 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Context-Aware Neural Performance-Score Synchronisation
May 31, 2022
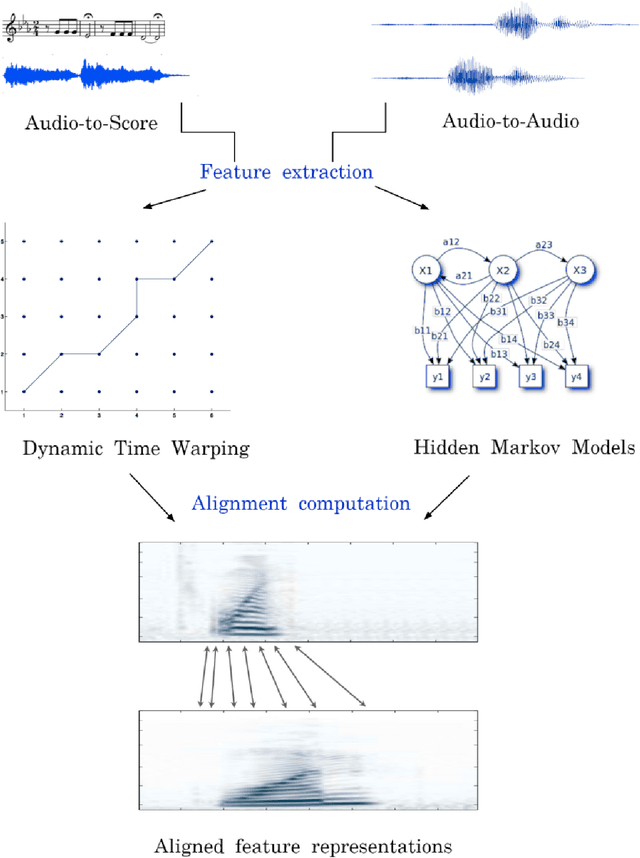
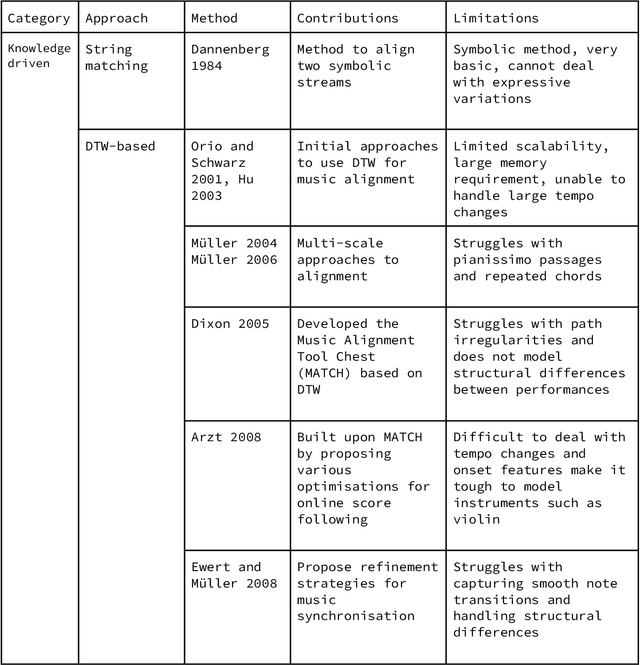

Music can be represented in multiple forms, such as in the audio form as a recording of a performance, in the symbolic form as a computer readable score, or in the image form as a scan of the sheet music. Music synchronisation provides a way to navigate among multiple representations of music in a unified manner by generating an accurate mapping between them, lending itself applicable to a myriad of domains like music education, performance analysis, automatic accompaniment and music editing. Traditional synchronisation methods compute alignment using knowledge-driven and stochastic approaches, typically employing handcrafted features. These methods are often unable to generalise well to different instruments, acoustic environments and recording conditions, and normally assume complete structural agreement between the performances and the scores. This PhD furthers the development of performance-score synchronisation research by proposing data-driven, context-aware alignment approaches, on three fronts: Firstly, I replace the handcrafted features by employing a metric learning based approach that is adaptable to different acoustic settings and performs well in data-scarce conditions. Secondly, I address the handling of structural differences between the performances and scores, which is a common limitation of standard alignment methods. Finally, I eschew the reliance on both feature engineering and dynamic programming, and propose a completely data-driven synchronisation method that computes alignments using a neural framework, whilst also being robust to structural differences between the performances and scores.
