 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMs Asl
Papers and Code
Combining Metric Learning and Attention Heads For Accurate and Efficient Multilabel Image Classification
Sep 14, 2022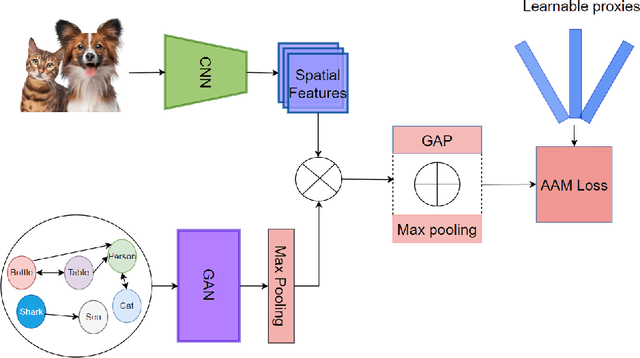
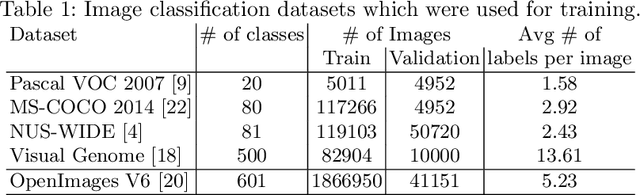
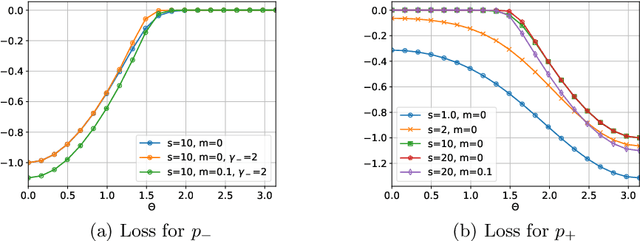
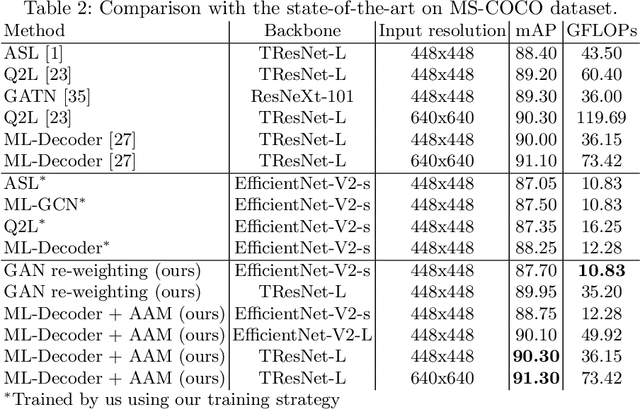
Multi-label image classification allows predicting a set of labels from a given image. Unlike multiclass classification, where only one label per image is assigned, such setup is applicable for a broader range of applications. In this work we revisit two popular approaches to multilabel classification: transformer-based heads and labels relations information graph processing branches. Although transformer-based heads are considered to achieve better results than graph-based branches, we argue that with the proper training strategy graph-based methods can demonstrate just a small accuracy drop, while spending less computational resources on inference. In our training strategy, instead of Asymmetric Loss (ASL), which is the de-facto standard for multilabel classification, we introduce its modification acting in the angle space. It implicitly learns a proxy feature vector on the unit hypersphere for each class, providing a better discrimination ability, than binary cross entropy loss does on unnormalized features. With the proposed loss and training strategy, we obtain SOTA results among single modality methods on widespread multilabel classification benchmarks such as MS-COCO, PASCAL-VOC, NUS-Wide and Visual Genome 500. Source code of our method is available as a part of the OpenVINO Training Extensions https://github.com/openvinotoolkit/deep-object-reid/tree/multilabel
Pose-Guided Sign Language Video GAN with Dynamic Lambda
May 06, 2021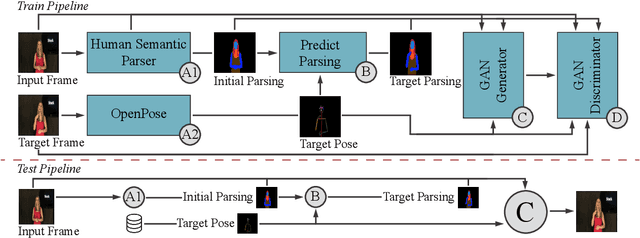
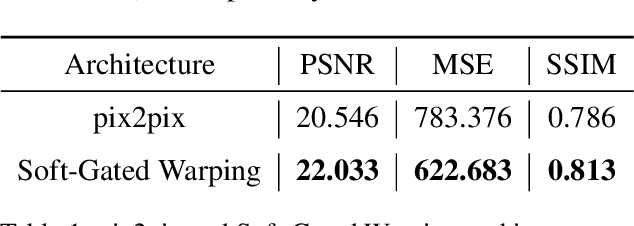
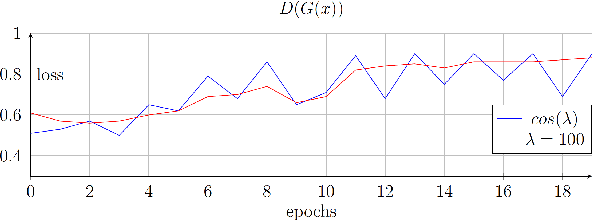
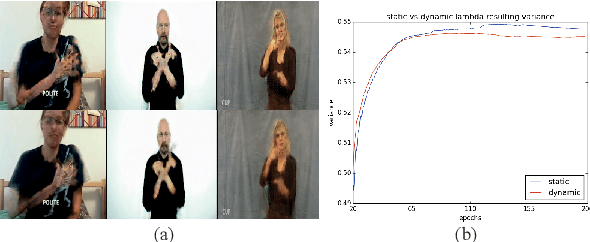
