 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Resource Allocation Policies from Observational Data with an Application to Homeless Services Delivery
Jan 25, 2022
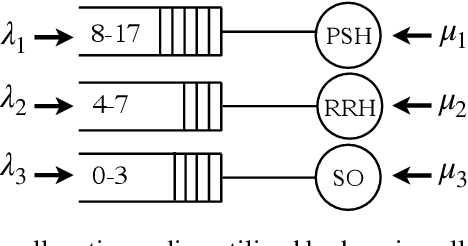
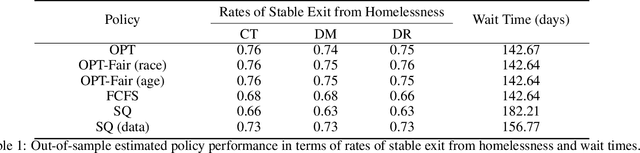
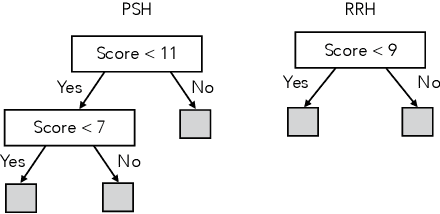
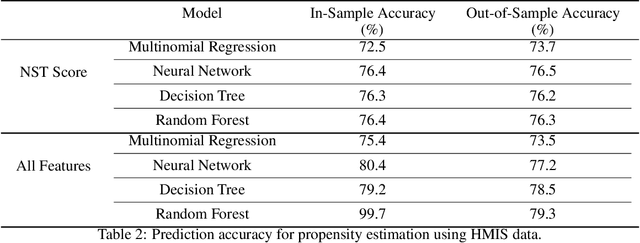
We study the problem of learning, from observational data, fair and interpretable policies that effectively match heterogeneous individuals to scarce resources of different types. We model this problem as a multi-class multi-server queuing system where both individuals and resources arrive stochastically over time. Each individual, upon arrival, is assigned to a queue where they wait to be matched to a resource. The resources are assigned in a first come first served (FCFS) fashion according to an eligibility structure that encodes the resource types that serve each queue. We propose a methodology based on techniques in modern causal inference to construct the individual queues as well as learn the matching outcomes and provide a mixed-integer optimization (MIO) formulation to optimize the eligibility structure. The MIO problem maximizes policy outcome subject to wait time and fairness constraints. It is very flexible, allowing for additional linear domain constraints. We conduct extensive analyses using synthetic and real-world data. In particular, we evaluate our framework using data from the U.S. Homeless Management Information System (HMIS). We obtain wait times as low as an FCFS policy while improving the rate of exit from homelessness for underserved or vulnerable groups (7% higher for the Black individuals and 15% higher for those below 17 years old) and overall.
Big Data Application for Network Level Travel Time Prediction
Jan 15, 2022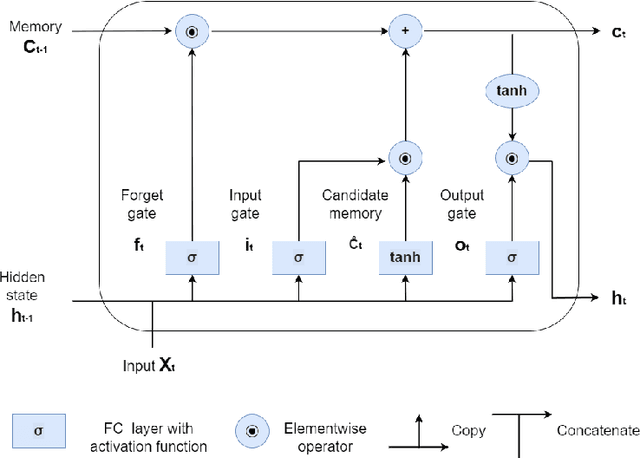
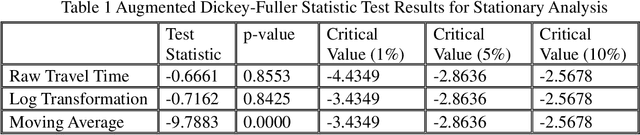
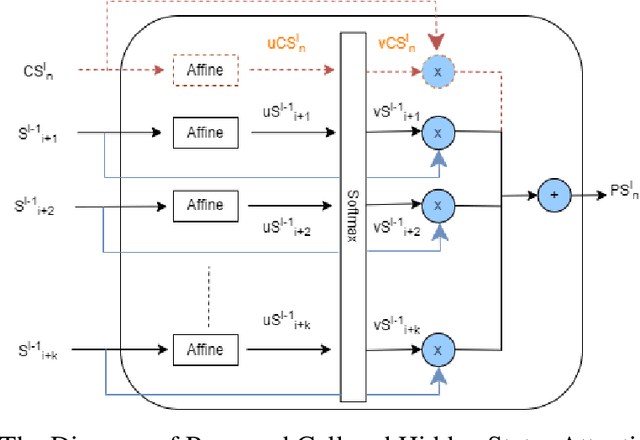
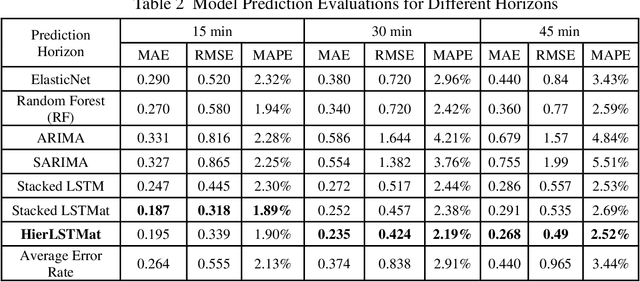
Travel time is essential in advanced traveler information systems (ATIS). This paper used the big data analytics engines Apache Spark and Apache MXNet for data processing and modeling. The efficiency gain was evaluated by comparing it with popular data science and deep learning frameworks. The hierarchical feature pooling is explored for both between layer and