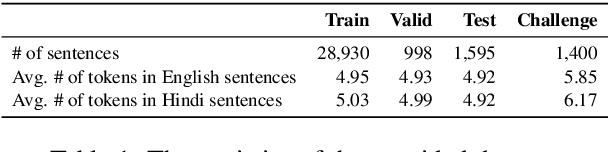
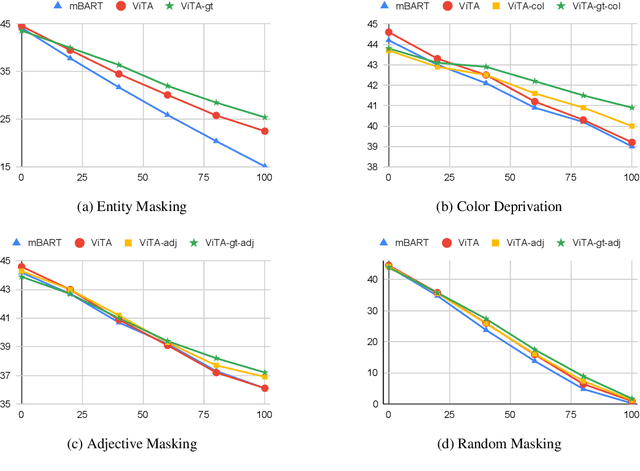
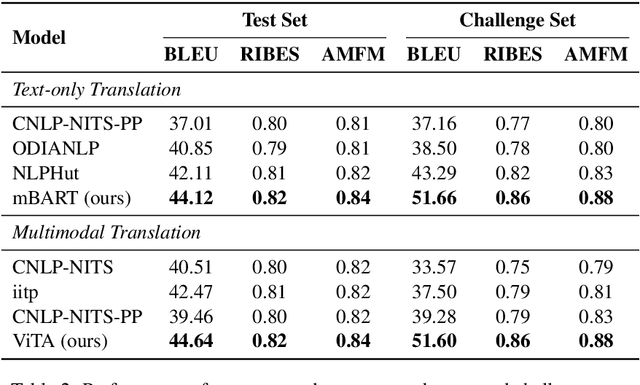

Multimodal Machine Translation (MMT) enriches the source text with visual information for translation. It has gained popularity in recent years, and several pipelines have been proposed in the same direction. Yet, the task lacks quality datasets to illustrate the contribution of visual modality in the translation systems. In this paper, we propose our system for the Multimodal Translation Task of WAT 2021 from English to Hindi. We propose to use mBART, a pretrained multilingual sequence-to-sequence model, for the textual-only translations. Further, we bring the visual information to a textual domain by extracting object tags from the image and enhance the input for the multimodal task. We also explore the robustness of our system by systematically degrading the source text. Finally, we achieve a BLEU score of 44.6 and 51.6 on the test set and challenge set of the task.