We propose a novel approach for the synthesis of sign language videos using GANs. We extend the previous work of Stoll et al. by using the human semantic parser of the Soft-Gated Warping-GAN from to produce photorealistic videos guided by region-level spatial layouts. Synthesizing target poses improves performance on independent and contrasting signers. Therefore, we have evaluated our system with the highly heterogeneous MS-ASL dataset with over 200 signers resulting in a SSIM of 0.893. Furthermore, we introduce a periodic weighting approach to the generator that reactivates the training and leads to quantitatively better results.
Application of Transfer Learning to Sign Language Recognition using an Inflated 3D Deep Convolutional Neural Network
Feb 25, 2021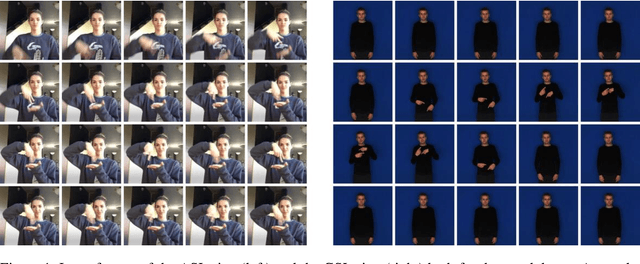


Sign language is the primary language for people with a hearing loss. Sign language recognition (SLR) is the automatic recognition of sign language, which represents a challenging problem for computers, though some progress has been made recently using deep learning. Huge amounts of data are generally required to train deep learning models. However, corresponding datasets are missing for the majority of sign languages. Transfer learning is a technique to utilize a related task with an abundance of data available to help solve a target task lacking sufficient data. Transfer learning has been applied highly successfully in computer vision and natural language processing. However, much less research has been conducted in the field of SLR. This paper investigates how effectively transfer learning can be applied to isolated SLR using an inflated 3D convolutional neural network as the deep learning architecture. Transfer learning is implemented by pre-training a network on the American Sign Language dataset MS-ASL and subsequently fine-tuning it separately on three different sizes of the German Sign Language dataset SIGNUM. The results of the experiments give clear empirical evidence that transfer learning can be effectively applied to isolated SLR. The accuracy performances of the networks applying transfer learning increased substantially by up to 21% as compared to the baseline models that were not pre-trained on the MS-ASL dataset.