the output layer LSTM (Long-Short-Term-Memory). The designed hierarchical LSTM (hiLSTM) model can consider the dependencies at a different time scale to capture the spatial-temporal correlations from network-level corridor travel time. A self-attention module is then used to connect temporal and spatial features to the fully connected layers, predicting travel time for all corridors instead of a single link/route. Seasonality and autocorrelation were performed to explore the trend of time-varying data. The case study shows that the Hierarchical LSTM with Attention (hiLSTMat) model gives the best result and outperforms baseline models. The California Bay Area corridor travel time dataset covering four-year periods was published from Caltrans Performance Measurement System (PeMS) system.
High-fidelity 3D Model Compression based on Key Spheres
Jan 20, 2022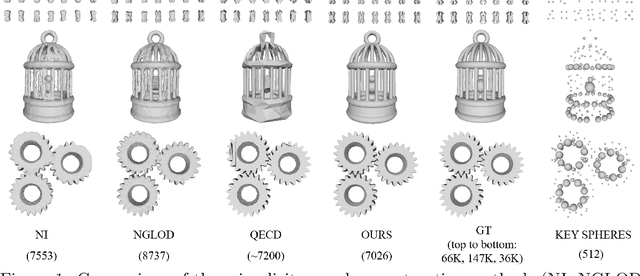
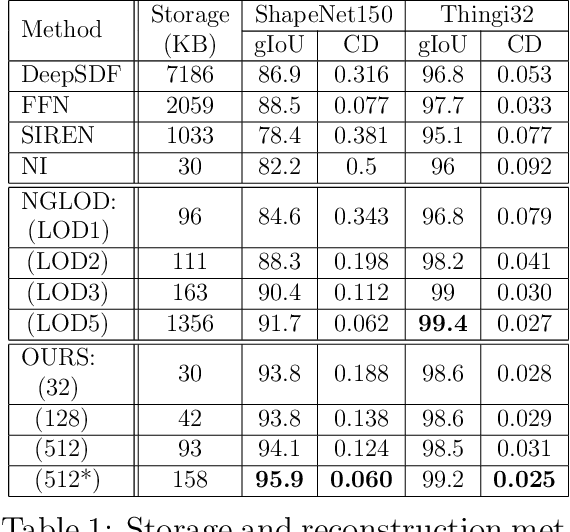
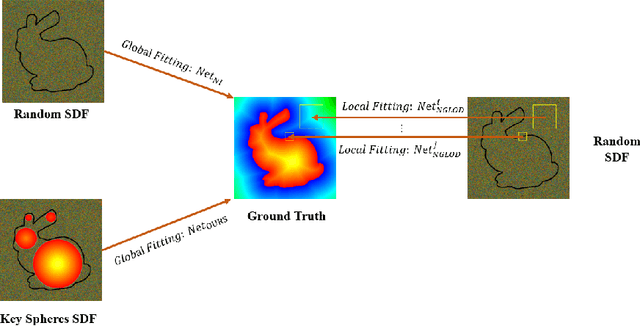
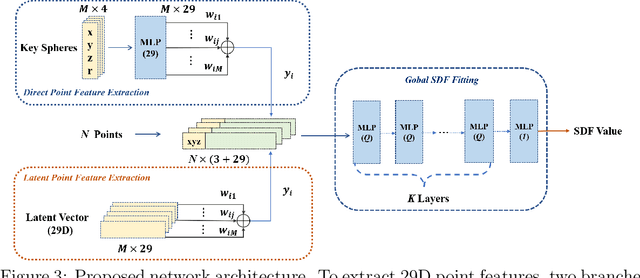
In recent years, neural signed distance function (SDF) has become one of the most effective representation methods for 3D models. By learning continuous SDFs in 3D space, neural networks can predict the distance from a given query space point to its closest object surface,whose positive and negative signs denote inside and outside of the object, respectively. Training a specific network for each 3D model, which individually embeds its shape, can realize compressed representation of objects by storing fewer network (and possibly latent) parameters. Consequently, reconstruction through network inference and surface recovery can be achieved. In this paper, we propose an SDF prediction network using explicit key spheres as input. Key spheres are extracted from the internal space of objects, whose centers either have relatively larger SDF values (sphere radii), or are located at essential positions. By inputting the spatial information of multiple spheres which imply different local shapes, the proposed method can significantly improve the reconstruction accuracy with a negligible storage cost. Compared to previous works, our method achieves the high-fidelity and high-compression 3D object coding and reconstruction. Experiments conducted on three datasets verify the superior performance of our method.