Surgery Scene Restoration for Robot Assisted Minimally Invasive Surgery
Sep 06, 2021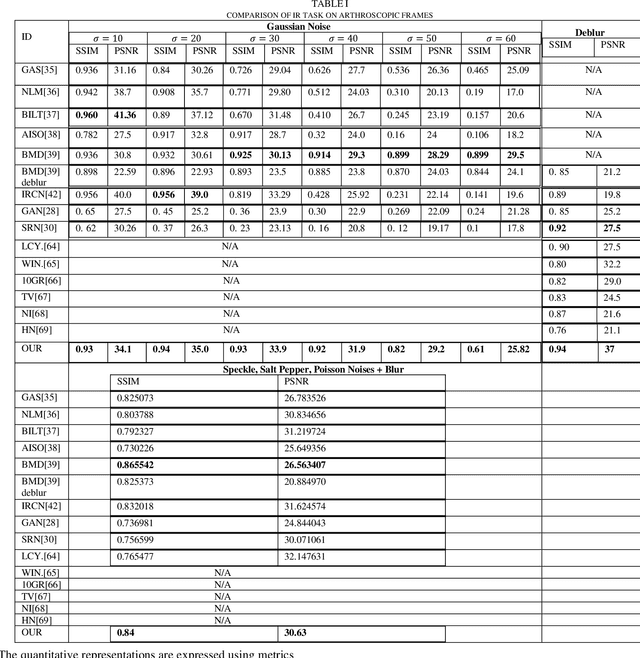
Minimally invasive surgery (MIS) offers several advantages including minimum tissue injury and blood loss, and quick recovery time, however, it imposes some limitations on surgeons ability. Among others such as lack of tactile or haptic feedback, poor visualization of the surgical site is one of the most acknowledged factors that exhibits several surgical drawbacks including unintentional tissue damage. To the context of robot assisted surgery, lack of frame contextual details makes vision task challenging when it comes to tracking tissue and tools, segmenting scene, and estimating pose and depth. In MIS the acquired frames are compromised by different noises and get blurred caused by motions from different sources. Moreover, when underwater environment is considered for instance knee arthroscopy, mostly visible noises and blur effects are originated from the environment, poor control on illuminations and imaging conditions. Additionally, in MIS, procedure like automatic white balancing and transformation between the raw color information to its standard RGB color space are often absent due to the hardware miniaturization. There is a high demand of an online preprocessing framework that can circumvent these drawbacks. Our proposed method is able to restore a latent clean and sharp image in standard RGB color space from its noisy, blur and raw observation in a single preprocessing stage.
Contributions to Large Scale Bayesian Inference and Adversarial Machine Learning
Sep 25, 2021
The rampant adoption of ML methodologies has revealed that models are usually adopted to make decisions without taking into account the uncertainties in their predictions. More critically, they can be vulnerable to adversarial examples. Thus, we believe that developing ML systems that take into account predictive uncertainties and are robust against adversarial examples is a must for critical, real-world tasks. We start with a case study in retailing. We propose a robust implementation of the Nerlove-Arrow model using a Bayesian structural time series model. Its Bayesian nature facilitates incorporating prior information reflecting the manager's views, which can be updated with relevant data. However, this case adopted classical Bayesian techniques, such as the Gibbs sampler. Nowadays, the ML landscape is pervaded with neural networks and this chapter also surveys current developments in this sub-field. Then, we tackle the problem of scaling Bayesian inference to complex models and large data regimes. In the first part, we propose a unifying view of two different Bayesian inference algorithms, Stochastic Gradient Markov Chain Monte Carlo (SG-MCMC) and Stein Variational Gradient Descent (SVGD), leading to improved and efficient novel sampling schemes. In the second part, we develop a framework to boost the efficiency of Bayesian inference in probabilistic models by embedding a Markov chain sampler within a variational posterior approximation. After that, we present an alternative perspective on adversarial classification based on adversarial risk analysis, and leveraging the scalable Bayesian approaches from chapter 2. In chapter 4 we turn to reinforcement learning, introducing Threatened Markov Decision Processes, showing the benefits of accounting for adversaries in RL while the agent learns.
