 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetagraspnet
Papers and Code
Robust Analysis of Multi-Task Learning on a Complex Vision System
Feb 05, 2024



Multi-task learning (MTL) has been widely studied in the past decade. In particular, dozens of optimization algorithms have been proposed for different settings. While each of them claimed improvement when applied to certain models on certain datasets, there is still lack of deep understanding on the performance in complex real-worlds scenarios. We identify the gaps between research and application and make the following 4 contributions. (1) We comprehensively evaluate a large set of existing MTL optimization algorithms on the MetaGraspNet dataset designed for robotic grasping task, which is complex and has high real-world application values, and conclude the best-performing methods. (2) We empirically compare the method performance when applied on feature-level gradients versus parameter-level gradients over a large set of MTL optimization algorithms, and conclude that this feature-level gradients surrogate is reasonable when there are method-specific theoretical guarantee but not generalizable to all methods. (3) We provide insights on the problem of task interference and show that the existing perspectives of gradient angles and relative gradient norms do not precisely reflect the challenges of MTL, as the rankings of the methods based on these two indicators do not align well with those based on the test-set performance. (4) We provide a novel view of the task interference problem from the perspective of the latent space induced by the feature extractor and provide training monitoring results based on feature disentanglement.
Fast GraspNeXt: A Fast Self-Attention Neural Network Architecture for Multi-task Learning in Computer Vision Tasks for Robotic Grasping on the Edge
Apr 21, 2023Multi-task learning has shown considerable promise for improving the performance of deep learning-driven vision systems for the purpose of robotic grasping. However, high architectural and computational complexity can result in poor suitability for deployment on embedded devices that are typically leveraged in robotic arms for real-world manufacturing and warehouse environments. As such, the design of highly efficient multi-task deep neural network architectures tailored for computer vision tasks for robotic grasping on the edge is highly desired for widespread adoption in manufacturing environments. Motivated by this, we propose Fast GraspNeXt, a fast self-attention neural network architecture tailored for embedded multi-task learning in computer vision tasks for robotic grasping. To build Fast GraspNeXt, we leverage a generative network architecture search strategy with a set of architectural constraints customized to achieve a strong balance between multi-task learning performance and embedded inference efficiency. Experimental results on the MetaGraspNet benchmark dataset show that the Fast GraspNeXt network design achieves the highest performance (average precision (AP), accuracy, and mean squared error (MSE)) across multiple computer vision tasks when compared to other efficient multi-task network architecture designs, while having only 17.8M parameters (about >5x smaller), 259 GFLOPs (as much as >5x lower) and as much as >3.15x faster on a NVIDIA Jetson TX2 embedded processor.
MetaGraspNet: A Large-Scale Benchmark Dataset for Scene-Aware Ambidextrous Bin Picking via Physics-based Metaverse Synthesis
Aug 08, 2022
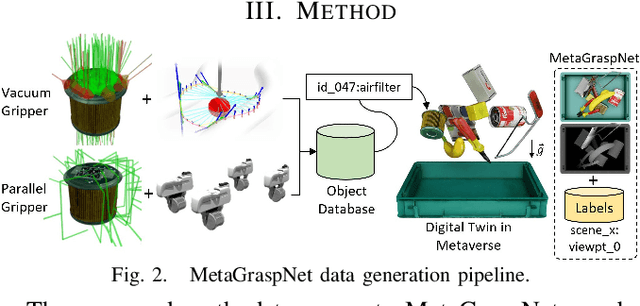
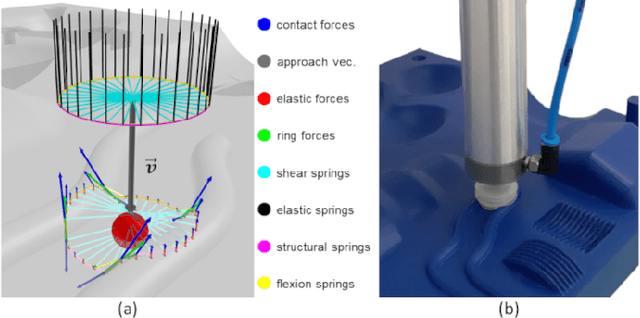
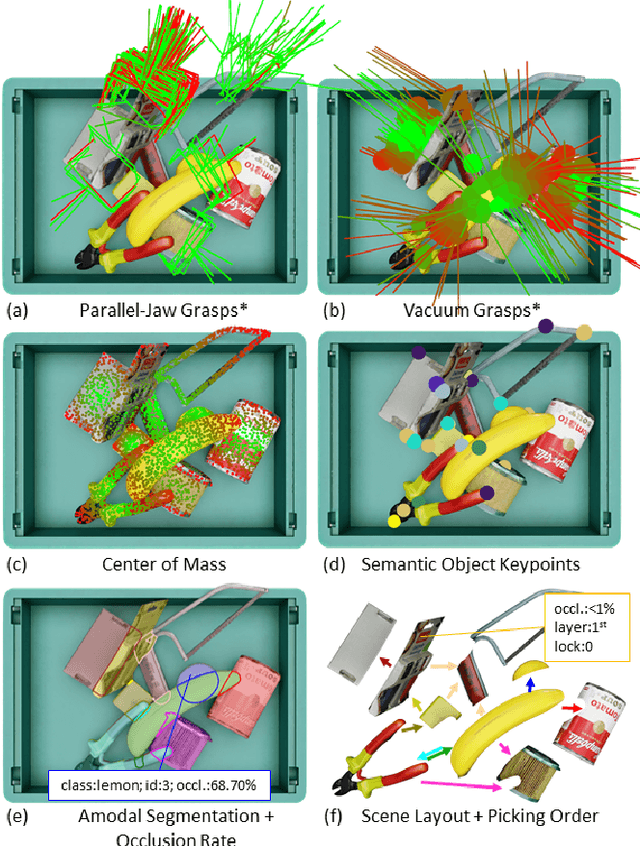
