 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentimix
Papers and Code
Palomino-Ochoa at SemEval-2020 Task 9: Robust System based on Transformer for Code-Mixed Sentiment Classification
Nov 18, 2020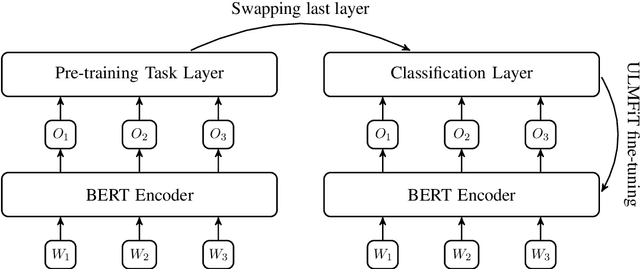


We present a transfer learning system to perform a mixed Spanish-English sentiment classification task. Our proposal uses the state-of-the-art language model BERT and embed it within a ULMFiT transfer learning pipeline. This combination allows us to predict the polarity detection of code-mixed (English-Spanish) tweets. Thus, among 29 submitted systems, our approach (referred to as dplominop) is ranked 4th on the Sentimix Spanglish test set of SemEval 2020 Task 9. In fact, our system yields the weighted-F1 score value of 0.755 which can be easily reproduced -- the source code and implementation details are made available.
JUNLP@SemEval-2020 Task 9:Sentiment Analysis of Hindi-English code mixed data using Grid Search Cross Validation
Sep 02, 2020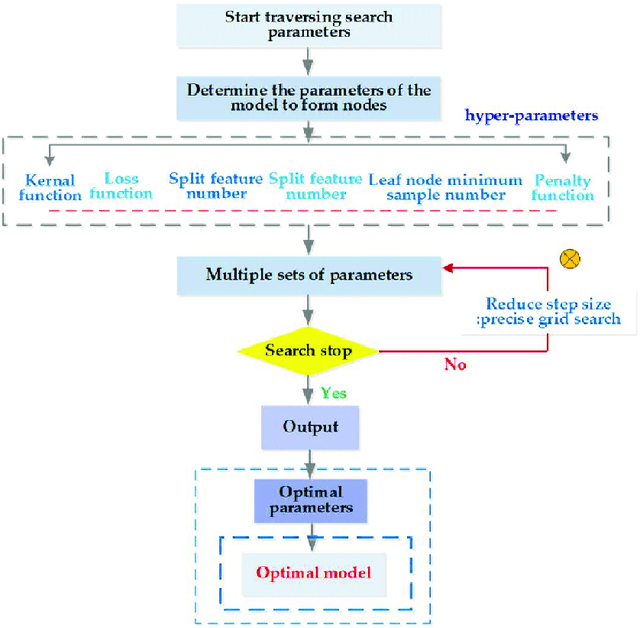
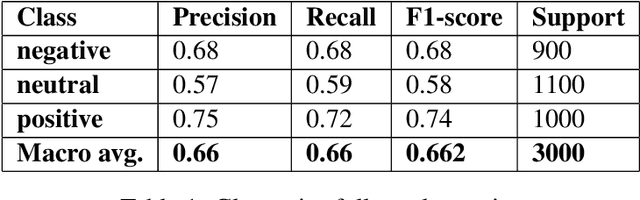
Code-mixing is a phenomenon which arises mainly in multilingual societies. Multilingual people, who are well versed in their native languages and also English speakers, tend to code-mix using English-based phonetic typing and the insertion of anglicisms in their main language. This linguistic phenomenon poses a great challenge to conventional NLP domains such as Sentiment Analysis, Machine Translation, and Text Summarization, to name a few. In this work, we focus on working out a plausible solution to the domain of Code-Mixed Sentiment Analysis. This work was done as participation in the SemEval-2020 Sentimix Task, where we focused on the sentiment analysis of English-Hindi code-mixed sentences. our username for the submission was "sainik.mahata" and team name was "JUNLP". We used feature extraction algorithms in conjunction with traditional machine learning algorithms such as SVR and Grid Search in an attempt to solve the task. Our approach garnered an f1-score of 66.2\% when tested using metrics prepared by the organizers of the task.
