 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimii
Papers and Code
MIMII-Agent: Leveraging LLMs with Function Calling for Relative Evaluation of Anomalous Sound Detection
Jul 28, 2025This paper proposes a method for generating machine-type-specific anomalies to evaluate the relative performance of unsupervised anomalous sound detection (UASD) systems across different machine types, even in the absence of real anomaly sound data. Conventional keyword-based data augmentation methods often produce unrealistic sounds due to their reliance on manually defined labels, limiting scalability as machine types and anomaly patterns diversify. Advanced audio generative models, such as MIMII-Gen, show promise but typically depend on anomalous training data, making them less effective when diverse anomalous examples are unavailable. To address these limitations, we propose a novel synthesis approach leveraging large language models (LLMs) to interpret textual descriptions of faults and automatically select audio transformation functions, converting normal machine sounds into diverse and plausible anomalous sounds. We validate this approach by evaluating a UASD system trained only on normal sounds from five machine types, using both real and synthetic anomaly data. Experimental results reveal consistent trends in relative detection difficulty across machine types between synthetic and real anomalies. This finding supports our hypothesis and highlights the effectiveness of the proposed LLM-based synthesis approach for relative evaluation of UASD systems.
Audio-based Anomaly Detection in Industrial Machines Using Deep One-Class Support Vector Data Description
Dec 14, 2024The frequent breakdowns and malfunctions of industrial equipment have driven increasing interest in utilizing cost-effective and easy-to-deploy sensors, such as microphones, for effective condition monitoring of machinery. Microphones offer a low-cost alternative to widely used condition monitoring sensors with their high bandwidth and capability to detect subtle anomalies that other sensors might have less sensitivity. In this study, we investigate malfunctioning industrial machines to evaluate and compare anomaly detection performance across different machine types and fault conditions. Log-Mel spectrograms of machinery sound are used as input, and the performance is evaluated using the area under the curve (AUC) score for two different methods: baseline dense autoencoder (AE) and one-class deep Support Vector Data Description (deep SVDD) with different subspace dimensions. Our results over the MIMII sound dataset demonstrate that the deep SVDD method with a subspace dimension of 2 provides superior anomaly detection performance, achieving average AUC scores of 0.84, 0.80, and 0.69 for 6 dB, 0 dB, and -6 dB signal-to-noise ratios (SNRs), respectively, compared to 0.82, 0.72, and 0.64 for the baseline model. Moreover, deep SVDD requires 7.4 times fewer trainable parameters than the baseline dense AE, emphasizing its advantage in both effectiveness and computational efficiency.
Timbre Difference Capturing in Anomalous Sound Detection
Oct 29, 2024



This paper proposes a framework of explaining anomalous machine sounds in the context of anomalous sound detection~(ASD). While ASD has been extensively explored, identifying how anomalous sounds differ from normal sounds is also beneficial for machine condition monitoring. However, existing sound difference captioning methods require anomalous sounds for training, which is impractical in typical machine condition monitoring settings where such sounds are unavailable. To solve this issue, we propose a new strategy for explaining anomalous differences that does not require anomalous sounds for training. Specifically, we introduce a framework that explains differences in predefined timbre attributes instead of using free-form text captions. Objective metrics of timbre attributes can be computed using timbral models developed through psycho-acoustical research, enabling the estimation of how and what timbre attributes have changed from normal sounds without training machine learning models. Additionally, to accurately determine timbre differences regardless of variations in normal training data, we developed a method that jointly conducts anomalous sound detection and timbre difference estimation based on a k-nearest neighbors method in an audio embedding space. Evaluation using the MIMII DG dataset demonstrated the effectiveness of the proposed method.
