 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIitb Corridor
Papers and Code
A New Comprehensive Benchmark for Semi-supervised Video Anomaly Detection and Anticipation
May 23, 2023



Semi-supervised video anomaly detection (VAD) is a critical task in the intelligent surveillance system. However, an essential type of anomaly in VAD named scene-dependent anomaly has not received the attention of researchers. Moreover, there is no research investigating anomaly anticipation, a more significant task for preventing the occurrence of anomalous events. To this end, we propose a new comprehensive dataset, NWPU Campus, containing 43 scenes, 28 classes of abnormal events, and 16 hours of videos. At present, it is the largest semi-supervised VAD dataset with the largest number of scenes and classes of anomalies, the longest duration, and the only one considering the scene-dependent anomaly. Meanwhile, it is also the first dataset proposed for video anomaly anticipation. We further propose a novel model capable of detecting and anticipating anomalous events simultaneously. Compared with 7 outstanding VAD algorithms in recent years, our method can cope with scene-dependent anomaly detection and anomaly anticipation both well, achieving state-of-the-art performance on ShanghaiTech, CUHK Avenue, IITB Corridor and the newly proposed NWPU Campus datasets consistently. Our dataset and code is available at: https://campusvad.github.io.
Human-Scene Network: A Novel Baseline with Self-rectifying Loss for Weakly supervised Video Anomaly Detection
Jan 19, 2023



Video anomaly detection in surveillance systems with only video-level labels (i.e. weakly-supervised) is challenging. This is due to, (i) the complex integration of human and scene based anomalies comprising of subtle and sharp spatio-temporal cues in real-world scenarios, (ii) non-optimal optimization between normal and anomaly instances under weak supervision. In this paper, we propose a Human-Scene Network to learn discriminative representations by capturing both subtle and strong cues in a dissociative manner. In addition, a self-rectifying loss is also proposed that dynamically computes the pseudo temporal annotations from video-level labels for optimizing the Human-Scene Network effectively. The proposed Human-Scene Network optimized with self-rectifying loss is validated on three publicly available datasets i.e. UCF-Crime, ShanghaiTech and IITB-Corridor, outperforming recently reported state-of-the-art approaches on five out of the six scenarios considered.
A Hierarchical Spatio-Temporal Graph Convolutional Neural Network for Anomaly Detection in Videos
Dec 10, 2021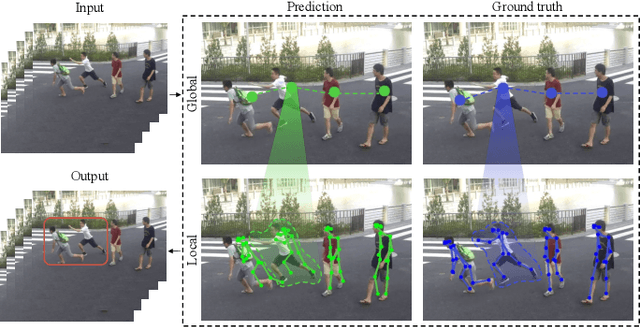
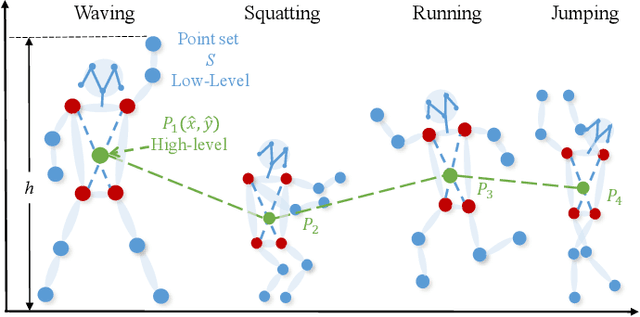
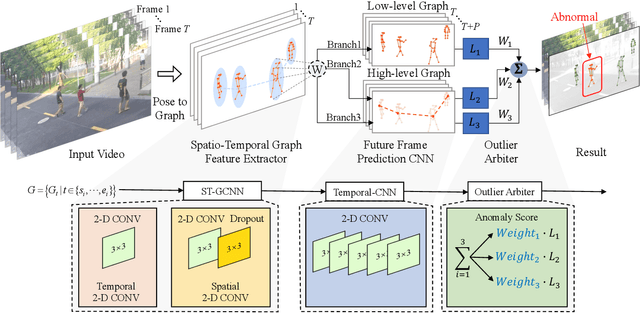
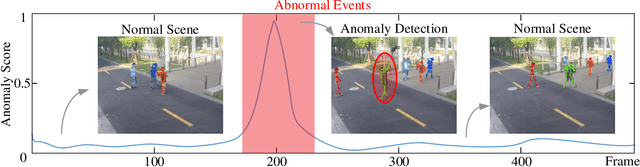
Deep learning models have been widely used for anomaly detection in surveillance videos. Typical models are equipped with the capability to reconstruct normal videos and evaluate the reconstruction errors on anomalous videos to indicate the extent of abnormalities. However, existing approaches suffer from two disadvantages. Firstly, they can only encode the movements of each identity independently, without considering the interactions among identities which may also indicate anomalies. Secondly, they leverage inflexible models whose structures are fixed under different scenes, this configuration disables the understanding of scenes. In this paper, we propose a Hierarchical Spatio-Temporal Graph Convolutional Neural Network (HSTGCNN) to address these problems, the HSTGCNN is composed of multiple branches that correspond to different levels of graph representations. High-level graph representations encode the trajectories of people and the interactions among multiple identities while low-level graph representations encode the local body postures of each person. Furthermore, we propose to weightedly combine multiple branches that are better at different scenes. An improvement over single-level graph representations is achieved in this way. An understanding of scenes is achieved and serves anomaly detection. High-level graph representations are assigned higher weights to encode moving speed and directions of people in low-resolution videos while low-level graph representations are assigned higher weights to encode human skeletons in high-resolution videos. Experimental results show that the proposed HSTGCNN significantly outperforms current state-of-the-art models on four benchmark datasets (UCSD Pedestrian, ShanghaiTech, CUHK Avenue and IITB-Corridor) by using much less learnable parameters.