Nonnegative Tensor Completion via Integer Optimization
Nov 08, 2021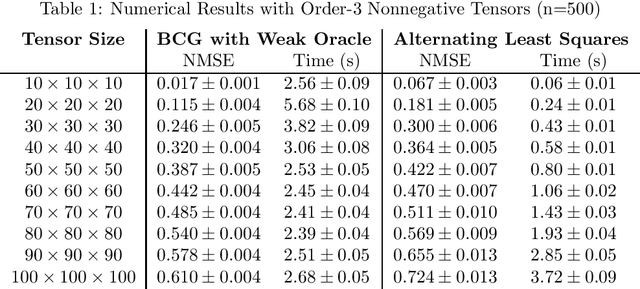

Unlike matrix completion, no algorithm for the tensor completion problem has so far been shown to achieve the information-theoretic sample complexity rate. This paper develops a new algorithm for the special case of completion for nonnegative tensors. We prove that our algorithm converges in a linear (in numerical tolerance) number of oracle steps, while achieving the information-theoretic rate. Our approach is to define a new norm for nonnegative tensors using the gauge of a specific 0-1 polytope that we construct. Because the norm is defined using a 0-1 polytope, this means we can use integer linear programming to solve linear separation problems over the polytope. We combine this insight with a variant of the Frank-Wolfe algorithm to construct our numerical algorithm, and we demonstrate its effectiveness and scalability through experiments.
Optimal SQ Lower Bounds for Learning Halfspaces with Massart Noise
Jan 24, 2022We give tight statistical query (SQ) lower bounds for learnining halfspaces in the presence of Massart noise. In particular, suppose that all labels are corrupted with probability at most $\eta$. We show that for arbitrary $\eta \in [0,1/2]$ every SQ algorithm achieving misclassification error better than $\eta$ requires queries of superpolynomial accuracy or at least a superpolynomial number of queries. Further, this continues to hold even if the information-theoretically optimal error $\mathrm{OPT}$ is as small as $\exp\left(-\log^c(d)\right)$, where $d$ is the dimension and $0 < c < 1$ is an arbitrary absolute constant, and an overwhelming fraction of examples are noiseless. Our lower bound matches known polynomial time algorithms, which are also implementable in the SQ framework. Previously, such lower bounds only ruled out algorithms achieving error $\mathrm{OPT} + \epsilon$ or error better than $\Omega(\eta)$ or, if $\eta$ is close to $1/2$, error $\eta - o_\eta(1)$, where the term $o_\eta(1)$ is constant in $d$ but going to 0 for $\eta$ approaching $1/2$. As a consequence, we also show that achieving misclassification error better than $1/2$ in the $(A,\alpha)$-Tsybakov model is SQ-hard for $A$ constant and $\alpha$ bounded away from 1.