LIMSI_UPV at SemEval-2020 Task 9: Recurrent Convolutional Neural Network for Code-mixed Sentiment Analysis
Aug 30, 2020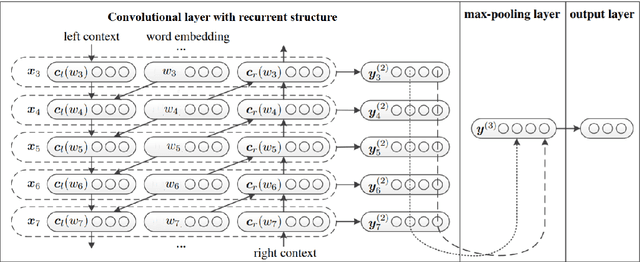
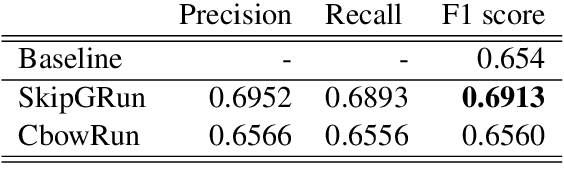

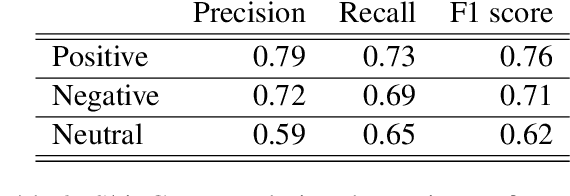
This paper describes the participation of LIMSI UPV team in SemEval-2020 Task 9: Sentiment Analysis for Code-Mixed Social Media Text. The proposed approach competed in SentiMix Hindi-English subtask, that addresses the problem of predicting the sentiment of a given Hindi-English code-mixed tweet. We propose Recurrent Convolutional Neural Network that combines both the recurrent neural network and the convolutional network to better capture the semantics of the text, for code-mixed sentiment analysis. The proposed system obtained 0.69 (best run) in terms of F1 score on the given test data and achieved the 9th place (Codalab username: somban) in the SentiMix Hindi-English subtask.
SemEval-2020 Task 9: Overview of Sentiment Analysis of Code-Mixed Tweets
Aug 10, 2020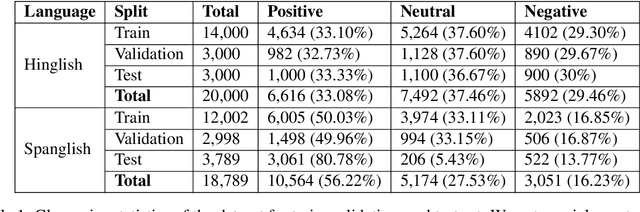
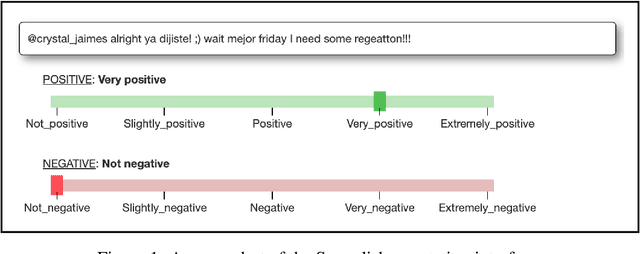

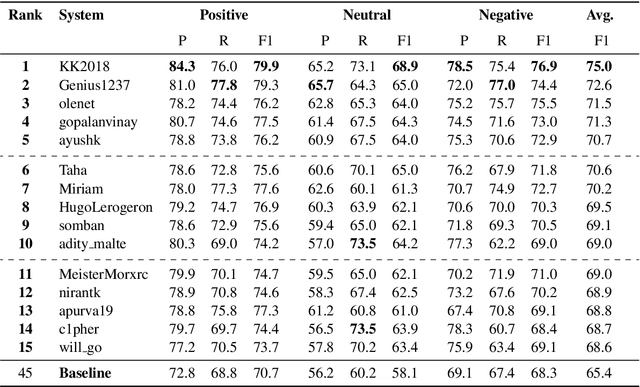
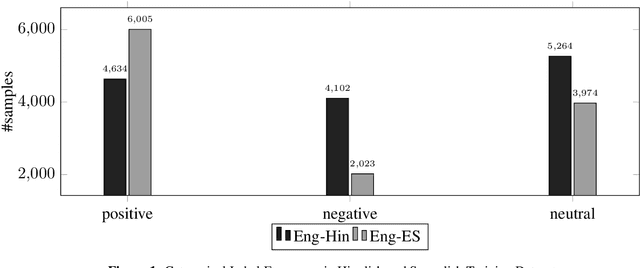
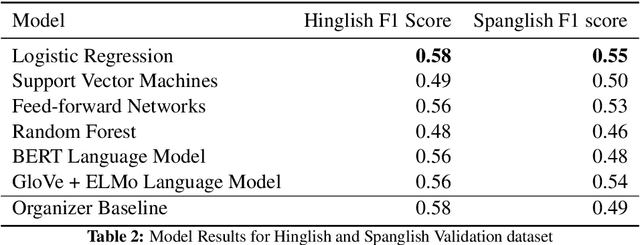
In this paper, we present the results of the SemEval-2020 Task 9 on Sentiment Analysis of Code-Mixed Tweets (SentiMix 2020). We also release and describe our Hinglish (Hindi-English) and Spanglish (Spanish-English) corpora annotated with word-level language identification and sentence-level sentiment labels. These corpora are comprised of 20K and 19K examples, respectively. The sentiment labels are - Positive, Negative, and Neutral. SentiMix attracted 89 submissions in total including 61 teams that participated in the Hinglish contest and 28 submitted systems to the Spanglish competition. The best performance achieved was 75.0% F1 score for Hinglish and 80.6% F1 for Spanglish. We observe that BERT-like models and ensemble methods are the most common and successful approaches among the participants.
