 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResume Ner
Papers and Code
LLM-DER:A Named Entity Recognition Method Based on Large Language Models for Chinese Coal Chemical Domain
Sep 16, 2024Domain-specific Named Entity Recognition (NER), whose goal is to recognize domain-specific entities and their categories, provides an important support for constructing domain knowledge graphs. Currently, deep learning-based methods are widely used and effective in NER tasks, but due to the reliance on large-scale labeled data. As a result, the scarcity of labeled data in a specific domain will limit its application.Therefore, many researches started to introduce few-shot methods and achieved some results. However, the entity structures in specific domains are often complex, and the current few-shot methods are difficult to adapt to NER tasks with complex features.Taking the Chinese coal chemical industry domain as an example,there exists a complex structure of multiple entities sharing a single entity, as well as multiple relationships for the same pair of entities, which affects the NER task under the sample less condition.In this paper, we propose a Large Language Models (LLMs)-based entity recognition framework LLM-DER for the domain-specific entity recognition problem in Chinese, which enriches the entity information by generating a list of relationships containing entity types through LLMs, and designing a plausibility and consistency evaluation method to remove misrecognized entities, which can effectively solve the complex structural entity recognition problem in a specific domain.The experimental results of this paper on the Resume dataset and the self-constructed coal chemical dataset Coal show that LLM-DER performs outstandingly in domain-specific entity recognition, not only outperforming the existing GPT-3.5-turbo baseline, but also exceeding the fully-supervised baseline, verifying its effectiveness in entity recognition.
Resume Evaluation through Latent Dirichlet Allocation and Natural Language Processing for Effective Candidate Selection
Jul 28, 2023In this paper, we propose a method for resume rating using Latent Dirichlet Allocation (LDA) and entity detection with SpaCy. The proposed method first extracts relevant entities such as education, experience, and skills from the resume using SpaCy's Named Entity Recognition (NER). The LDA model then uses these entities to rate the resume by assigning topic probabilities to each entity. Furthermore, we conduct a detailed analysis of the entity detection using SpaCy's NER and report its evaluation metrics. Using LDA, our proposed system breaks down resumes into latent topics and extracts meaningful semantic representations. With a vision to define our resume score to be more content-driven rather than a structure and keyword match driven, our model has achieved 77% accuracy with respect to only skills in consideration and an overall 82% accuracy with all attributes in consideration. (like college name, work experience, degree and skills)
Named entity recognition in resumes
Jun 22, 2023Named entity recognition (NER) is used to extract information from various documents and texts such as names and dates. It is important to extract education and work experience information from resumes in order to filter them. Considering the fact that all information in a resume has to be entered to the companys system manually, automatizing this process will save time of the companies. In this study, a deep learning-based semi-automatic named entity recognition system has been implemented with a focus on resumes in the field of IT. Firstly, resumes of employees from five different IT related fields has been annotated. Six transformer based pre-trained models have been adapted to named entity recognition problem using the annotated data. These models have been selected among popular models in the natural language processing field. The obtained system can recognize eight different entity types which are city, date, degree, diploma major, job title, language, country and skill. Models used in the experiments are compared using micro, macro and weighted F1 scores and the performance of the methods was evaluated. Taking these scores into account for test set the best micro and weighted F1 score is obtained by RoBERTa and the best macro F1 score is obtained by Electra model.
A practical method for occupational skills detection in Vietnamese job listings
Oct 26, 2022


Vietnamese labor market has been under an imbalanced development. The number of university graduates is growing, but so is the unemployment rate. This situation is often caused by the lack of accurate and timely labor market information, which leads to skill miss-matches between worker supply and the actual market demands. To build a data monitoring and analytic platform for the labor market, one of the main challenges is to be able to automatically detect occupational skills from labor-related data, such as resumes and job listings. Traditional approaches rely on existing taxonomy and/or large annotated data to build Named Entity Recognition (NER) models. They are expensive and require huge manual efforts. In this paper, we propose a practical methodology for skill detection in Vietnamese job listings. Rather than viewing the task as a NER task, we consider the task as a ranking problem. We propose a pipeline in which phrases are first extracted and ranked in semantic similarity with the phrases' contexts. Then we employ a final classification to detect skill phrases. We collected three datasets and conducted extensive experiments. The results demonstrated that our methodology achieved better performance than a NER model in scarce datasets.
CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition
Apr 30, 2019
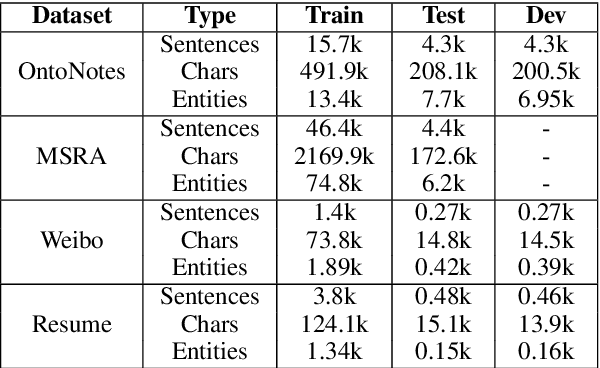
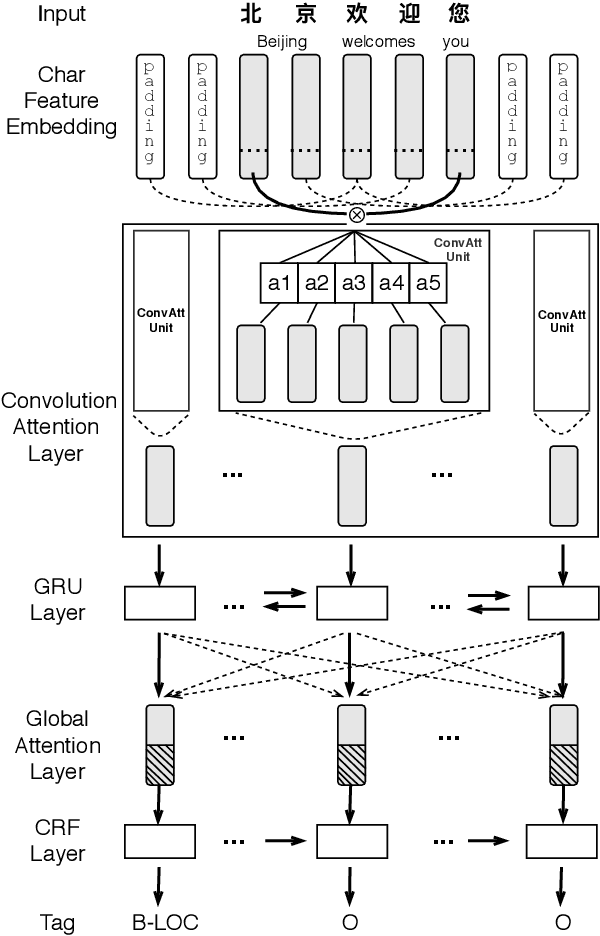
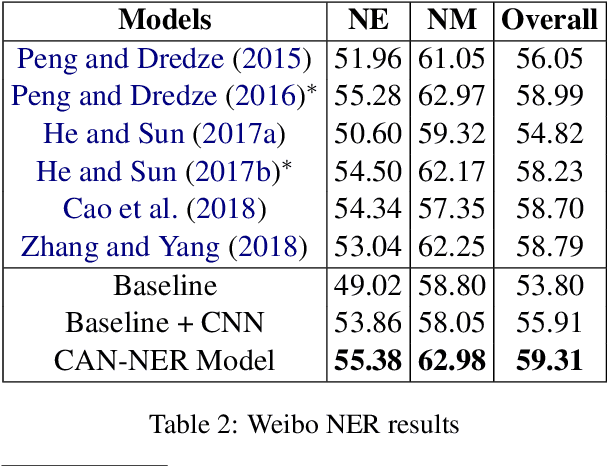
Named entity recognition (NER) in Chinese is essential but difficult because of the lack of natural delimiters. Therefore, Chinese Word Segmentation (CWS) is usually considered as the first step for Chinese NER. However, models based on word-level embeddings and lexicon features often suffer from segmentation errors and out-of-vocabulary (OOV) words. In this paper, we investigate a Convolutional Attention Network called CAN for Chinese NER, which consists of a character-based convolutional neural network (CNN) with local-attention layer and a gated recurrent unit (GRU) with global self-attention layer to capture the information from adjacent characters and sentence contexts. Also, compared to other models, not depending on any external resources like lexicons and employing small size of char embeddings make our model more practical. Extensive experimental results show that our approach outperforms state-of-the-art methods without word embedding and external lexicon resources on different domain datasets including Weibo, MSRA and Chinese Resume NER dataset.