Lagrangian Motion Magnification with Double Sparse Optical Flow Decomposition
Apr 15, 2022
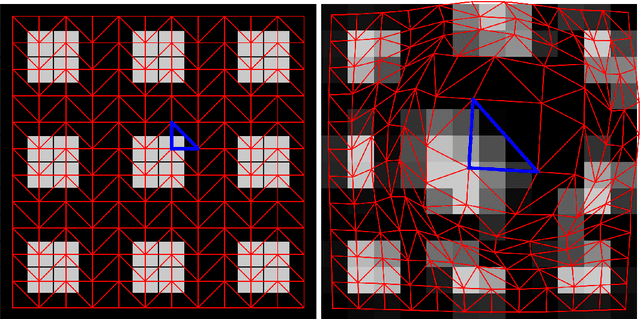
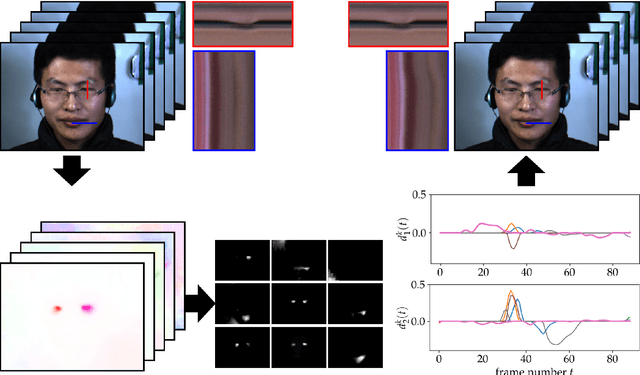
Motion magnification techniques aim at amplifying and hence revealing subtle motion in videos. There are basically two main approaches to reach this goal, namely via Eulerian or Lagrangian techniques. While the first one magnifies motion implicitly by operating directly on image pixels, the Lagrangian approach uses optical flow techniques to extract and amplify pixel trajectories. Microexpressions are fast and spatially small facial expressions that are difficult to detect. In this paper, we propose a novel approach for local Lagrangian motion magnification of facial micromovements. Our contribution is three-fold: first, we fine-tune the recurrent all-pairs field transforms for optical flows (RAFT) deep learning approach for faces by adding ground truth obtained from the variational dense inverse search (DIS) for optical flow algorithm applied to the CASME II video set of faces. This enables us to produce optical flows of facial videos in an efficient and sufficiently accurate way. Second, since facial micromovements are both local in space and time, we propose to approximate the optical flow field by sparse components both in space and time leading to a double sparse decomposition. Third, we use this decomposition to magnify micro-motions in specific areas of the face, where we introduce a new forward warping strategy using a triangular splitting of the image grid and barycentric interpolation of the RGB vectors at the corners of the transformed triangles. We demonstrate the very good performance of our approach by various examples.