Active Sensing for Communications by Learning
Dec 08, 2021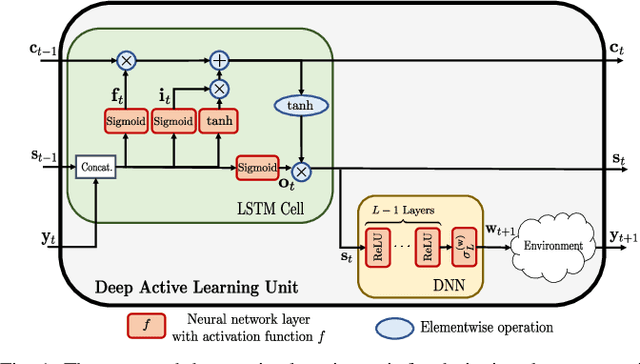
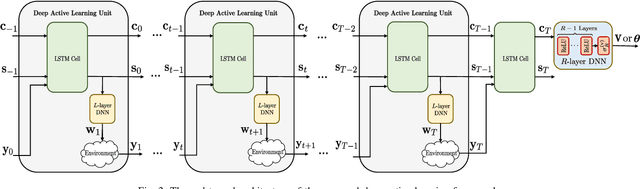
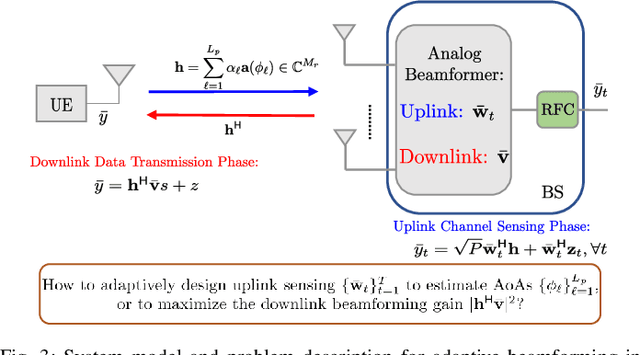
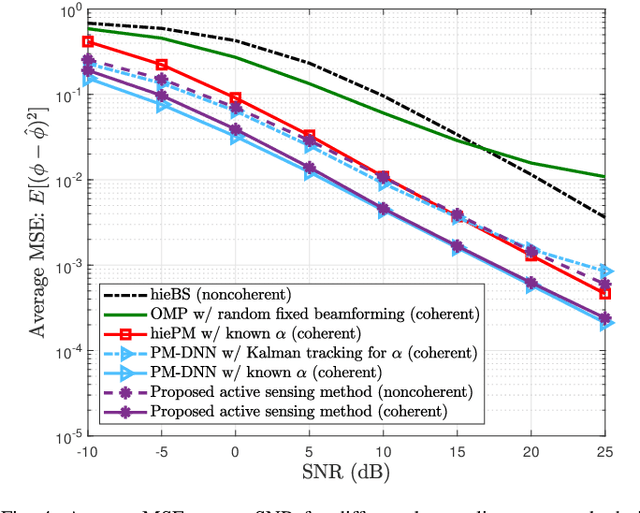
This paper proposes a deep learning approach to a class of active sensing problems in wireless communications in which an agent sequentially interacts with an environment over a predetermined number of time frames to gather information in order to perform a sensing or actuation task for maximizing some utility function. In such an active learning setting, the agent needs to design an adaptive sensing strategy sequentially based on the observations made so far. To tackle such a challenging problem in which the dimension of historical observations increases over time, we propose to use a long short-term memory (LSTM) network to exploit the temporal correlations in the sequence of observations and to map each observation to a fixed-size state information vector. We then use a deep neural network (DNN) to map the LSTM state at each time frame to the design of the next measurement step. Finally, we employ another DNN to map the final LSTM state to the desired solution. We investigate the performance of the proposed framework for adaptive channel sensing problems in wireless communications. In particular, we consider the adaptive beamforming problem for mmWave beam alignment and the adaptive reconfigurable intelligent surface sensing problem for reflection alignment. Numerical results demonstrate that the proposed deep active sensing strategy outperforms the existing adaptive or nonadaptive sensing schemes.