Information Extraction Under Privacy Constraints
Jan 17, 2016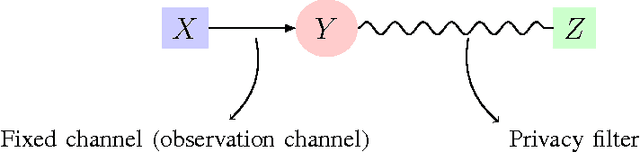
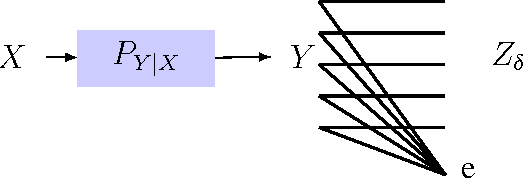
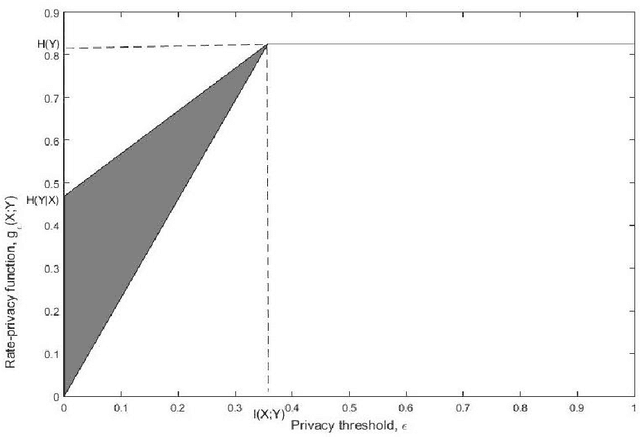
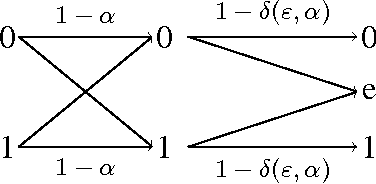
A privacy-constrained information extraction problem is considered where for a pair of correlated discrete random variables $(X,Y)$ governed by a given joint distribution, an agent observes $Y$ and wants to convey to a potentially public user as much information about $Y$ as possible without compromising the amount of information revealed about $X$. To this end, the so-called {\em rate-privacy function} is introduced to quantify the maximal amount of information (measured in terms of mutual information) that can be extracted from $Y$ under a privacy constraint between $X$ and the extracted information, where privacy is measured using either mutual information or maximal correlation. Properties of the rate-privacy function are analyzed and information-theoretic and estimation-theoretic interpretations of it are presented for both the mutual information and maximal correlation privacy measures. It is also shown that the rate-privacy function admits a closed-form expression for a large family of joint distributions of $(X,Y)$. Finally, the rate-privacy function under the mutual information privacy measure is considered for the case where $(X,Y)$ has