 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIGAR: Lightweight General-purpose Action Recognition
Aug 30, 2021


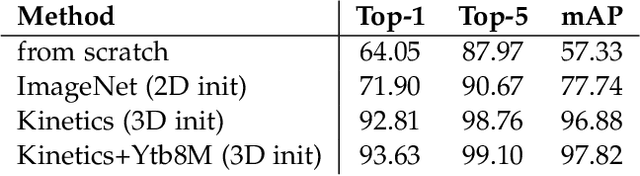
Growing amount of different practical tasks in a video understanding problem has addressed the great challenge aiming to design an universal solution, which should be available for broad masses and suitable for the demanding edge-oriented inference. In this paper we are focused on designing a network architecture and a training pipeline to tackle the mentioned challenges. Our architecture takes the best from the previous ones and brings the ability to be successful not only in appearance-based action recognition tasks but in motion-based problems too. Furthermore, the induced label noise problem is formulated and Adaptive Clip Selection (ACS) framework is proposed to deal with it. Together it makes the LIGAR framework the general-purpose action recognition solution. We also have reported the extensive analysis on the general and gesture datasets to show the excellent trade-off between the performance and the accuracy in comparison to the state-of-the-art solutions. Training code is available at: https://github.com/openvinotoolkit/training_extensions. For the efficient edge-oriented inference all trained models can be exported into the OpenVINO format.
ASL Recognition with Metric-Learning based Lightweight Network
Apr 10, 2020


In the past decades the set of human tasks that are solved by machines was extended dramatically. From simple image classification problems researchers now move towards solving more sophisticated and vital problems, like, autonomous driving and language translation. The case of language translation includes a challenging area of sign language translation that incorporates both image and language processing. We make a step in that direction by proposing a lightweight network for ASL gesture recognition with a performance sufficient for practical applications. The proposed solution demonstrates impressive robustness on MS-ASL dataset and in live mode for continuous sign gesture recognition scenario. Additionally, we describe how to combine action recognition model training with metric-learning to train the network on the database of limited size. The training code is available as part of Intel OpenVINO Training Extensions.
Fast and Accurate Person Re-Identification with RMNet
Dec 06, 2018


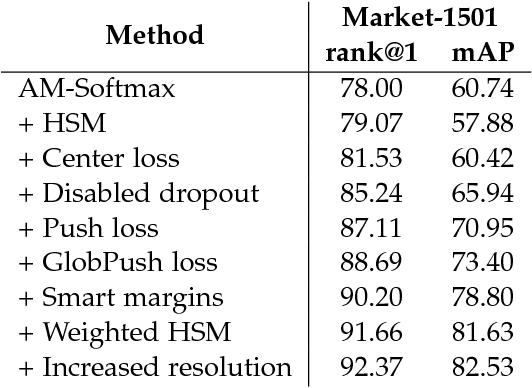
In this paper we introduce a new neural network architecture designed to use in embedded vision applications. It merges the best working practices of network architectures like MobileNets and ResNets to our named RMNet architecture. We also focus on key moments of building mobile architectures to carry out in the limited computation budget. Additionally, to demonstrate the effectiveness of our architecture we evaluate the RMNet backbone on Person Re-identification task. The proposed approach is in top 3 of state of the art solutions on Market-1501 challenge, however our method significantly outperforms them by the inference speed.
High Diversity Attribute Guided Face Generation with GANs
Jun 28, 2018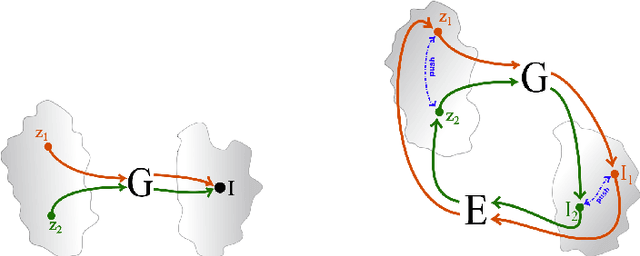

In this work we focused on GAN-based solution for the attribute guided face synthesis. Previous works exploited GANs for generation of photo-realistic face images and did not pay attention to the question of diversity of the resulting images. The proposed solution in its turn introducing novel latent space of unit complex numbers is able to provide the diversity on the "birthday paradox" score 3 times higher than the size of the training dataset. It is important to emphasize that our result is shown on relatively small dataset (20k samples vs 200k) while preserving photo-realistic properties of generated faces on significantly higher resolution (128x128 in comparison to 32x32 of previous works).