MIMII-Gen: Generative Modeling Approach for Simulated Evaluation of Anomalous Sound Detection System
Sep 27, 2024



Insufficient recordings and the scarcity of anomalies present significant challenges in developing and validating robust anomaly detection systems for machine sounds. To address these limitations, we propose a novel approach for generating diverse anomalies in machine sound using a latent diffusion-based model that integrates an encoder-decoder framework. Our method utilizes the Flan-T5 model to encode captions derived from audio file metadata, enabling conditional generation through a carefully designed U-Net architecture. This approach aids our model in generating audio signals within the EnCodec latent space, ensuring high contextual relevance and quality. We objectively evaluated the quality of our generated sounds using the Fr\'echet Audio Distance (FAD) score and other metrics, demonstrating that our approach surpasses existing models in generating reliable machine audio that closely resembles actual abnormal conditions. The evaluation of the anomaly detection system using our generated data revealed a strong correlation, with the area under the curve (AUC) score differing by 4.8\% from the original, validating the effectiveness of our generated data. These results demonstrate the potential of our approach to enhance the evaluation and robustness of anomaly detection systems across varied and previously unseen conditions. Audio samples can be found at \url{https://hpworkhub.github.io/MIMII-Gen.github.io/}.
Self-supervised Complex Network for Machine Sound Anomaly Detection
Dec 21, 2023In this paper, we propose an anomaly detection algorithm for machine sounds with a deep complex network trained by self-supervision. Using the fact that phase continuity information is crucial for detecting abnormalities in time-series signals, our proposed algorithm utilizes the complex spectrum as an input and performs complex number arithmetic throughout the entire process. Since the usefulness of phase information can vary depending on the type of machine sound, we also apply an attention mechanism to control the weights of the complex and magnitude spectrum bottleneck features depending on the machine type. We train our network to perform a self-supervised task that classifies the machine identifier (id) of normal input sounds among multiple classes. At test time, an input signal is detected as anomalous if the trained model is unable to correctly classify the id. In other words, we determine the presence of an anomality when the output cross-entropy score of the multiclass identification task is lower than a pre-defined threshold. Experiments with the MIMII dataset show that the proposed algorithm has a much higher area under the curve (AUC) score than conventional magnitude spectrum-based algorithms.
Acoustic Signal Analysis with Deep Neural Network for Detecting Fault Diagnosis in Industrial Machines
Dec 02, 2023Detecting machine malfunctions at an early stage is crucial for reducing interruptions in operational processes within industrial settings. Recently, the deep learning approach has started to be preferred for the detection of failures in machines. Deep learning provides an effective solution in fault detection processes thanks to automatic feature extraction. In this study, a deep learning-based system was designed to analyze the sound signals produced by industrial machines. Acoustic sound signals were converted into Mel spectrograms. For the purpose of classifying spectrogram images, the DenseNet-169 model, a deep learning architecture recognized for its effectiveness in image classification tasks, was used. The model was trained using the transfer learning method on the MIMII dataset including sounds from four types of industrial machines. The results showed that the proposed method reached an accuracy rate varying between 97.17% and 99.87% at different Sound Noise Rate levels.
Outlier-aware Inlier Modeling and Multi-scale Scoring for Anomalous Sound Detection via Multitask Learning
Sep 14, 2023This paper proposes an approach for anomalous sound detection that incorporates outlier exposure and inlier modeling within a unified framework by multitask learning. While outlier exposure-based methods can extract features efficiently, it is not robust. Inlier modeling is good at generating robust features, but the features are not very effective. Recently, serial approaches are proposed to combine these two methods, but it still requires a separate training step for normal data modeling. To overcome these limitations, we use multitask learning to train a conformer-based encoder for outlier-aware inlier modeling. Moreover, our approach provides multi-scale scores for detecting anomalies. Experimental results on the MIMII and DCASE 2020 task 2 datasets show that our approach outperforms state-of-the-art single-model systems and achieves comparable results with top-ranked multi-system ensembles.
