 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Public Reference Implementation of the RAP Anaphora Resolution Algorithm
Paper and Code
Jun 17, 2004
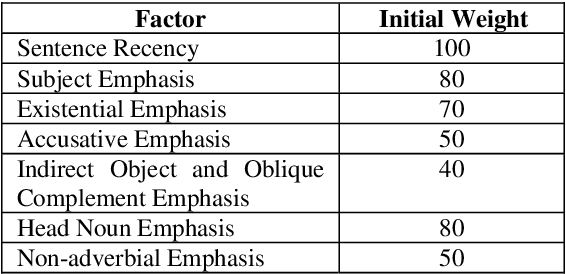
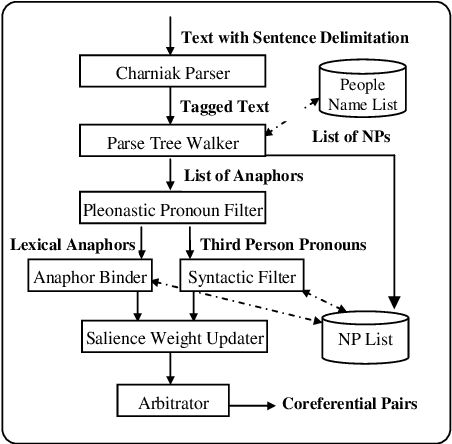

This paper describes a standalone, publicly-available implementation of the Resolution of Anaphora Procedure (RAP) given by Lappin and Leass (1994). The RAP algorithm resolves third person pronouns, lexical anaphors, and identifies pleonastic pronouns. Our implementation, JavaRAP, fills a current need in anaphora resolution research by providing a reference implementation that can be benchmarked against current algorithms. The implementation uses the standard, publicly available Charniak (2000) parser as input, and generates a list of anaphora-antecedent pairs as output. Alternately, an in-place annotation or substitution of the anaphors with their antecedents can be produced. Evaluation on the MUC-6 co-reference task shows that JavaRAP has an accuracy of 57.9%, similar to the performance given previously in the literature (e.g., Preiss 2002).