Interpretability in Convolutional Neural Networks for Building Damage Classification in Satellite Imagery
Jan 24, 2022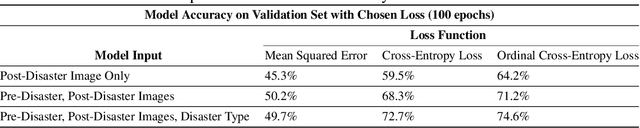
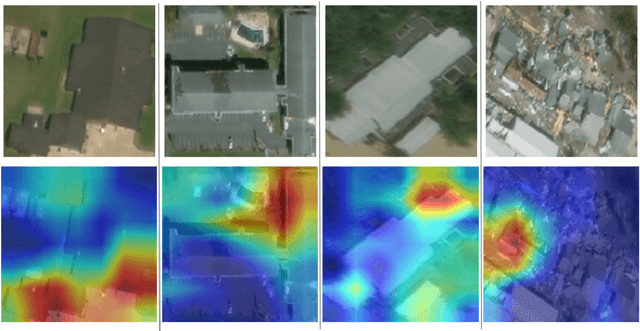

Natural disasters ravage the world's cities, valleys, and shores on a regular basis. Deploying precise and efficient computational mechanisms for assessing infrastructure damage is essential to channel resources and minimize the loss of life. Using a dataset that includes labeled pre- and post- disaster satellite imagery, we take a machine learning-based remote sensing approach and train multiple convolutional neural networks (CNNs) to assess building damage on a per-building basis. We present a novel methodology of interpretable deep learning that seeks to explicitly investigate the most useful modalities of information in the training data to create an accurate classification model. We also investigate which loss functions best optimize these models. Our findings include that ordinal-cross entropy loss is the most optimal criterion for optimization to use and that including the type of disaster that caused the damage in combination with pre- and post-disaster training data most accurately predicts the level of damage caused. Further, we make progress in the qualitative representation of which parts of the images that the model is using to predict damage levels, through gradient-weighted class activation mapping (Grad-CAM). Our research seeks to computationally contribute to aiding in this ongoing and growing humanitarian crisis, heightened by anthropogenic climate change.
Realistic Full-Body Anonymization with Surface-Guided GANs
Jan 06, 2022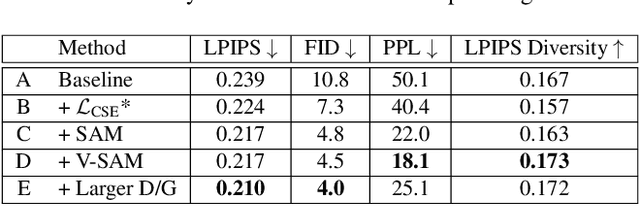

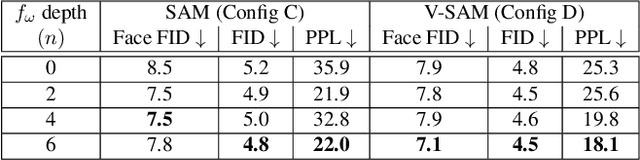
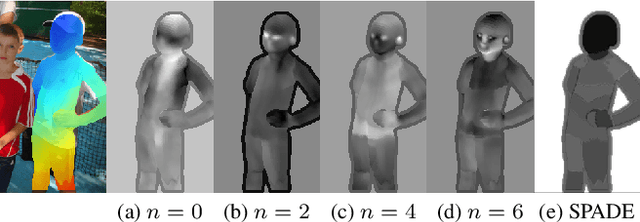
Recent work on image anonymization has shown that generative adversarial networks (GANs) can generate near-photorealistic faces to anonymize individuals. However, scaling these networks to the entire human body has remained a challenging and yet unsolved task. We propose a new anonymization method that generates close-to-photorealistic humans for in-the-wild images.A key part of our design is to guide adversarial nets by dense pixel-to-surface correspondences between an image and a canonical 3D surface.We introduce Variational Surface-Adaptive