C1 at SemEval-2020 Task 9: SentiMix: Sentiment Analysis for Code-Mixed Social Media Text using Feature Engineering
Aug 09, 2020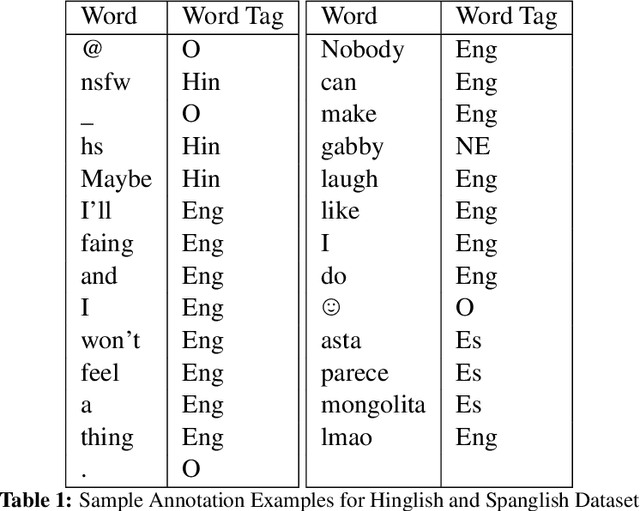

In today's interconnected and multilingual world, code-mixing of languages on social media is a common occurrence. While many Natural Language Processing (NLP) tasks like sentiment analysis are mature and well designed for monolingual text, techniques to apply these tasks to code-mixed text still warrant exploration. This paper describes our feature engineering approach to sentiment analysis in code-mixed social media text for SemEval-2020 Task 9: SentiMix. We tackle this problem by leveraging a set of hand-engineered lexical, sentiment, and metadata features to design a classifier that can disambiguate between "positive", "negative" and "neutral" sentiment. With this model, we are able to obtain a weighted F1 score of 0.65 for the "Hinglish" task and 0.63 for the "Spanglish" tasks
Reed at SemEval-2020 Task 9: Fine-Tuning and Bag-of-Words Approaches to Code-Mixed Sentiment Analysis
Aug 04, 2020
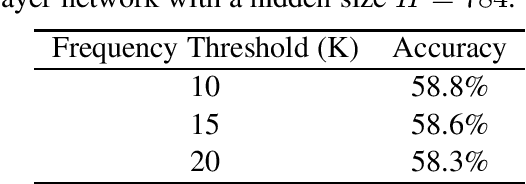


We explore the task of sentiment analysis on Hinglish (code-mixed Hindi-English) tweets as participants of Task 9 of the SemEval-2020 competition, known as the SentiMix task. We had two main approaches: 1) applying transfer learning by fine-tuning pre-trained BERT models and 2) training feedforward neural networks on bag-of-words representations. During the evaluation phase of the competition, we obtained an F-score of 71.3% with our best model, which placed $4^{th}$ out of 62 entries in the official system rankings.