a joint probability density function by studying the problem where the extracted information is a uniform quantization of $Y$ corrupted by additive Gaussian noise. The asymptotic behavior of the rate-privacy function is studied as the quantization resolution grows without bound and it is observed that not all of the properties of the rate-privacy function carry over from the discrete to the continuous case.
Reconfigurable Intelligent Surfaces Aided Communication: Capacity and Performance Analysis Over Rician Fading Channel
Jul 22, 2021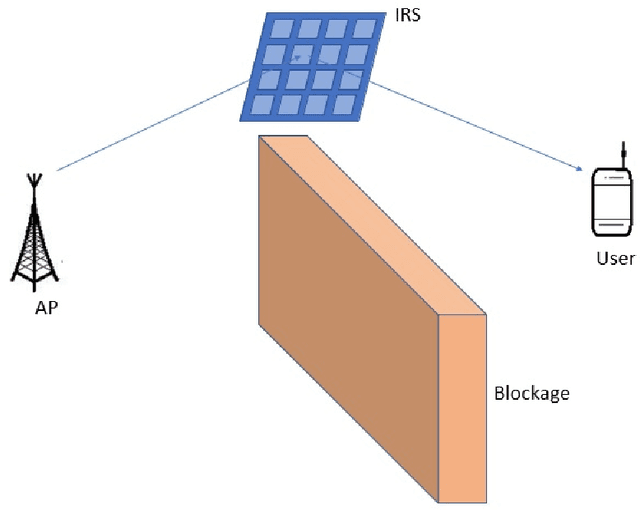
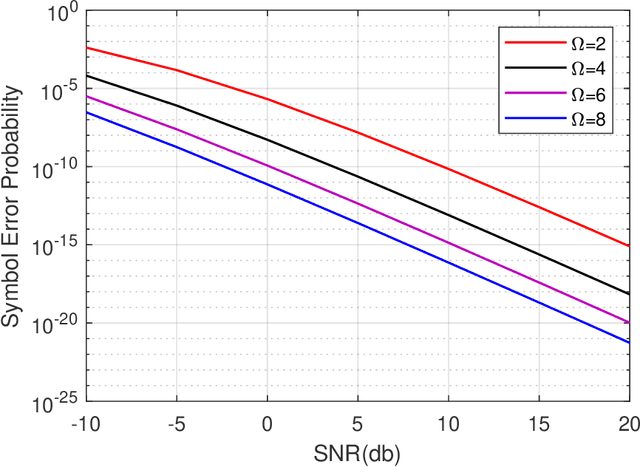
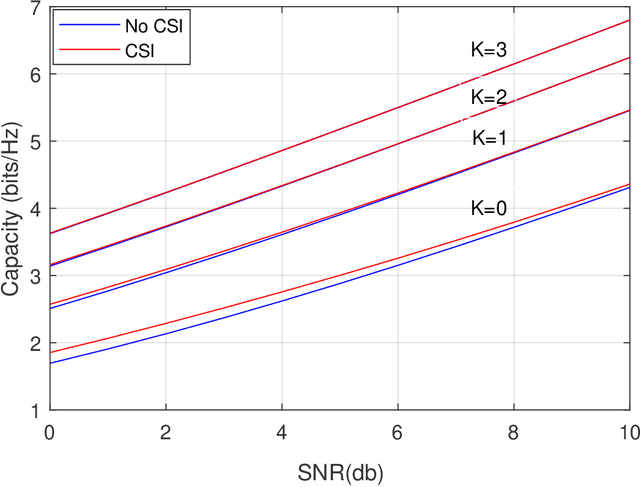
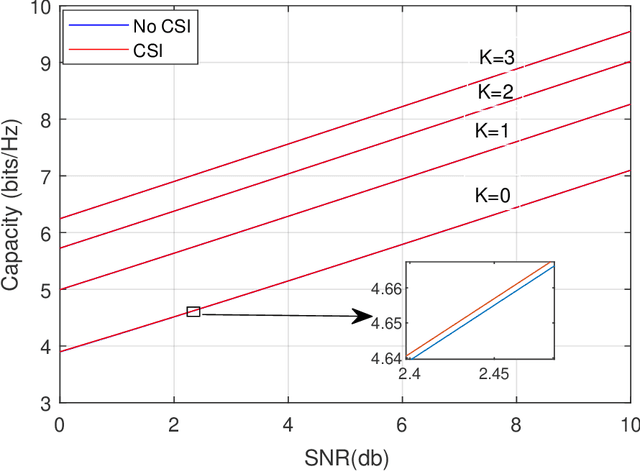
In this work, we consider a single input single output (SISO) system for Reconfigurable Intelligent Surface (RIS) assisted mmWave communication. We consider Rician channel models over user node to RIS and RIS to Access Point (AP). We obtain closed form expressions for capacity with channel state information (CSI) and without CSI at the transmitter. Newly derived capacity expressions are closed form expressions in a very compact form. We also simplified the closed form expressions for average symbol error probability. We also characterize the impacts of key parameters Rician factor K and number of elements on IRS on ergodic capacity with CSI and without CSI at the transmitter.