MIMII DG: Sound Dataset for Malfunctioning Industrial Machine Investigation and Inspection for Domain Generalization Task
May 27, 2022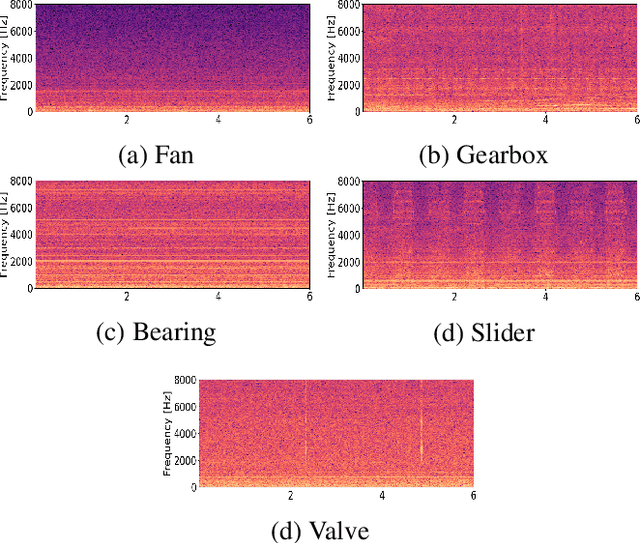

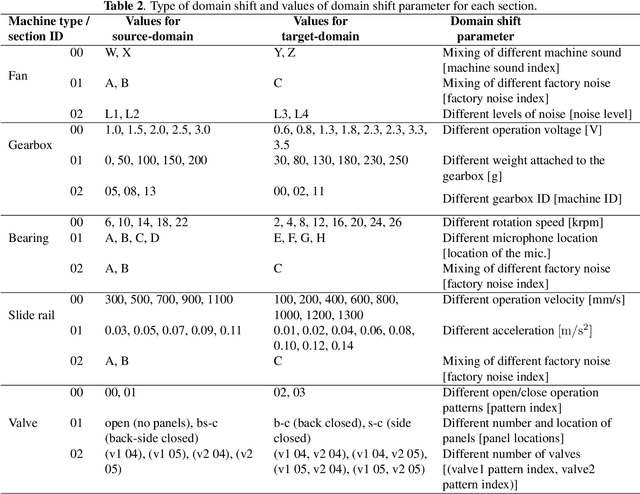
We present a machine sound dataset to benchmark domain generalization techniques for anomalous sound detection (ASD). To handle performance degradation caused by domain shifts that are difficult to detect or too frequent to adapt, domain generalization techniques are preferred. However, currently available datasets have difficulties in evaluating these techniques, such as limited number of values for parameters that cause domain shifts (domain shift parameters). In this paper, we present the first ASD dataset for the domain generalization techniques, called MIMII DG. The dataset consists of five machine types and three domain shift scenarios for each machine type. We prepared at least two values for the domain shift parameters in the source domain. Also, we introduced domain shifts that can be difficult to notice. Experimental results using two baseline systems indicate that the dataset reproduces the domain shift scenarios and is useful for benchmarking domain generalization techniques.