ULD@NUIG at SemEval-2020 Task 9: Generative Morphemes with an Attention Model for Sentiment Analysis in Code-Mixed Text
Jul 27, 2020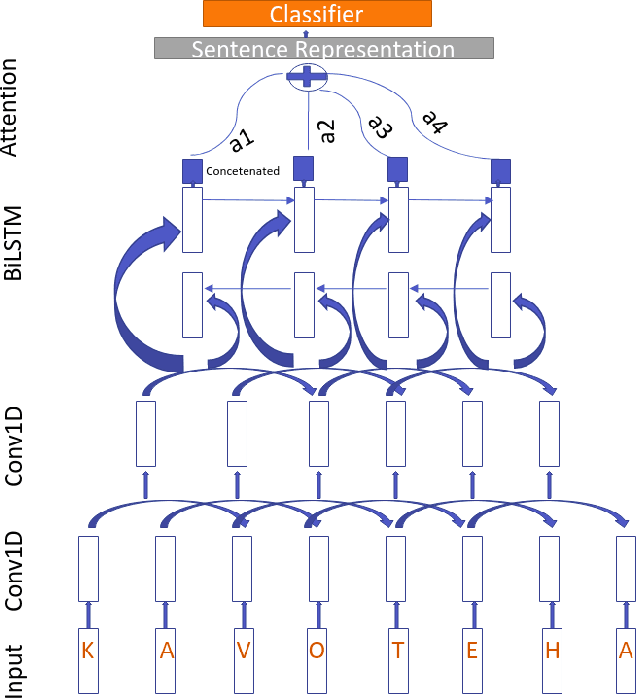
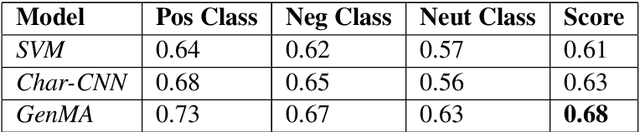
Code mixing is a common phenomena in multilingual societies where people switch from one language to another for various reasons. Recent advances in public communication over different social media sites have led to an increase in the frequency of code-mixed usage in written language. In this paper, we present the Generative Morphemes with Attention (GenMA) Model sentiment analysis system contributed to SemEval 2020 Task 9 SentiMix. The system aims to predict the sentiments of the given English-Hindi code-mixed tweets without using word-level language tags instead inferring this automatically using a morphological model. The system is based on a novel deep neural network (DNN) architecture, which has outperformed the baseline F1-score on the test data-set as well as the validation data-set. Our results can be found under the user name "koustava" on the "Sentimix Hindi English" page
NITS-Hinglish-SentiMix at SemEval-2020 Task 9: Sentiment Analysis For Code-Mixed Social Media Text
Jul 23, 2020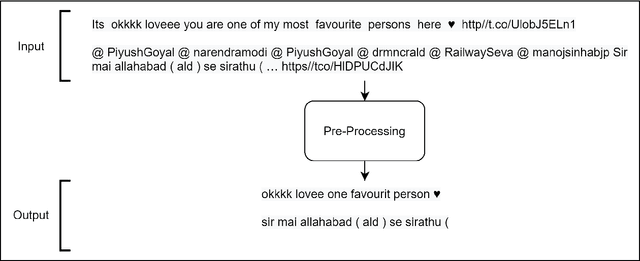

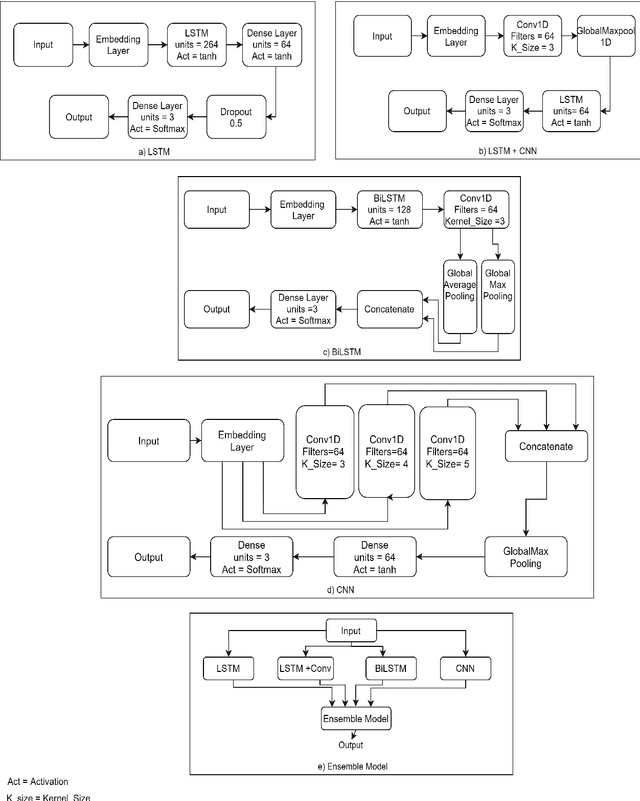