Fine-Grained Visual Entailment
Mar 29, 2022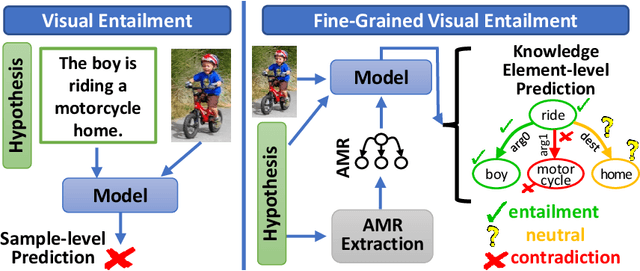
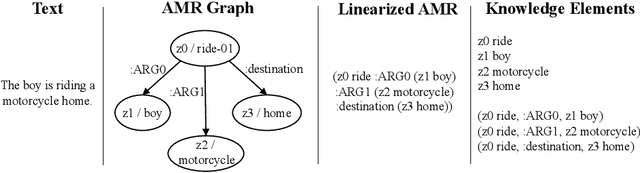
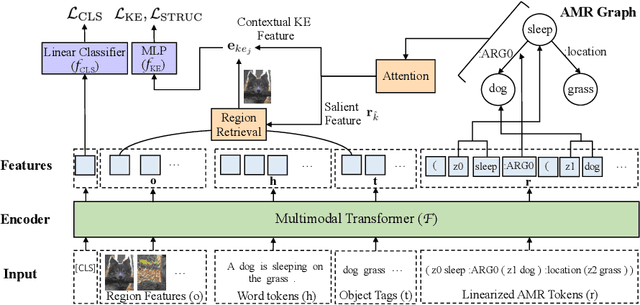
Visual entailment is a recently proposed multimodal reasoning task where the goal is to predict the logical relationship of a piece of text to an image. In this paper, we propose an extension of this task, where the goal is to predict the logical relationship of fine-grained knowledge elements within a piece of text to an image. Unlike prior work, our method is inherently explainable and makes logical predictions at different levels of granularity. Because we lack fine-grained labels to train our method, we propose a novel multi-instance learning approach which learns a fine-grained labeling using only sample-level supervision. We also impose novel semantic structural constraints which ensure that fine-grained predictions are internally semantically consistent. We evaluate our method on a new dataset of manually annotated knowledge elements and show that our method achieves 68.18\% accuracy at this challenging task while significantly outperforming several strong baselines. Finally, we present extensive qualitative results illustrating our method's predictions and the visual evidence our method relied on. Our code and annotated dataset can be found here: https://github.com/SkrighYZ/FGVE.
Nonlinear motion separation via untrained generator networks with disentangled latent space variables and applications to cardiac MRI
May 20, 2022
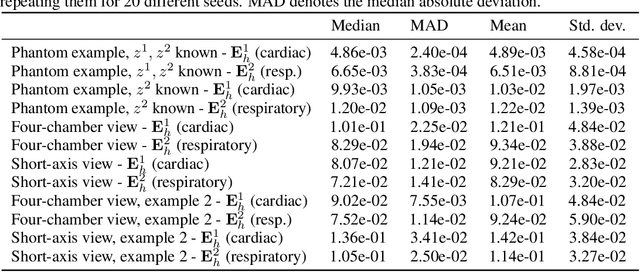
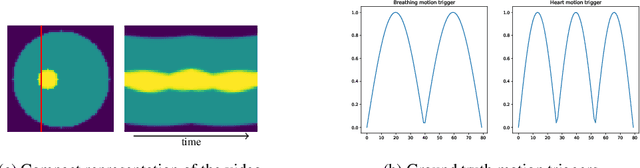
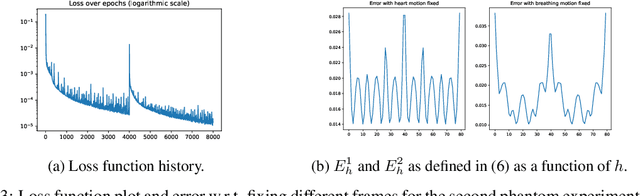
In this paper, a nonlinear approach to separate different motion types in video data is proposed. This is particularly relevant in dynamic medical imaging (e.g. PET, MRI), where patient motion poses a significant challenge due to its effects on the image reconstruction as well as for its subsequent interpretation. Here, a new method is proposed where dynamic images are represented as the forward mapping of a sequence of latent variables via a generator neural network. The latent variables are structured so that temporal variations in the data are represented via dynamic latent variables, which are independent of static latent variables characterizing the general structure of the frames. In particular, different kinds of motion are also characterized independently of each other via latent space disentanglement using one-dimensional prior information on all but one of the motion types. This representation allows to freeze any selection of motion types, and to obtain accurate independent representations of other dynamics of interest. Moreover, the proposed algorithm is training-free, i.e., all the network parameters are learned directly from a single video. We illustrate the performance of this method on phantom and real-data MRI examples, where we successfully separate respiratory and cardiac motion.