ASL Recognition with Metric-Learning based Lightweight Network
Apr 10, 2020


In the past decades the set of human tasks that are solved by machines was extended dramatically. From simple image classification problems researchers now move towards solving more sophisticated and vital problems, like, autonomous driving and language translation. The case of language translation includes a challenging area of sign language translation that incorporates both image and language processing. We make a step in that direction by proposing a lightweight network for ASL gesture recognition with a performance sufficient for practical applications. The proposed solution demonstrates impressive robustness on MS-ASL dataset and in live mode for continuous sign gesture recognition scenario. Additionally, we describe how to combine action recognition model training with metric-learning to train the network on the database of limited size. The training code is available as part of Intel OpenVINO Training Extensions.
Asymmetric Loss For Multi-Label Classification
Sep 29, 2020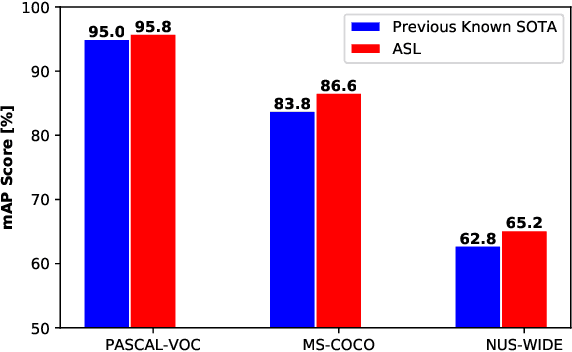
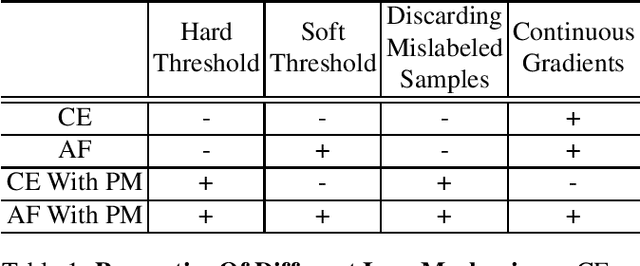
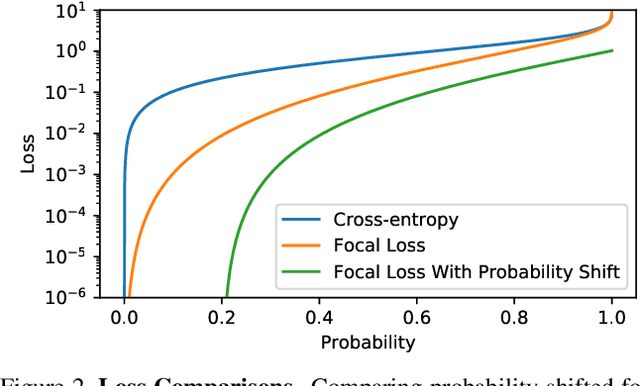
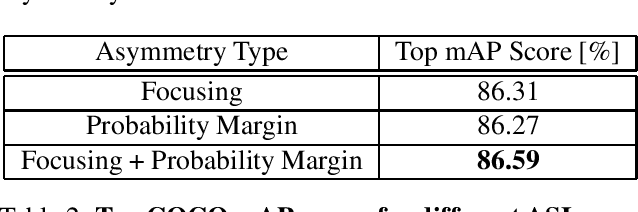
Pictures of everyday life are inherently multi-label in nature. Hence, multi-label classification is commonly used to analyze their content. In typical multi-label datasets, each picture contains only a few positive labels, and many negative ones. This positive-negative imbalance can result in under-emphasizing gradients from positive labels during training, leading to poor accuracy. In this paper, we introduce a novel asymmetric loss ("ASL"), that operates differently on positive and negative samples. The loss dynamically down-weights the importance of easy negative samples, causing the optimization process to focus more on the positive samples, and also enables to discard mislabeled negative samples. We demonstrate how ASL leads to a more "balanced" network, with increased average probabilities for positive samples, and show how this balanced network is translated to better mAP scores, compared to commonly used losses. Furthermore, we offer a method that can dynamically adjust the level of asymmetry throughout the training. With ASL, we reach new state-of-the-art results on three common multi-label datasets, including achieving 86.6% on MS-COCO. We also demonstrate ASL applicability for other tasks such as fine-grain single-label classification and object detection. ASL is effective, easy to implement, and does not increase the training time or complexity. Implementation is available at: https://github.com/Alibaba-MIIL/ASL.
