 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Uncertainty Quantification for Inverse Problems with Conditional Normalizing Flows
Paper and Code
Jul 15, 2020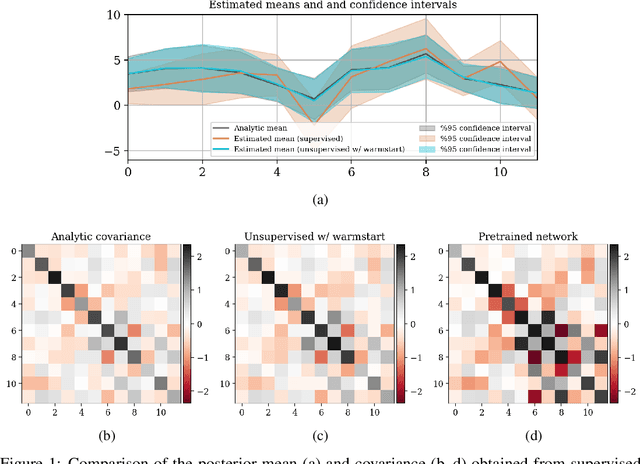
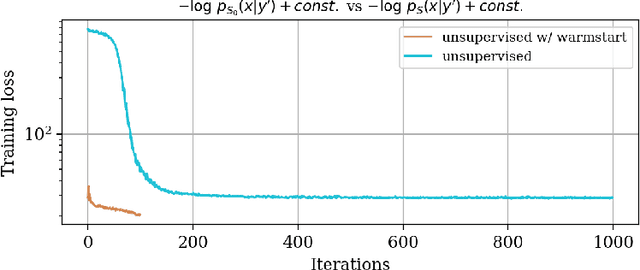
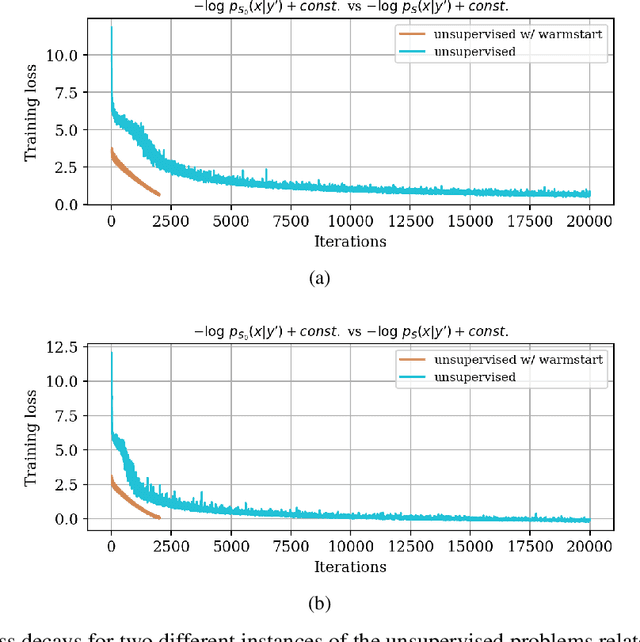
In inverse problems, we often have access to data consisting of paired samples $(x,y)\sim p_{X,Y}(x,y)$ where $y$ are partial observations of a physical system, and $x$ represents the unknowns of the problem. Under these circumstances, we can employ supervised training to learn a solution $x$ and its uncertainty from the observations $y$. We refer to this problem as the "supervised" case. However, the data $y\sim p_{Y}(y)$ collected at one point could be distributed differently than observations $y'\sim p_{Y}'(y')$, relevant for a current set of problems. In the context of Bayesian inference, we propose a two-step scheme, which makes use of normalizing flows and joint data to train a conditional generator $q_{\theta}(x|y)$ to approximate the target posterior density $p_{X|Y}(x|y)$. Additionally, this preliminary phase provides a density function $q_{\theta}(x|y)$, which can be recast as a prior for the "unsupervised" problem, e.g.~when only the observations $y'\sim p_{Y}'(y')$, a likelihood model $y'|x$, and a prior on $x'$ are known. We then train another invertible generator with output density $q'_{\phi}(x|y')$ specifically for $y'$, allowing us to sample from the posterior $p_{X|Y}'(x|y')$. We present some synthetic results that demonstrate considerable training speedup when reusing the pretrained network $q_{\theta}(x|y')$ as a warm start or preconditioning for approximating $p_{X|Y}'(x|y')$, instead of learning from scratch. This training modality can be interpreted as an instance of transfer learning. This result is particularly relevant for large-scale inverse problems that employ expensive numerical simulations.