Health Monitoring of Industrial machines using Scene-Aware Threshold Selection
Nov 21, 2021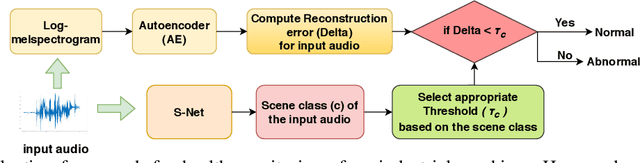
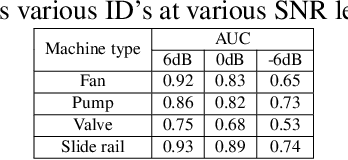
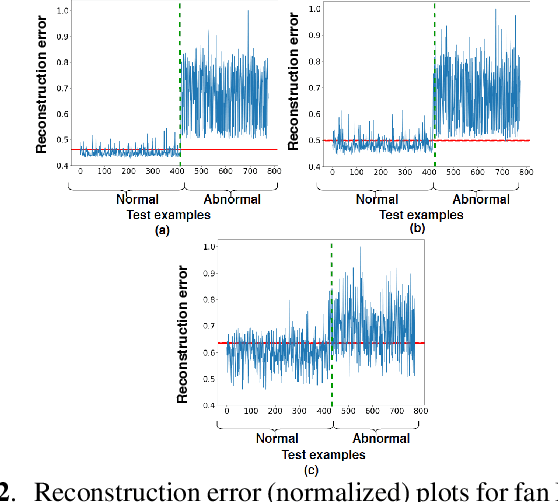
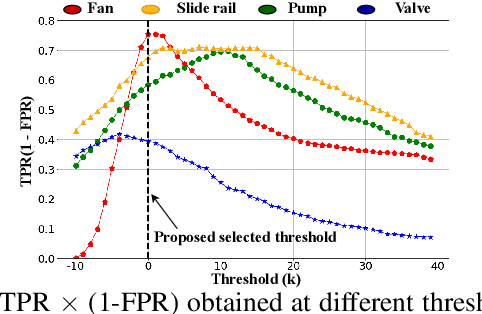
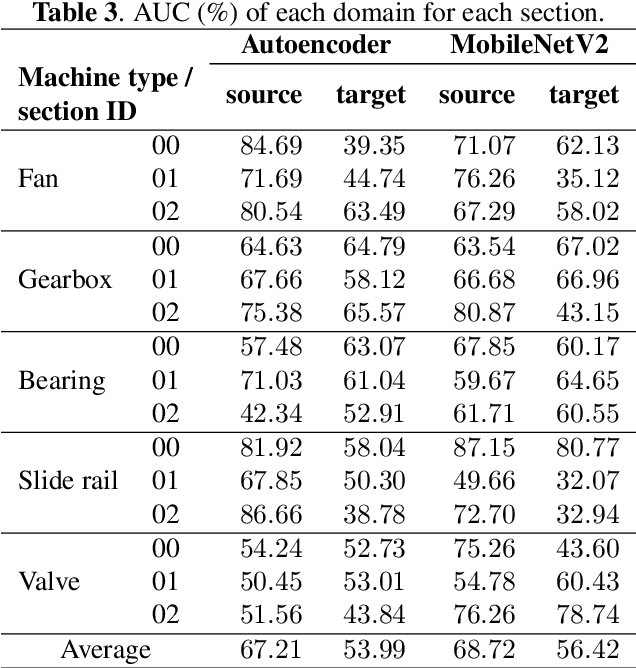
This paper presents an autoencoder based unsupervised approach to identify anomaly in an industrial machine using sounds produced by the machine. The proposed framework is trained using log-melspectrogram representations of the sound signal. In classification, our hypothesis is that the reconstruction error computed for an abnormal machine is larger than that of the a normal machine, since only normal machine sounds are being used to train the autoencoder. A threshold is chosen to discriminate between normal and abnormal machines. However, the threshold changes as surrounding conditions vary. To select an appropriate threshold irrespective of the surrounding, we propose a scene classification framework, which can classify the underlying surrounding. Hence, the threshold can be selected adaptively irrespective of the surrounding. The experiment evaluation is performed on MIMII dataset for industrial machines namely fan, pump, valve and slide rail. Our experiment analysis shows that utilizing adaptive threshold, the performance improves significantly as that obtained using the fixed threshold computed for a given surrounding only.