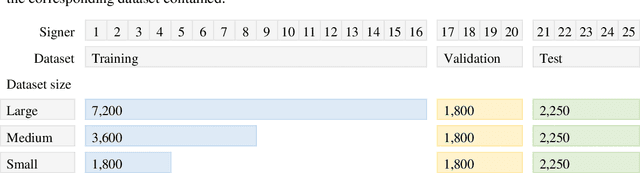
MS-ASL: A Large-Scale Data Set and Benchmark for Understanding American Sign Language
Dec 03, 2018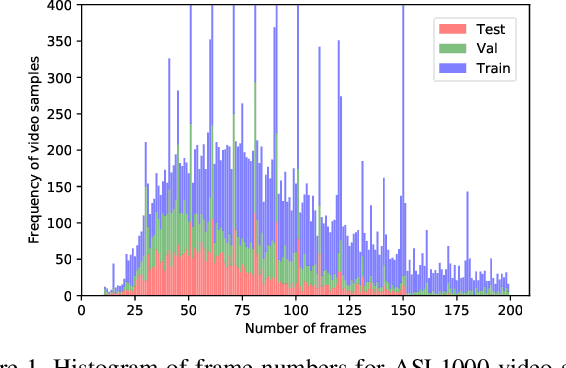

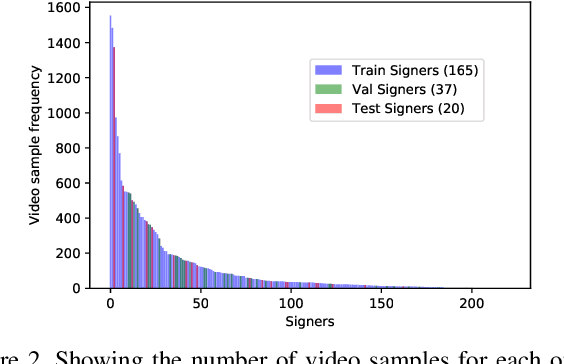
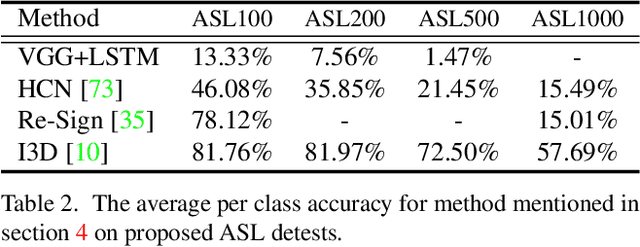
Computer Vision has been improved significantly in the past few decades. It has enabled machine to do many human tasks. However, the real challenge is in enabling machine to carry out tasks that an average human does not have the skills for. One such challenge that we have tackled in this paper is providing accessibility for deaf individual by providing means of communication with others with the aid of computer vision. Unlike other frequent works focusing on multiple camera, depth camera, electrical glove or visual gloves, we focused on the sole use of RGB which allows everybody to communicate with a deaf individual through their personal devices. This is not a new approach but the lack of realistic large-scale data set prevented recent computer vision trends on video classification in this filed. In this paper, we propose the first large scale ASL data set that covers over 200 signers, signer independent sets, challenging and unconstrained recording conditions and a large class count of 1000 signs. We evaluate baselines from action recognition techniques on the data set. We propose I3D, known from video classifications, as a powerful and suitable architecture for sign language recognition. We also propose new pre-trained model more appropriate for sign language recognition. Finally, We estimate the effect of number of classes and number of training samples on the recognition accuracy.