 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrum Transcription
Drum transcription is the process of converting drum audio recordings into drum notation or MIDI data.
Papers and Code
STRUM: A Spectral Transcription and Rhythm Understanding Model for End-to-End Generation of Playable Rhythm-Game Charts
May 12, 2026We present STRUM (Spectral Transcription and Rhythm Understanding Model), an audio-to-chart pipeline that converts raw recordings into playable Clone Hero / YARG charts for drums, guitar, bass, vocals, and keys without any oracle metadata. STRUM is a multi-stage hybrid: a two-stage CRNN onset detector and a six-model ensemble classifier for drums; neural onset detectors with monophonic pitch tracking for guitar and bass; word-aligned ASR for vocals; and spectral keyboard detection for keys. We evaluate on a 30-song in-envelope benchmark constructed by screening candidate songs on a single audio-quality criterion -- the median 1-second drum-stem RMS after htdemucs_6s source separation. On this benchmark STRUM achieves drums onset F1 = 0.838, bass F1 = 0.694, guitar F1 = 0.651, and vocals F1 = 0.539 at a +/- 100 ms tolerance with per-song global offset search. We report a complete ablation of seven drum-pipeline components with paired per-song Wilcoxon tests, an analysis of ground-truth-to-audio timing distributions in community Clone Hero charts, and a per-class confusion matrix for the drum classifier. Code, model weights, and the full benchmark manifest are released.
Towards Realistic Synthetic Data for Automatic Drum Transcription
Jan 14, 2026Deep learning models define the state-of-the-art in Automatic Drum Transcription (ADT), yet their performance is contingent upon large-scale, paired audio-MIDI datasets, which are scarce. Existing workarounds that use synthetic data often introduce a significant domain gap, as they typically rely on low-fidelity SoundFont libraries that lack acoustic diversity. While high-quality one-shot samples offer a better alternative, they are not available in a standardized, large-scale format suitable for training. This paper introduces a new paradigm for ADT that circumvents the need for paired audio-MIDI training data. Our primary contribution is a semi-supervised method to automatically curate a large and diverse corpus of one-shot drum samples from unlabeled audio sources. We then use this corpus to synthesize a high-quality dataset from MIDI files alone, which we use to train a sequence-to-sequence transcription model. We evaluate our model on the ENST and MDB test sets, where it achieves new state-of-the-art results, significantly outperforming both fully supervised methods and previous synthetic-data approaches. The code for reproducing our experiments is publicly available at https://github.com/pier-maker92/ADT_STR
The Inverse Drum Machine: Source Separation Through Joint Transcription and Analysis-by-Synthesis
May 06, 2025



We introduce the Inverse Drum Machine (IDM), a novel approach to drum source separation that combines analysis-by-synthesis with deep learning. Unlike recent supervised methods that rely on isolated stems, IDM requires only transcription annotations. It jointly optimizes automatic drum transcription and one-shot drum sample synthesis in an end-to-end framework. By convolving synthesized one-shot samples with estimated onsets-mimicking a drum machine-IDM reconstructs individual drum stems and trains a neural network to match the original mixture. Evaluations on the StemGMD dataset show that IDM achieves separation performance on par with state-of-the-art supervised methods, while substantially outperforming matrix decomposition baselines.
Meta-learning-based percussion transcription and $t\bar{a}la$ identification from low-resource audio
Jan 08, 2025



