 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Influence of Faulty Labels in Data Sets on Human Pose Estimation
Sep 09, 2024



In this study we provide empirical evidence demonstrating that the quality of training data impacts model performance in Human Pose Estimation (HPE). Inaccurate labels in widely used data sets, ranging from minor errors to severe mislabeling, can negatively influence learning and distort performance metrics. We perform an in-depth analysis of popular HPE data sets to show the extent and nature of label inaccuracies. Our findings suggest that accounting for the impact of faulty labels will facilitate the development of more robust and accurate HPE models for a variety of real-world applications. We show improved performance with cleansed data.
Generating Synthetic Satellite Imagery for Rare Objects: An Empirical Comparison of Models and Metrics
Sep 02, 2024



Generative deep learning architectures can produce realistic, high-resolution fake imagery -- with potentially drastic societal implications. A key question in this context is: How easy is it to generate realistic imagery, in particular for niche domains. The iterative process required to achieve specific image content is difficult to automate and control. Especially for rare classes, it remains difficult to assess fidelity, meaning whether generative approaches produce realistic imagery and alignment, meaning how (well) the generation can be guided by human input. In this work, we present a large-scale empirical evaluation of generative architectures which we fine-tuned to generate synthetic satellite imagery. We focus on nuclear power plants as an example of a rare object category - as there are only around 400 facilities worldwide, this restriction is exemplary for many other scenarios in which training and test data is limited by the restricted number of occurrences of real-world examples. We generate synthetic imagery by conditioning on two kinds of modalities, textual input and image input obtained from a game engine that allows for detailed specification of the building layout. The generated images are assessed by commonly used metrics for automatic evaluation and then compared with human judgement from our conducted user studies to assess their trustworthiness. Our results demonstrate that even for rare objects, generation of authentic synthetic satellite imagery with textual or detailed building layouts is feasible. In line with previous work, we find that automated metrics are often not aligned with human perception -- in fact, we find strong negative correlations between commonly used image quality metrics and human ratings.
Using Game Engines and Machine Learning to Create Synthetic Satellite Imagery for a Tabletop Verification Exercise
Apr 17, 2024



Satellite imagery is regarded as a great opportunity for citizen-based monitoring of activities of interest. Relevant imagery may however not be available at sufficiently high resolution, quality, or cadence -- let alone be uniformly accessible to open-source analysts. This limits an assessment of the true long-term potential of citizen-based monitoring of nuclear activities using publicly available satellite imagery. In this article, we demonstrate how modern game engines combined with advanced machine-learning techniques can be used to generate synthetic imagery of sites of interest with the ability to choose relevant parameters upon request; these include time of day, cloud cover, season, or level of activity onsite. At the same time, resolution and off-nadir angle can be adjusted to simulate different characteristics of the satellite. While there are several possible use-cases for synthetic imagery, here we focus on its usefulness to support tabletop exercises in which simple monitoring scenarios can be examined to better understand verification capabilities enabled by new satellite constellations and very short revisit times.
CAD Models to Real-World Images: A Practical Approach to Unsupervised Domain Adaptation in Industrial Object Classification
Oct 07, 2023In this paper, we systematically analyze unsupervised domain adaptation pipelines for object classification in a challenging industrial setting. In contrast to standard natural object benchmarks existing in the field, our results highlight the most important design choices when only category-labeled CAD models are available but classification needs to be done with real-world images. Our domain adaptation pipeline achieves SoTA performance on the VisDA benchmark, but more importantly, drastically improves recognition performance on our new open industrial dataset comprised of 102 mechanical parts. We conclude with a set of guidelines that are relevant for practitioners needing to apply state-of-the-art unsupervised domain adaptation in practice. Our code is available at https://github.com/dritter-bht/synthnet-transfer-learning.
Pose-Guided Sign Language Video GAN with Dynamic Lambda
May 06, 2021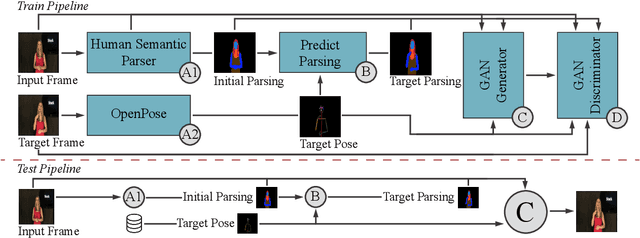
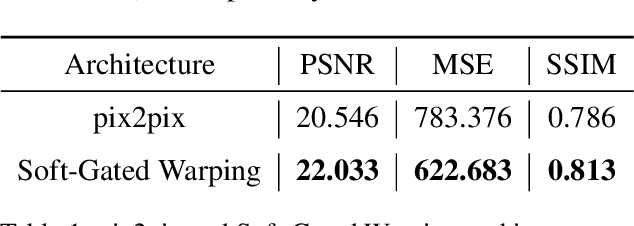
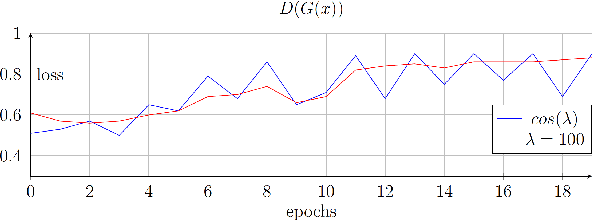
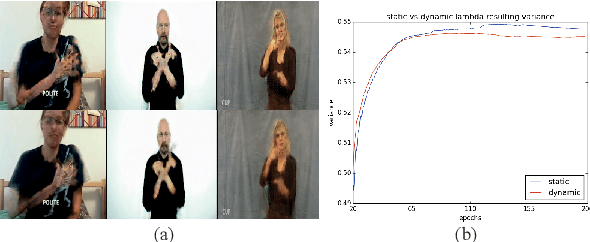
We propose a novel approach for the synthesis of sign language videos using GANs. We extend the previous work of Stoll et al. by using the human semantic parser of the Soft-Gated Warping-GAN from to produce photorealistic videos guided by region-level spatial layouts. Synthesizing target poses improves performance on independent and contrasting signers. Therefore, we have evaluated our system with the highly heterogeneous MS-ASL dataset with over 200 signers resulting in a SSIM of 0.893. Furthermore, we introduce a periodic weighting approach to the generator that reactivates the training and leads to quantitatively better results.
Anonymization of labeled TOF-MRA images for brain vessel segmentation using generative adversarial networks
Sep 16, 2020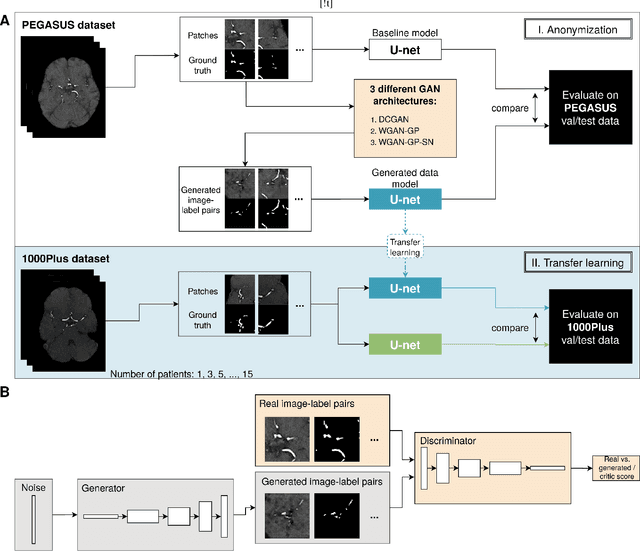
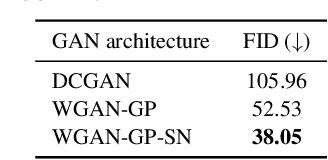