Dynamic Dual-Output Diffusion Models
Mar 15, 2022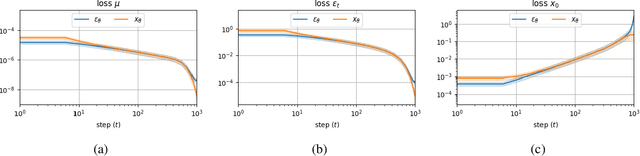
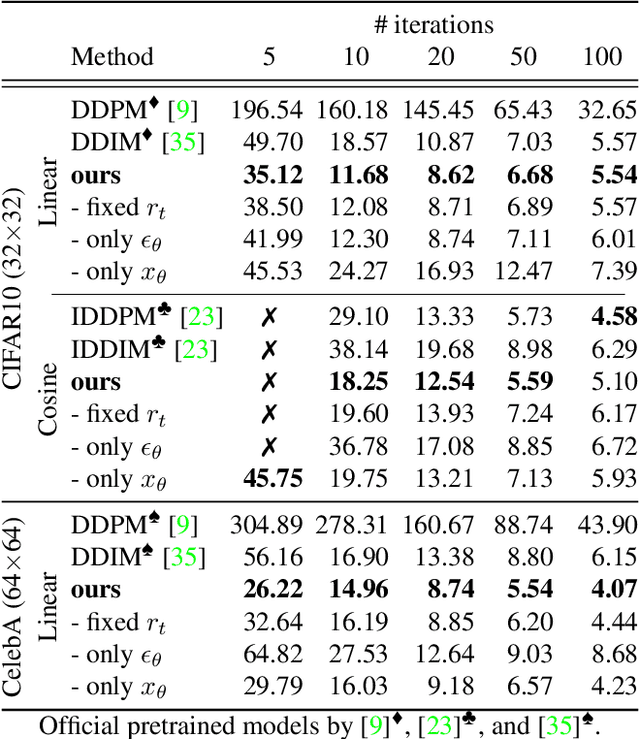
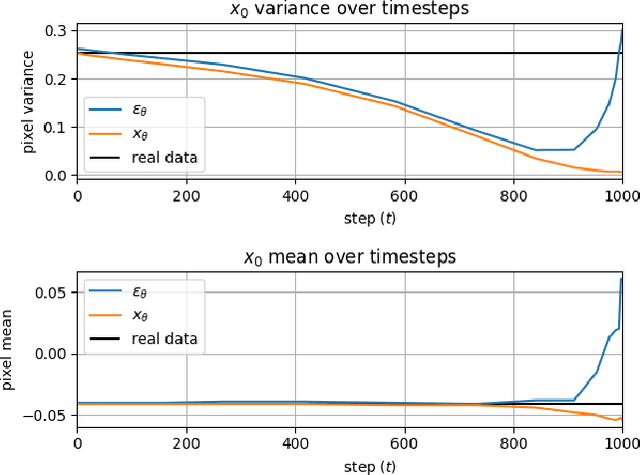
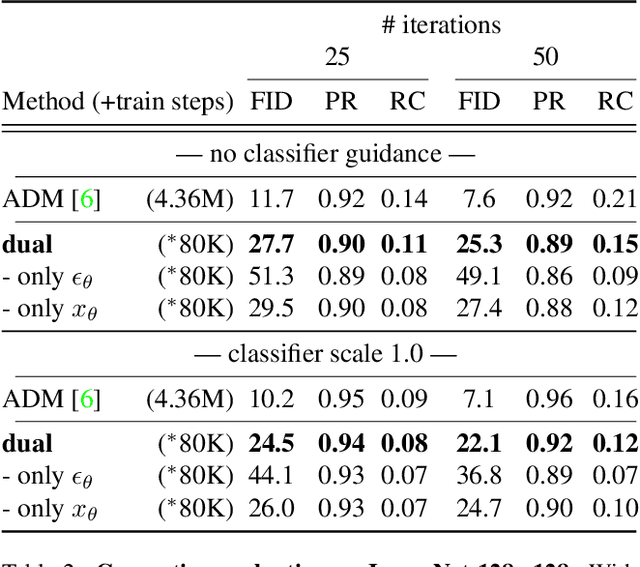
Iterative denoising-based generation, also known as denoising diffusion models, has recently been shown to be comparable in quality to other classes of generative models, and even surpass them. Including, in particular, Generative Adversarial Networks, which are currently the state of the art in many sub-tasks of image generation. However, a major drawback of this method is that it requires hundreds of iterations to produce a competitive result. Recent works have proposed solutions that allow for faster generation with fewer iterations, but the image quality gradually deteriorates with increasingly fewer iterations being applied during generation. In this paper, we reveal some of the causes that affect the generation quality of diffusion models, especially when sampling with few iterations, and come up with a simple, yet effective, solution to mitigate them. We consider two opposite equations for the iterative denoising, the first predicts the applied noise, and the second predicts the image directly. Our solution takes the two options and learns to dynamically alternate between them through the denoising process. Our