Bayesian Opponent Exploitation in Imperfect-Information Games
Jun 28, 2018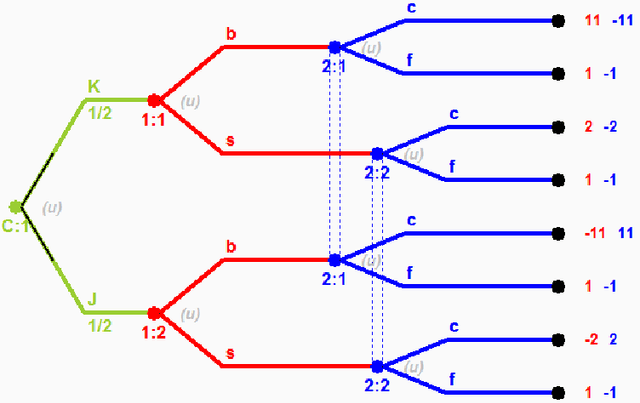

Two fundamental problems in computational game theory are computing a Nash equilibrium and learning to exploit opponents given observations of their play (opponent exploitation). The latter is perhaps even more important than the former: Nash equilibrium does not have a compelling theoretical justification in game classes other than two-player zero-sum, and for all games one can potentially do better by exploiting perceived weaknesses of the opponent than by following a static equilibrium strategy throughout the match. The natural setting for opponent exploitation is the Bayesian setting where we have a prior model that is integrated with observations to create a posterior opponent model that we respond to. The most natural, and a well-studied prior distribution is the Dirichlet distribution. An exact polynomial-time algorithm is known for best-responding to the posterior distribution for an opponent assuming a Dirichlet prior with multinomial sampling in normal-form games; however, for imperfect-information games the best known algorithm is based on approximating an infinite integral without theoretical guarantees. We present the first exact algorithm for a natural class of imperfect-information games. We demonstrate that our algorithm runs quickly in practice and outperforms the best prior approaches. We also present an algorithm for the uniform prior setting.
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
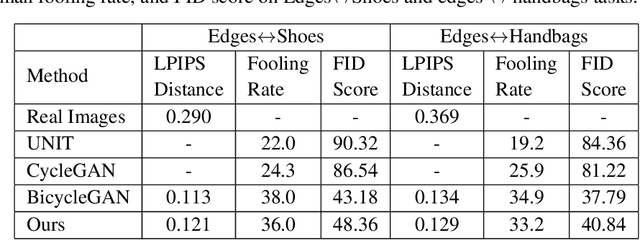
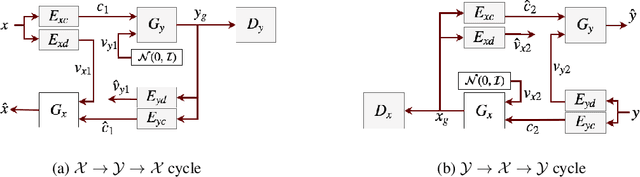
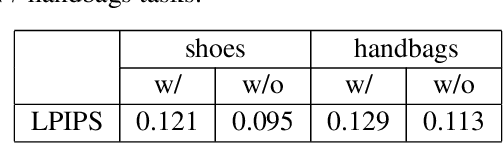
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
Learning To Describe Player Form in The MLB
Sep 11, 2021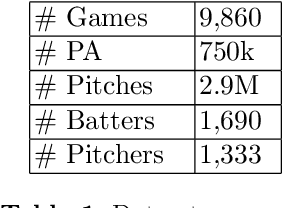
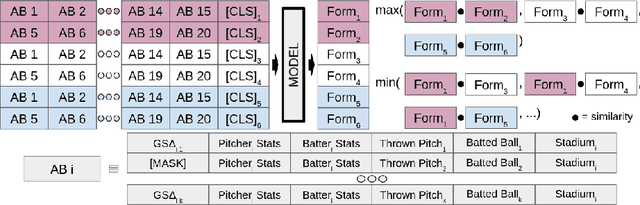
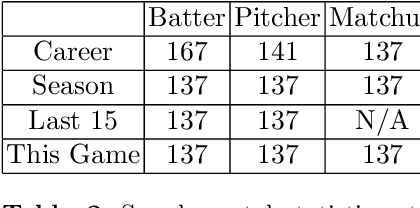
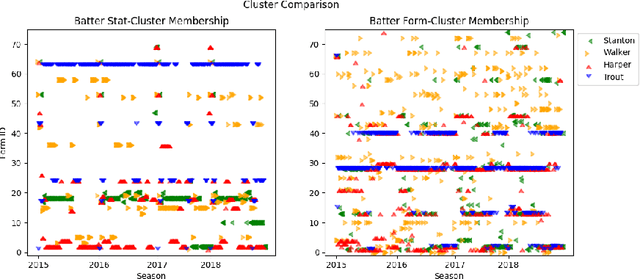
Major League Baseball (MLB) has a storied history of using statistics to better understand and discuss the game of baseball, with an entire discipline of statistics dedicated to the craft, known as sabermetrics. At their core, all sabermetrics seek to quantify some aspect of the game, often a specific aspect of a player's skill set - such as a batter's ability to drive in runs (RBI) or a pitcher's ability to keep batters from reaching base (WHIP). While useful, such statistics are fundamentally limited by the fact that they are derived from an account of what happened on the field, not how it happened. As a first step towards alleviating this shortcoming, we present a novel, contrastive learning-based framework for describing player form in the MLB. We use form to refer to the way in which a player has impacted the course of play in their recent appearances. Concretely, a player's form is described by a 72-dimensional vector. By comparing clusters of players resulting from our form representations and those resulting from traditional abermetrics, we demonstrate that our form representations contain information about how players impact the course of play, not present in traditional, publicly available statistics. We believe these embeddings could be utilized to predict both in-game and game-level events, such as the result of an at-bat or the winner of a game.