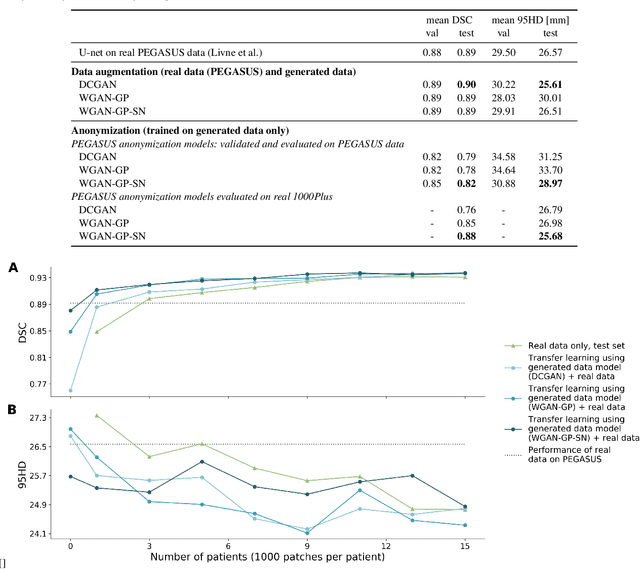
Anonymization and data sharing are crucial for privacy protection and acquisition of large datasets for medical image analysis. This is a big challenge, especially for neuroimaging. Here, the brain's unique structure allows for re-identification and thus requires non-conventional anonymization. Generative adversarial networks (GANs) have the potential to provide anonymous images while preserving predictive properties. Analyzing brain vessel segmentation as a use case, we trained 3 GANs on time-of-flight (TOF) magnetic resonance angiography (MRA) patches for image-label generation: 1) Deep convolutional GAN, 2) Wasserstein-GAN with gradient penalty (WGAN-GP) and 3) WGAN-GP with spectral normalization (WGAN-GP-SN). The generated image-labels from each GAN were used to train a U-net for segmentation and tested on real data. Moreover, we applied our synthetic patches using transfer learning on a second dataset. For an increasing number of up to 15 patients we evaluated the model performance on real data with and without pre-training. The performance for all models was assessed by the Dice Similarity Coefficient (DSC) and the 95th percentile of the Hausdorff Distance (95HD). Comparing the 3 GANs, the U-net trained on synthetic data generated by the WGAN-GP-SN showed the highest performance to predict vessels (DSC/95HD 0.82/28.97) benchmarked by the U-net trained on real data (0.89/26.61). The transfer learning approach showed superior performance for the same GAN compared to no pre-training, especially for one patient only (0.91/25.68 vs. 0.85/27.36). In this work, synthetic image-label pairs retained generalizable information and showed good performance for vessel segmentation. Besides, we showed that synthetic patches can be used in a transfer learning approach with independent data. This paves the way to overcome the challenges of scarce data and anonymization in medical imaging.