proposed solution is general and can be applied to any existing diffusion model. As we show, when applied to various SOTA architectures, our solution immediately improves their generation quality, with negligible added complexity and parameters. We experiment on multiple datasets and configurations and run an extensive ablation study to support these findings.
A New Gastric Histopathology Subsize Image Database (GasHisSDB) for Classification Algorithm Test: from Linear Regression to Visual Transformer
Jun 04, 2021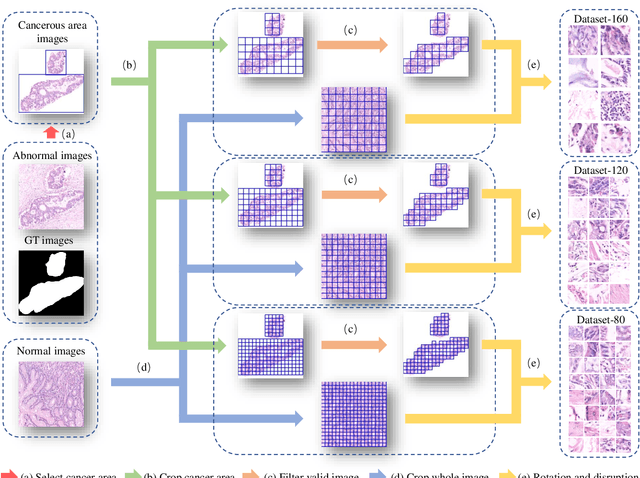
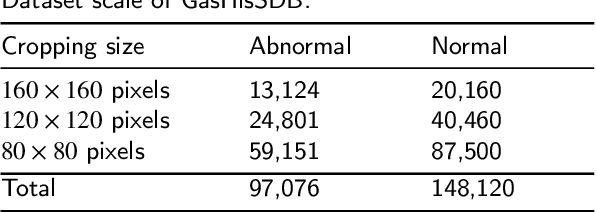
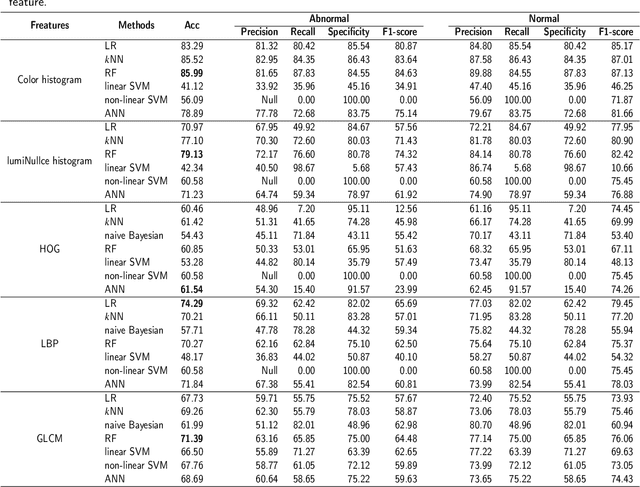
GasHisSDB is a New Gastric Histopathology Subsize Image Database with a total of 245196 images. GasHisSDB is divided into 160*160 pixels sub-database, 120*120 pixels sub-database and 80*80 pixels sub-database. GasHisSDB is made to realize the function of valuating image classification. In order to prove that the methods of different periods in the field of image classification have discrepancies on GasHisSDB, we select a variety of classifiers for evaluation. Seven classical machine learning classifiers, three CNN classifiers and a novel transformer-based classifier are selected for testing on image classification tasks. GasHisSDB is available at the URL:https://github.com/NEUhwm/GasHisSDB.git.