Canonical Polyadic Decomposition and Deep Learning for Machine Fault Detection
Jul 20, 2021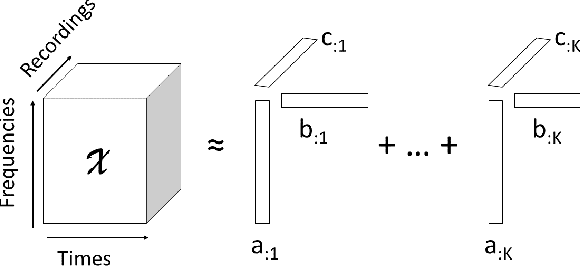
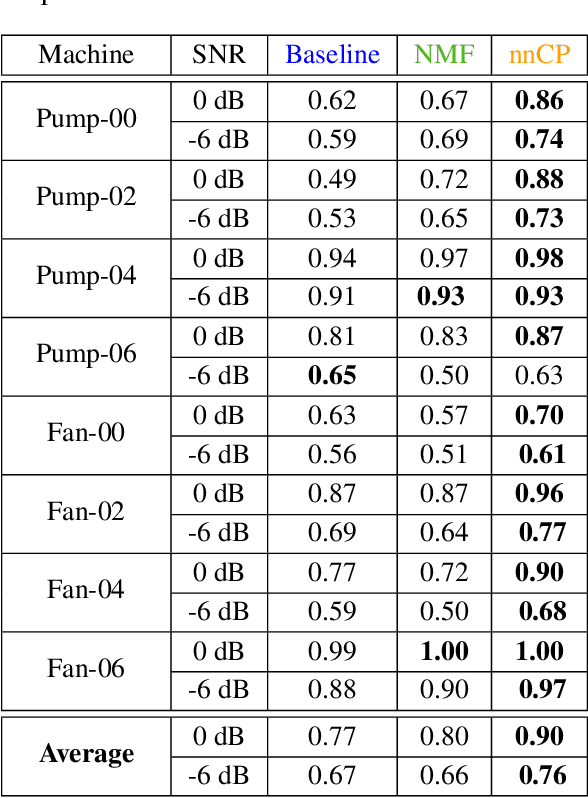
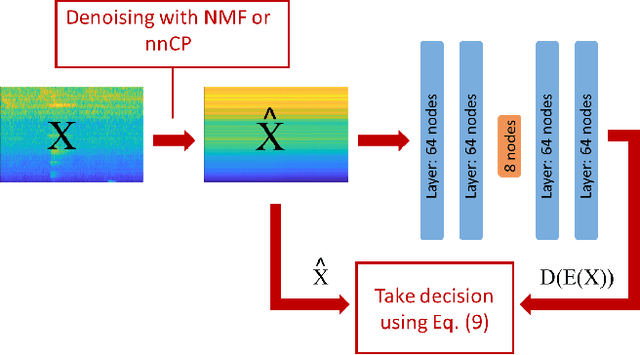
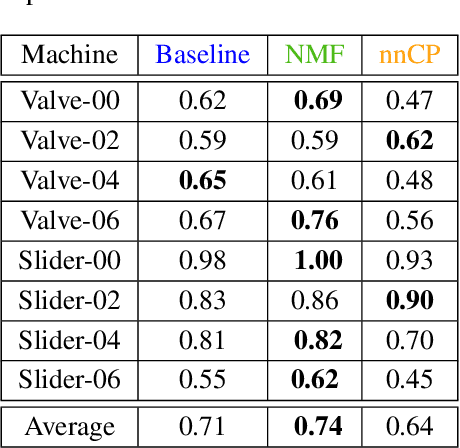
Acoustic monitoring for machine fault detection is a recent and expanding research path that has already provided promising results for industries. However, it is impossible to collect enough data to learn all types of faults from a machine. Thus, new algorithms, trained using data from healthy conditions only, were developed to perform unsupervised anomaly detection. A key issue in the development of these algorithms is the noise in the signals, as it impacts the anomaly detection performance. In this work, we propose a powerful data-driven and quasi non-parametric denoising strategy for spectral data based on a tensor decomposition: the Non-negative Canonical Polyadic (CP) decomposition. This method is particularly adapted for machine emitting stationary sound. We demonstrate in a case study, the Malfunctioning Industrial Machine Investigation and Inspection (MIMII) baseline, how the use of our denoising strategy leads to a sensible improvement of the unsupervised anomaly detection. Such approaches are capable to make sound-based monitoring of industrial processes more reliable.
* 9 pages, 5 figures, conference paper from PHM Society European Conference 2021 (Vol. 6, No. 1)