Sentiment Analysis is the process of deciphering what a sentence emotes and classifying them as either positive, negative, or neutral. In recent times, India has seen a huge influx in the number of active social media users and this has led to a plethora of unstructured text data. Since the Indian population is generally fluent in both Hindi and English, they end up generating code-mixed Hinglish social media text i.e. the expressions of Hindi language, written in the Roman script alongside other English words. The ability to adequately comprehend the notions in these texts is truly necessary. Our team, rns2020 participated in Task 9 at SemEval2020 intending to design a system to carry out the sentiment analysis of code-mixed social media text. This work proposes a system named NITS-Hinglish-SentiMix to viably complete the sentiment analysis of such code-mixed Hinglish text. The proposed framework has recorded an F-Score of 0.617 on the test data.
HCMS at SemEval-2020 Task 9: A Neural Approach to Sentiment Analysis for Code-Mixed Texts
Jul 23, 2020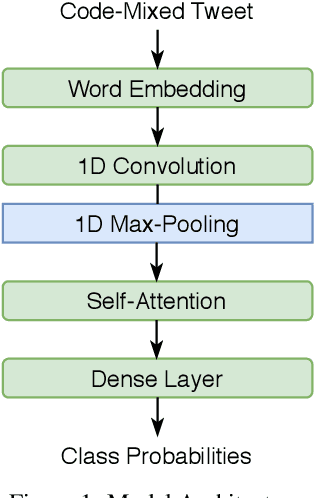
Problems involving code-mixed language are often plagued by a lack of resources and an absence of materials to perform sophisticated transfer learning with. In this paper we describe our submission to the Sentimix Hindi-English task involving sentiment classification of code-mixed texts, and with an F1 score of 67.1%, we demonstrate that simple convolution and attention may well produce reasonable results.