Hardware System Implementation for Human Detection using HOG and SVM Algorithm
May 05, 2022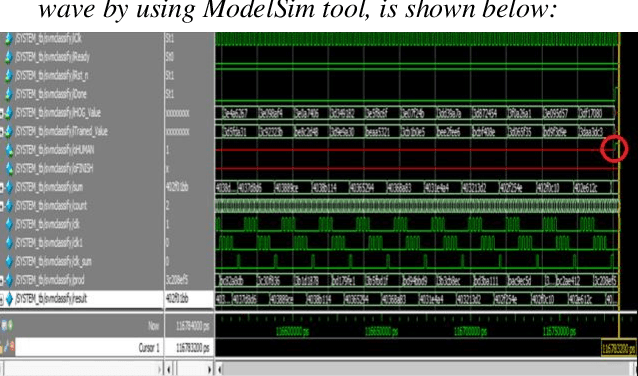
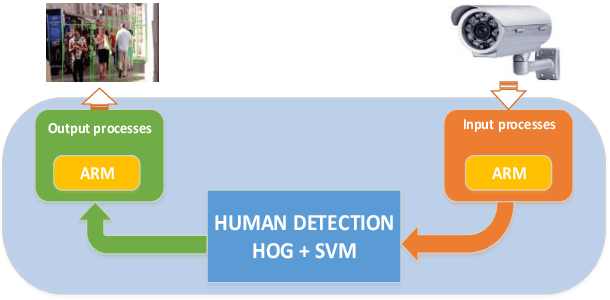


Human detection is a popular issue and has been widely used in many applications. However, including complexities in computation, leading to the human detection system implemented hardly in real-time applications. This paper presents the architecture of hardware, a human detection system that was simulated in the ModelSim tool. As a co-processor, this system was built to off-load to Central Processor Unit (CPU) and speed up the computation timing. The 130x66 RGB pixels of static input image attracted features and classify by using the Histogram of Oriented Gradient (HOG) algorithm and Support Vector Machine (SVM) algorithm, respectively. As a result, the accuracy rate of this system reaches 84.35 percent. And the timing for detection decreases to 0.757 ms at 50MHz frequency (54 times faster when this system was implemented in software by using the Matlab tool).
Improving Style-Content Disentanglement in Image-to-Image Translation
Jul 09, 2020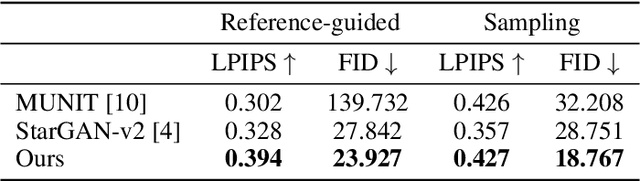

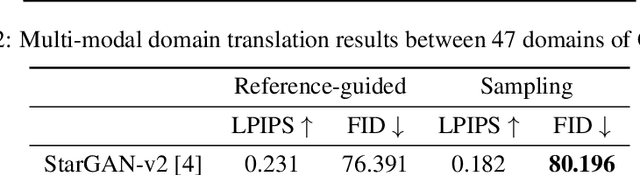

Unsupervised image-to-image translation methods have achieved tremendous success in recent years. However, it can be easily observed that their models contain significant entanglement which often hurts the translation performance. In this work, we propose a principled approach for improving style-content disentanglement in image-to-image translation. By considering the information flow into each of the representations, we introduce an additional loss term which serves as a content-bottleneck. We show that the results of our method are significantly more disentangled than those produced by current methods, while further improving the visual quality and translation diversity.