Autonomous bin picking poses significant challenges to vision-driven robotic systems given the complexity of the problem, ranging from various sensor modalities, to highly entangled object layouts, to diverse item properties and gripper types. Existing methods often address the problem from one perspective. Diverse items and complex bin scenes require diverse picking strategies together with advanced reasoning. As such, to build robust and effective machine-learning algorithms for solving this complex task requires significant amounts of comprehensive and high quality data. Collecting such data in real world would be too expensive and time prohibitive and therefore intractable from a scalability perspective. To tackle this big, diverse data problem, we take inspiration from the recent rise in the concept of metaverses, and introduce MetaGraspNet, a large-scale photo-realistic bin picking dataset constructed via physics-based metaverse synthesis. The proposed dataset contains 217k RGBD images across 82 different article types, with full annotations for object detection, amodal perception, keypoint detection, manipulation order and ambidextrous grasp labels for a parallel-jaw and vacuum gripper. We also provide a real dataset consisting of over 2.3k fully annotated high-quality RGBD images, divided into 5 levels of difficulties and an unseen object set to evaluate different object and layout properties. Finally, we conduct extensive experiments showing that our proposed vacuum seal model and synthetic dataset achieves state-of-the-art performance and generalizes to real world use-cases.
MetaGraspNet: A Large-Scale Benchmark Dataset for Vision-driven Robotic Grasping via Physics-based Metaverse Synthesis
Dec 30, 2021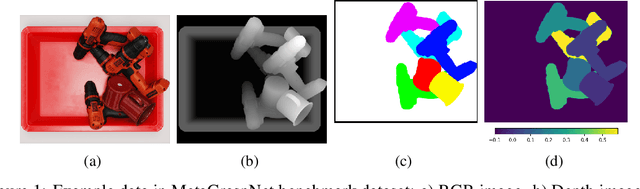
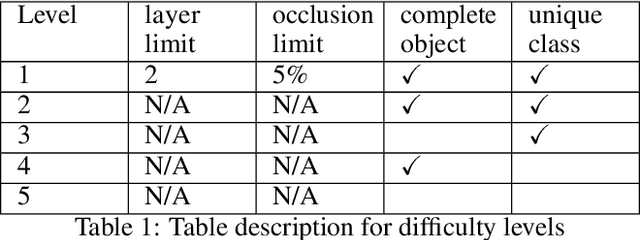

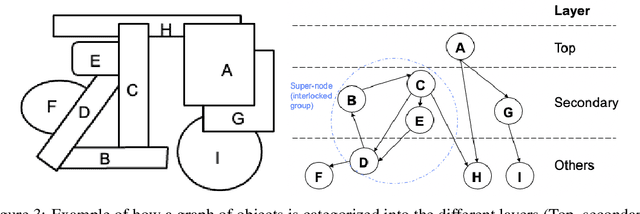
There has been increasing interest in smart factories powered by robotics systems to tackle repetitive, laborious tasks. One impactful yet challenging task in robotics-powered smart factory applications is robotic grasping: using robotic arms to grasp objects autonomously in different settings. Robotic grasping requires a variety of computer vision tasks such as object detection, segmentation, grasp prediction, pick planning, etc. While significant progress has been made in leveraging of machine learning for robotic grasping, particularly with deep learning, a big challenge remains in the need for large-scale, high-quality RGBD datasets that cover a wide diversity of scenarios and permutations. To tackle this big, diverse data problem, we are inspired by the recent rise in the concept of metaverse, which has greatly closed the gap between virtual worlds and the physical world. Metaverses allow us to create digital twins of real-world manufacturing scenarios and to virtually create different scenarios from which large volumes of data can be generated for training models. In this paper, we present MetaGraspNet: a large-scale benchmark dataset for vision-driven robotic grasping via physics-based metaverse synthesis. The proposed dataset contains 100,000 images and 25 different object types and is split into 5 difficulties to evaluate object detection and segmentation model performance in different grasping scenarios. We also propose a new layout-weighted performance metric alongside the dataset for evaluating object detection and segmentation performance in a manner that is more appropriate for robotic grasp applications compared to existing general-purpose performance metrics. Our benchmark dataset is available open-source on Kaggle, with the first phase consisting of detailed object detection, segmentation, layout annotations, and a layout-weighted performance metric script.