Voice@SRIB at SemEval-2020 Task : Sentiment and Offensiveness detection in Social Media
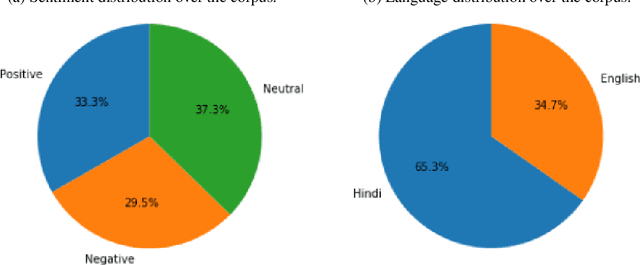
Jul 20, 2020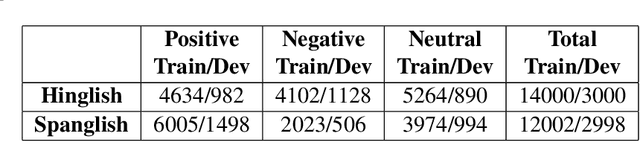
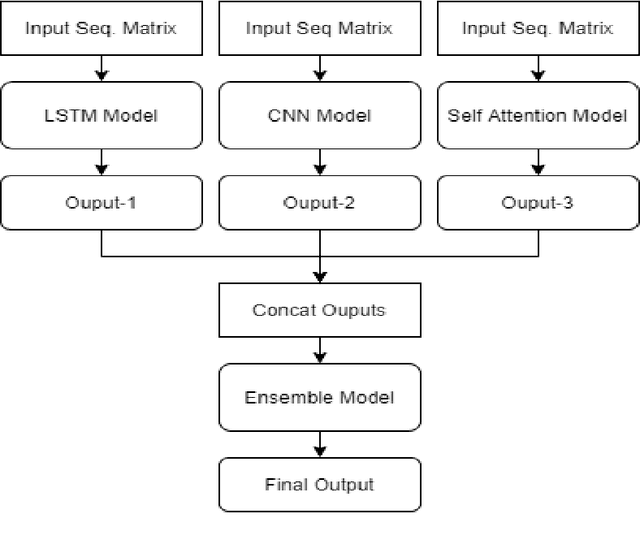
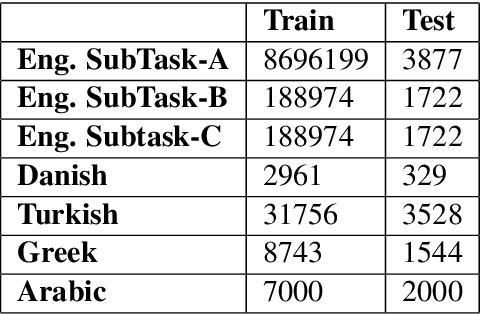
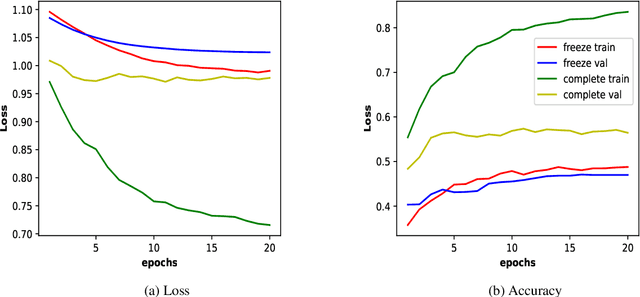
In social-media platforms such as Twitter, Facebook, and Reddit, people prefer to use code-mixed language such as Spanish-English, Hindi-English to express their opinions. In this paper, we describe different models we used, using the external dataset to train embeddings, ensembling methods for Sentimix, and OffensEval tasks. The use of pre-trained embeddings usually helps in multiple tasks such as sentence classification, and machine translation. In this experiment, we haveused our trained code-mixed embeddings and twitter pre-trained embeddings to SemEval tasks. We evaluate our models on macro F1-score, precision, accuracy, and recall on the datasets. We intend to show that hyper-parameter tuning and data pre-processing steps help a lot in improving the scores. In our experiments, we are able to achieve 0.886 F1-Macro on OffenEval Greek language subtask post-evaluation, whereas the highest is 0.852 during the Evaluation Period. We stood third in Spanglish competition with our best F1-score of 0.756. Codalab username is asking28.