Resource-Aware Distributed Submodular Maximization: A Paradigm for Multi-Robot Decision-Making
Apr 15, 2022
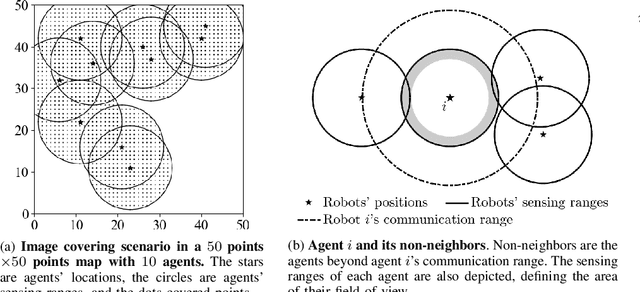
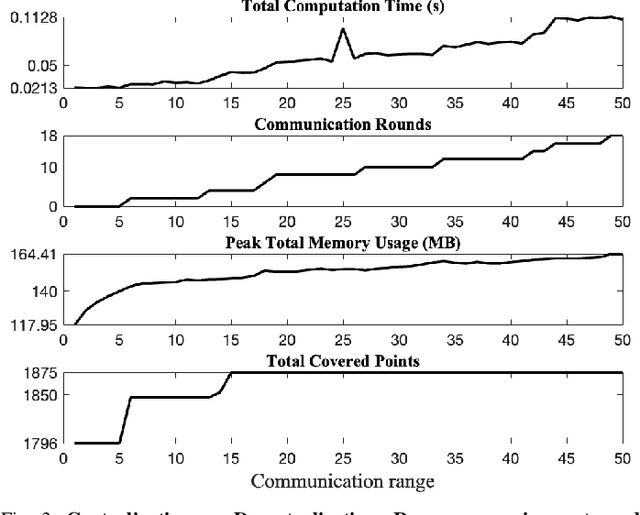
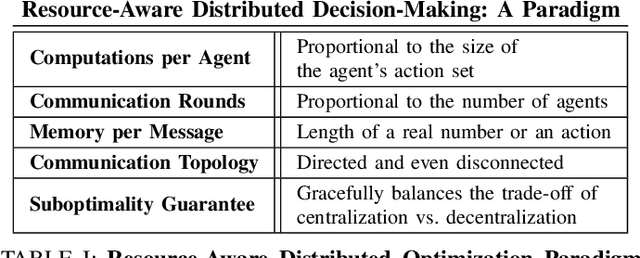
We introduce the first algorithm for distributed decision-making that provably balances the trade-off of centralization, for global near-optimality, vs. decentralization, for near-minimal on-board computation, communication, and memory resources. We are motivated by the future of autonomy that involves heterogeneous robots collaborating in complex~tasks, such as image covering, target tracking, and area monitoring. Current algorithms, such as consensus algorithms, are insufficient to fulfill this future: they achieve distributed communication only, at the expense of high communication, computation, and memory overloads. A shift to resource-aware algorithms is needed, that can account for each robot's on-board resources, independently. We provide the first resource-aware algorithm, Resource-Aware distributed Greedy (RAG). We focus on maximization problems involving monotone and "doubly" submodular functions, a diminishing returns property. RAG has near-minimal on-board resource requirements. Each agent can afford to run the algorithm by adjusting the size of its neighborhood, even if that means selecting actions in complete isolation. RAG has provable approximation performance, where each agent can independently determine its contribution. All in all, RAG is the first algorithm to quantify the trade-off of centralization, for global near-optimality, vs. decentralization, for near-minimal on-board resource requirements. To capture the trade-off, we introduce the notion of Centralization Of Information among non-Neighbors (COIN). We validate RAG in simulated scenarios of image covering with mobile robots.