Open Information Extraction on Scientific Text: An Evaluation
Jun 04, 2018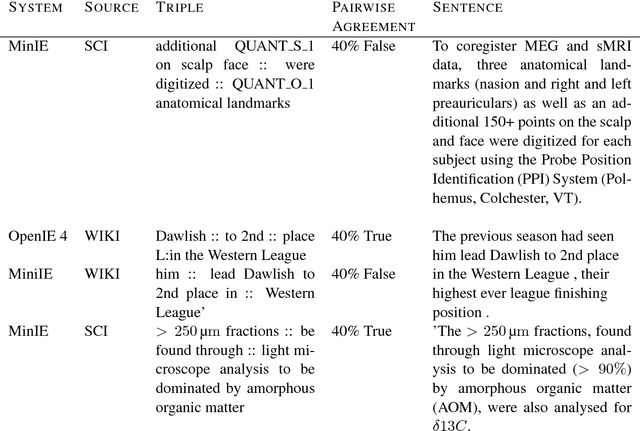
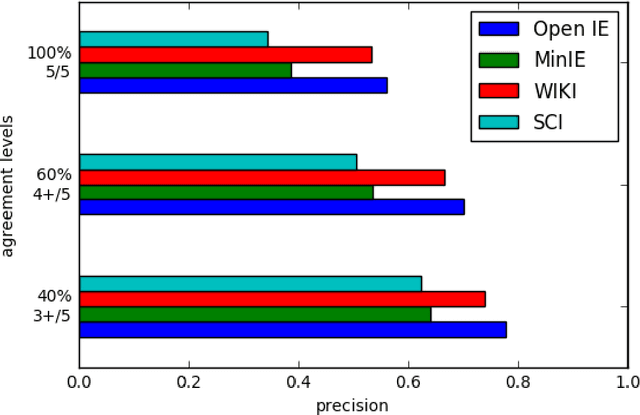
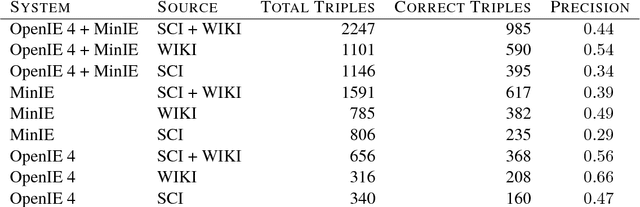

Open Information Extraction (OIE) is the task of the unsupervised creation of structured information from text. OIE is often used as a starting point for a number of downstream tasks including knowledge base construction, relation extraction, and question answering. While OIE methods are targeted at being domain independent, they have been evaluated primarily on newspaper, encyclopedic or general web text. In this article, we evaluate the performance of OIE on scientific texts originating from 10 different disciplines. To do so, we use two state-of-the-art OIE systems applying a crowd-sourcing approach. We find that OIE systems perform significantly worse on scientific text than encyclopedic text. We also provide an error analysis and suggest areas of work to reduce errors. Our corpus of sentences and judgments are made available.
* 10 pages