Query-Based Named Entity Recognition
Aug 24, 2019
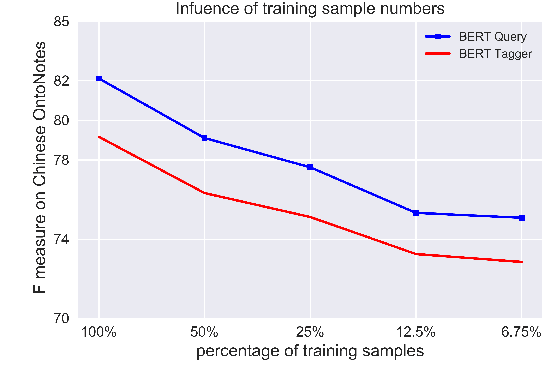
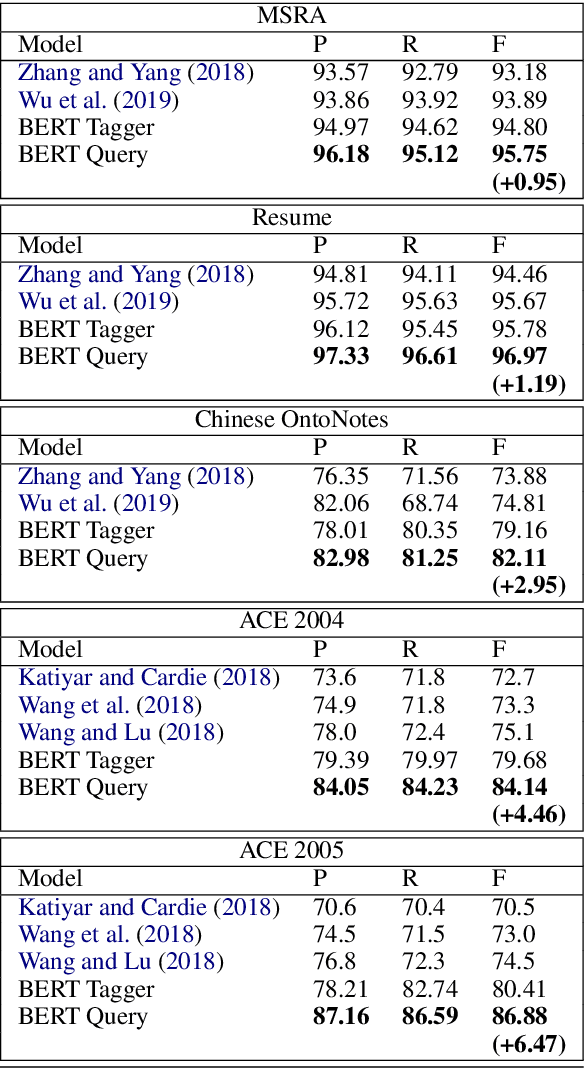
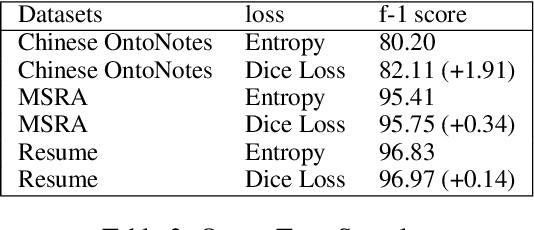
In this paper, we propose a new strategy for the task of named entity recognition (NER). We cast the task as a query-based machine reading comprehension task: e.g., the task of extracting entities with PER is formalized as answering the question of "which person is mentioned in the text ?". Such a strategy comes with the advantage that it solves the long-standing issue of handling overlapping or nested entities (the same token that participates in more than one entity categories) with sequence-labeling techniques for NER. Additionally, since the query encodes informative prior knowledge, this strategy facilitates the process of entity extraction, leading to better performances. We experiment the proposed model on five widely used NER datasets on English and Chinese, including MSRA, Resume, OntoNotes, ACE04 and ACE05. The proposed model sets new SOTA results on all of these datasets.