Estimating Fine-Grained Noise Model via Contrastive Learning
Apr 03, 2022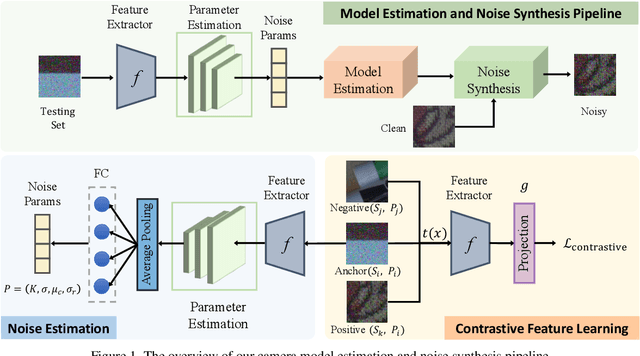
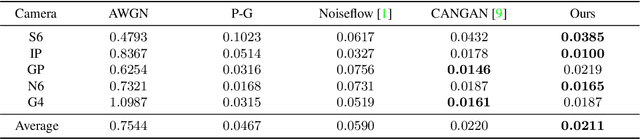
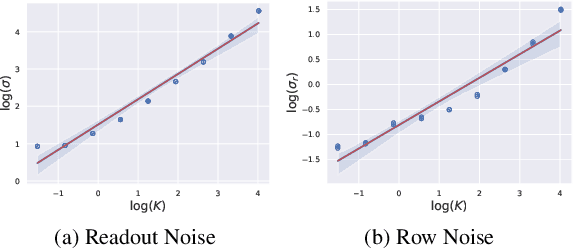
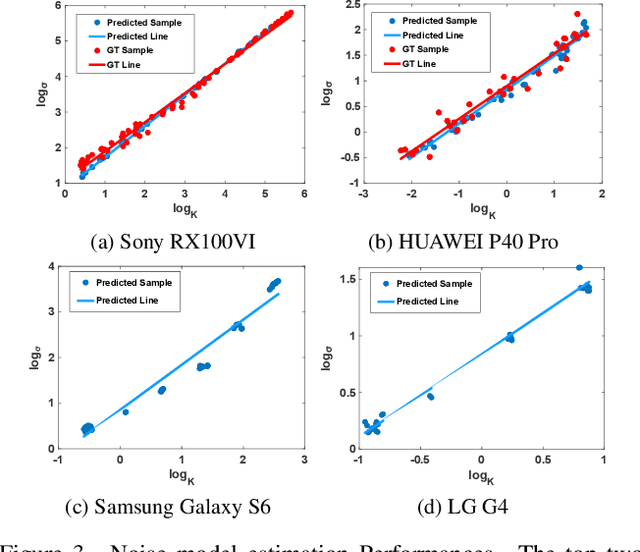
Image denoising has achieved unprecedented progress as great efforts have been made to exploit effective deep denoisers. To improve the denoising performance in realworld, two typical solutions are used in recent trends: devising better noise models for the synthesis of more realistic training data, and estimating noise level function to guide non-blind denoisers. In this work, we combine both noise modeling and estimation, and propose an innovative noise model estimation and noise synthesis pipeline for realistic noisy image generation. Specifically, our model learns a noise estimation model with fine-grained statistical noise model in a contrastive manner. Then, we use the estimated noise parameters to model camera-specific noise distribution, and synthesize realistic noisy training data. The most striking thing for our work is that by calibrating noise models of several sensors, our model can be extended to predict other cameras. In other words, we can estimate cameraspecific noise models for unknown sensors with only testing images, without laborious calibration frames or paired noisy/clean data. The proposed pipeline endows deep denoisers with competitive performances with state-of-the-art real noise modeling methods.