This study introduces a meta-learning-based approach for low-resource Tabla Stroke Transcription (TST) and $t\bar{a}la$ identification in Hindustani classical music. Using Model-Agnostic Meta-Learning (MAML), we address the challenge of limited annotated datasets, enabling rapid adaptation to new tasks with minimal data. The method is validated across various datasets, including tabla solo and concert recordings, demonstrating robustness in polyphonic audio scenarios. We propose two novel $t\bar{a}la$ identification techniques based on stroke sequences and rhythmic patterns. Additionally, the approach proves effective for Automatic Drum Transcription (ADT), showcasing its flexibility for Indian and Western percussion music. Experimental results show that the proposed method outperforms existing techniques in low-resource settings, significantly contributing to music transcription and studying musical traditions through computational tools.
Music Tempo Estimation on Solo Instrumental Performance
Apr 25, 2025Recently, automatic music transcription has made it possible to convert musical audio into accurate MIDI. However, the resulting MIDI lacks music notations such as tempo, which hinders its conversion into sheet music. In this paper, we investigate state-of-the-art tempo estimation techniques and evaluate their performance on solo instrumental music. These include temporal convolutional network (TCN) and recurrent neural network (RNN) models that are pretrained on massive of mixed vocals and instrumental music, as well as TCN models trained specifically with solo instrumental performances. Through evaluations on drum, guitar, and classical piano datasets, our TCN models with the new training scheme achieved the best performance. Our newly trained TCN model increases the Acc1 metric by 38.6% for guitar tempo estimation, compared to the pretrained TCN model with an Acc1 of 61.1%. Although our trained TCN model is twice as accurate as the pretrained TCN model in estimating classical piano tempo, its Acc1 is only 50.9%. To improve the performance of deep learning models, we investigate their combinations with various post-processing methods. These post-processing techniques effectively enhance the performance of deep learning models when they struggle to estimate the tempo of specific instruments.
Analyzing and reducing the synthetic-to-real transfer gap in Music Information Retrieval: the task of automatic drum transcription
Jul 29, 2024



Automatic drum transcription is a critical tool in Music Information Retrieval for extracting and analyzing the rhythm of a music track, but it is limited by the size of the datasets available for training. A popular method used to increase the amount of data is by generating them synthetically from music scores rendered with virtual instruments. This method can produce a virtually infinite quantity of tracks, but empirical evidence shows that models trained on previously created synthetic datasets do not transfer well to real tracks. In this work, besides increasing the amount of data, we identify and evaluate three more strategies that practitioners can use to improve the realism of the generated data and, thus, narrow the synthetic-to-real transfer gap. To explore their efficacy, we used them to build a new synthetic dataset and then we measured how the performance of a model scales and, specifically, at what value it will stagnate when increasing the number of training tracks for different datasets. By doing this, we were able to prove that the aforementioned strategies contribute to make our dataset the one with the most realistic data distribution and the lowest synthetic-to-real transfer gap among the synthetic datasets we evaluated. We conclude by highlighting the limits of training with infinite data in drum transcription and we show how they can be overcome.
AIoT-Based Drum Transcription Robot using Convolutional Neural Networks
Aug 29, 2023With the development of information technology, robot technology has made great progress in various fields. These new technologies enable robots to be used in industry, agriculture, education and other aspects. In this paper, we propose a drum robot that can automatically complete music transcription in real-time, which is based on AIoT and fog computing technology. Specifically, this drum robot system consists of a cloud node for data storage, edge nodes for real-time computing, and data-oriented execution application nodes. In order to analyze drumming music and realize drum transcription, we further propose a light-weight convolutional neural network model to classify drums, which can be more effectively deployed in terminal devices for fast edge calculations. The experimental results show that the proposed system can achieve more competitive performance and enjoy a variety of smart applications and services.
Improving Drumming Robot Via Attention Transformer Network
Oct 04, 2023