Modulation (V-SAM) that embeds surface information throughout the generator.Combining this with our novel discriminator surface supervision loss, the generator can synthesize high quality humans with diverse appearance in complex and varying scenes.We show that surface guidance significantly improves image quality and diversity of samples, yielding a highly practical generator.Finally, we demonstrate that surface-guided anonymization preserves the usability of data for future computer vision development
Semantic of Cloud Computing services for Time Series workflows
Feb 01, 2022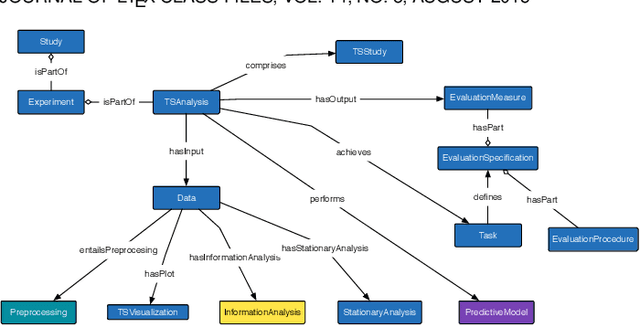
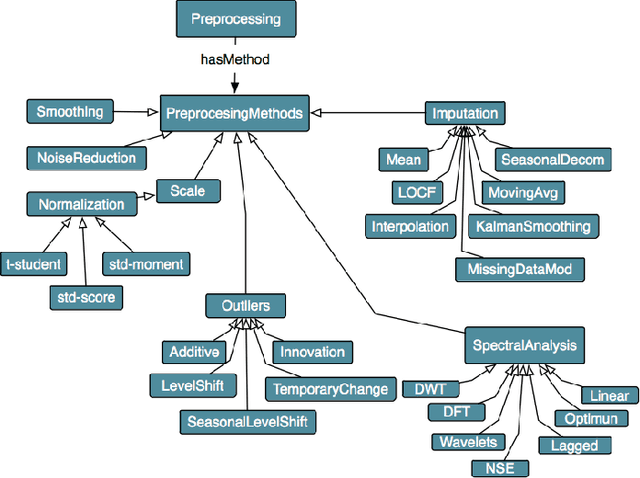
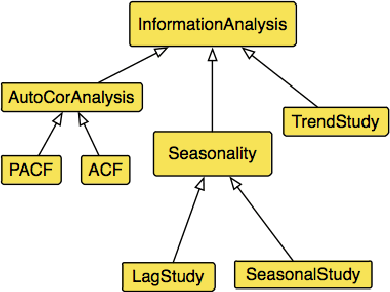
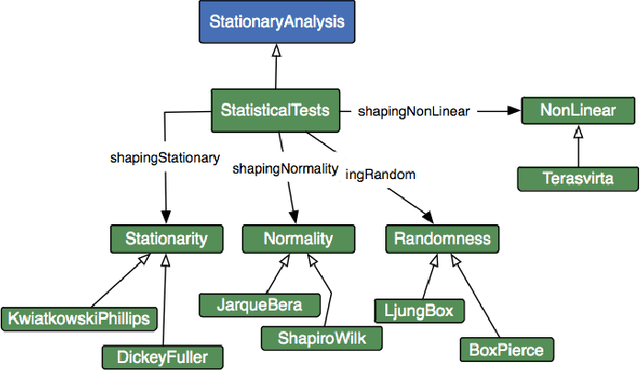
Time series (TS) are present in many fields of knowledge, research, and engineering. The processing and analysis of TS are essential in order to extract knowledge from the data and to tackle forecasting or predictive maintenance tasks among others The modeling of TS is a challenging task, requiring high statistical expertise as well as outstanding knowledge about the application of Data Mining(DM) and Machine Learning (ML) methods. The overall work with TS is not limited to the linear application of several techniques, but is composed of an open workflow of methods and tests. These workflow, developed mainly on programming languages, are complicated to execute and run effectively on different systems, including Cloud Computing (CC) environments. The adoption of CC can facilitate the integration and portability of services allowing to adopt solutions towards services Internet Technologies (IT) industrialization. The definition and description of workflow services for TS open up a new set of possibilities regarding the reduction of complexity in the deployment of this type of issues in CC environments. In this sense, we have designed an effective proposal based on semantic modeling (or vocabulary) that provides the full description of workflow for Time Series modeling as a CC service. Our proposal includes a broad spectrum of the most extended operations, accommodating any workflow applied to classification, regression, or clustering problems for Time Series, as well as including evaluation measures, information, tests, or machine learning algorithms among others.
