 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVgmidi
Papers and Code
Let the Model Learn to Feel: Mode-Guided Tonality Injection for Symbolic Music Emotion Recognition
Dec 15, 2025Music emotion recognition is a key task in symbolic music understanding (SMER). Recent approaches have shown promising results by fine-tuning large-scale pre-trained models (e.g., MIDIBERT, a benchmark in symbolic music understanding) to map musical semantics to emotional labels. While these models effectively capture distributional musical semantics, they often overlook tonal structures, particularly musical modes, which play a critical role in emotional perception according to music psychology. In this paper, we investigate the representational capacity of MIDIBERT and identify its limitations in capturing mode-emotion associations. To address this issue, we propose a Mode-Guided Enhancement (MoGE) strategy that incorporates psychological insights on mode into the model. Specifically, we first conduct a mode augmentation analysis, which reveals that MIDIBERT fails to effectively encode emotion-mode correlations. We then identify the least emotion-relevant layer within MIDIBERT and introduce a Mode-guided Feature-wise linear modulation injection (MoFi) framework to inject explicit mode features, thereby enhancing the model's capability in emotional representation and inference. Extensive experiments on the EMOPIA and VGMIDI datasets demonstrate that our mode injection strategy significantly improves SMER performance, achieving accuracies of 75.2% and 59.1%, respectively. These results validate the effectiveness of mode-guided modeling in symbolic music emotion recognition.
A Novel Multi-Task Learning Method for Symbolic Music Emotion Recognition
Jan 15, 2022


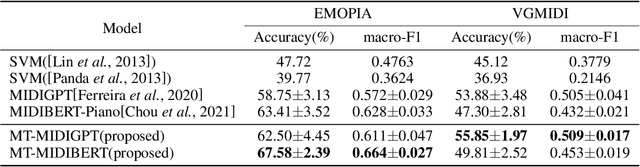
Symbolic Music Emotion Recognition(SMER) is to predict music emotion from symbolic data, such as MIDI and MusicXML. Previous work mainly focused on learning better representation via (mask) language model pre-training but ignored the intrinsic structure of the music, which is extremely important to the emotional expression of music. In this paper, we present a simple multi-task framework for SMER, which incorporates the emotion recognition task with other emotion-related auxiliary tasks derived from the intrinsic structure of the music. The results show that our multi-task framework can be adapted to different models. Moreover, the labels of auxiliary tasks are easy to be obtained, which means our multi-task methods do not require manually annotated labels other than emotion. Conducting on two publicly available datasets (EMOPIA and VGMIDI), the experiments show that our methods perform better in SMER task. Specifically, accuracy has been increased by 4.17 absolute point to 67.58 in EMOPIA dataset, and 1.97 absolute point to 55.85 in VGMIDI dataset. Ablation studies also show the effectiveness of multi-task methods designed in this paper.