Robotic technology has been widely used in nowadays society, which has made great progress in various fields such as agriculture, manufacturing and entertainment. In this paper, we focus on the topic of drumming robots in entertainment. To this end, we introduce an improving drumming robot that can automatically complete music transcription based on the popular vision transformer network based on the attention mechanism. Equipped with the attention transformer network, our method can efficiently handle the sequential audio embedding input and model their global long-range dependencies. Massive experimental results demonstrate that the improving algorithm can help the drumming robot promote drum classification performance, which can also help the robot to enjoy a variety of smart applications and services.
Automatic Transcription of Drum Strokes in Carnatic Music
Nov 28, 2022The mridangam is a double-headed percussion instrument that plays a key role in Carnatic music concerts. This paper presents a novel automatic transcription algorithm to classify the strokes played on the mridangam. Onset detection is first performed to segment the audio signal into individual strokes, and feature vectors consisting of the DFT magnitude spectrum of the segmented signal are generated. A multi-layer feedforward neural network is trained using the feature vectors as inputs and the manual transcriptions as targets. Since the mridangam is a tonal instrument tuned to a given tonic, tonic invariance is an important feature of the classifier. Tonic invariance is achieved by augmenting the dataset with pitch-shifted copies of the audio. This algorithm consistently yields over 83% accuracy on a held-out test dataset.
ADTOF: A large dataset of non-synthetic music for automatic drum transcription
Nov 23, 2021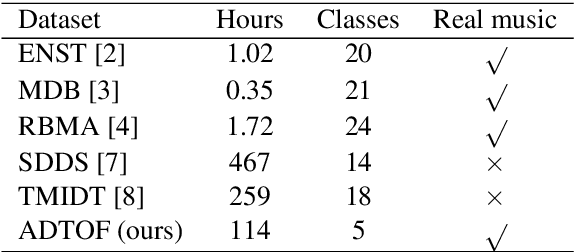

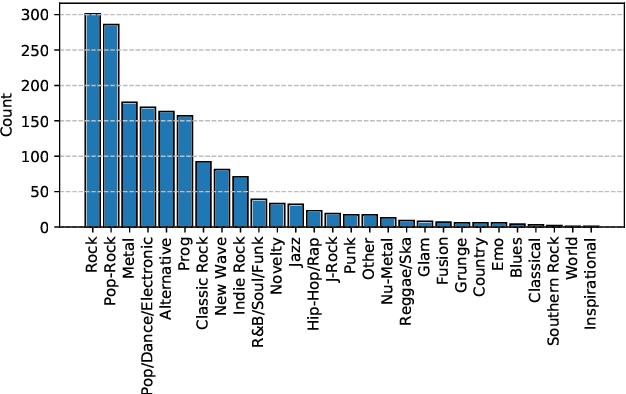
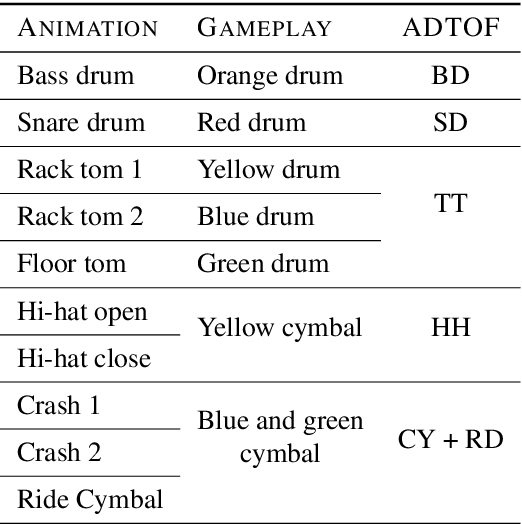
The state-of-the-art methods for drum transcription in the presence of melodic instruments (DTM) are machine learning models trained in a supervised manner, which means that they rely on labeled datasets. The problem is that the available public datasets are limited either in size or in realism, and are thus suboptimal for training purposes. Indeed, the best results are currently obtained via a rather convoluted multi-step training process that involves both real and synthetic datasets. To address this issue, starting from the observation that the communities of rhythm games players provide a large amount of annotated data, we curated a new dataset of crowdsourced drum transcriptions. This dataset contains real-world music, is manually annotated, and is about two orders of magnitude larger than any other non-synthetic dataset, making it a prime candidate for training purposes. However, due to crowdsourcing, the initial annotations contain mistakes. We discuss how the quality of the dataset can be improved by automatically correcting different types of mistakes. When used to train a popular DTM model, the dataset yields a performance that matches that of the state-of-the-art for DTM, thus demonstrating the quality of the annotations.