Communication-Efficient Device Scheduling for Federated Learning Using Stochastic Optimization
Jan 19, 2022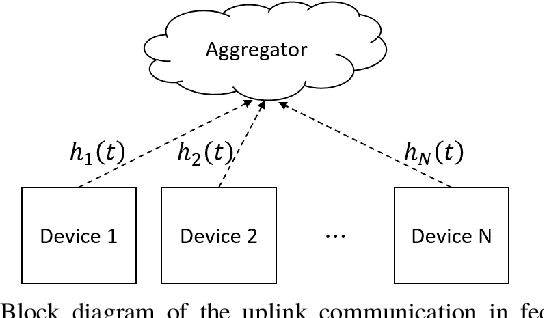
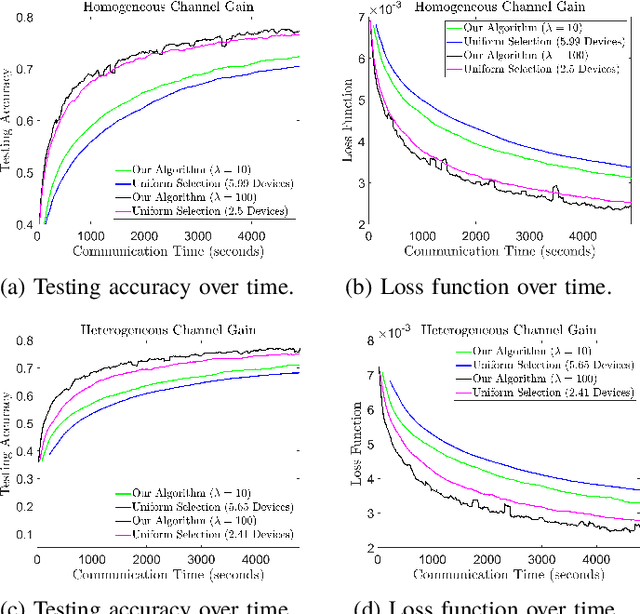
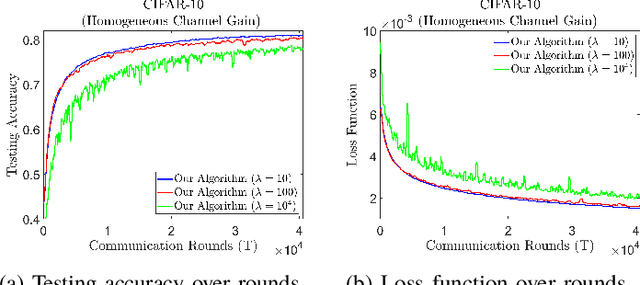
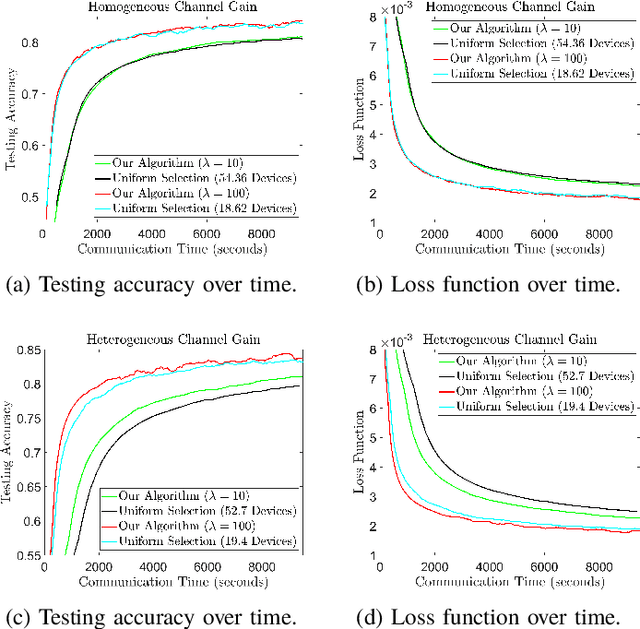
Federated learning (FL) is a useful tool in distributed machine learning that utilizes users' local datasets in a privacy-preserving manner. When deploying FL in a constrained wireless environment; however, training models in a time-efficient manner can be a challenging task due to intermittent connectivity of devices, heterogeneous connection quality, and non-i.i.d. data. In this paper, we provide a novel convergence analysis of non-convex loss functions using FL on both i.i.d. and non-i.i.d. datasets with arbitrary device selection probabilities for each round. Then, using the derived convergence bound, we use stochastic optimization to develop a new client selection and power allocation algorithm that minimizes a function of the convergence bound and the average communication time under a transmit power constraint. We find an analytical solution to the minimization problem. One key feature of the algorithm is that knowledge of the channel statistics is not required and only the instantaneous channel state information needs to be known. Using the FEMNIST and CIFAR-10 datasets, we show through simulations that the communication time can be significantly decreased using our algorithm, compared to uniformly random participation.