 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific NER via Retrieving Correlated Samples
Paper and Code
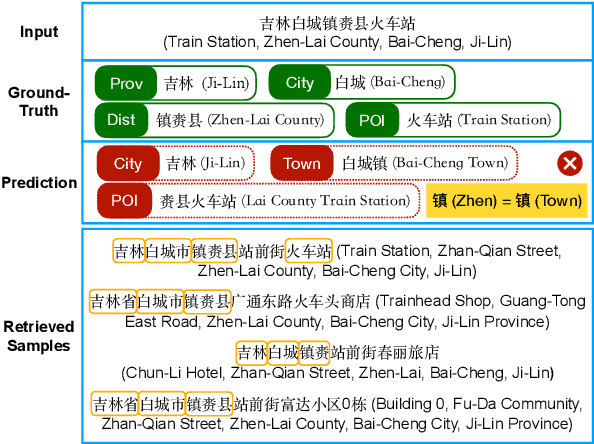
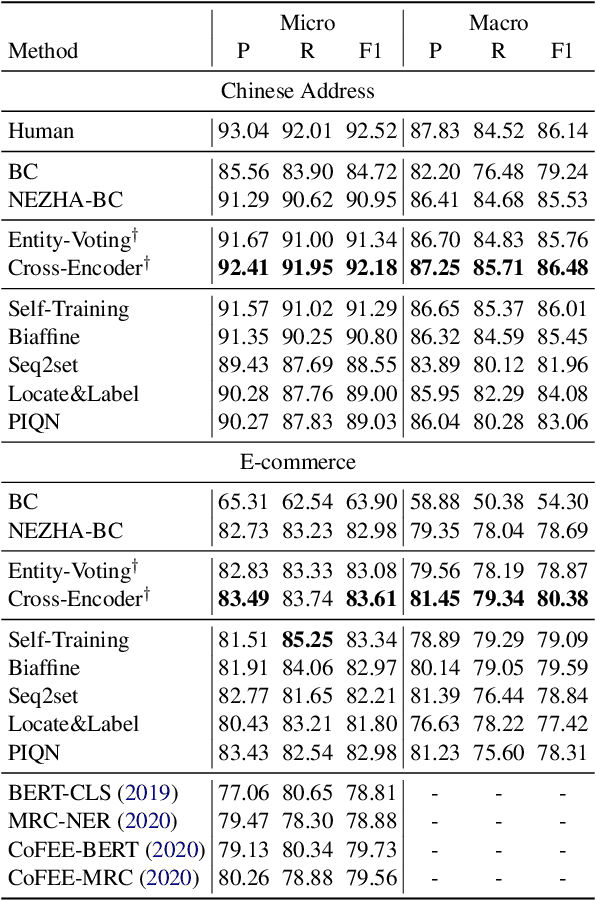
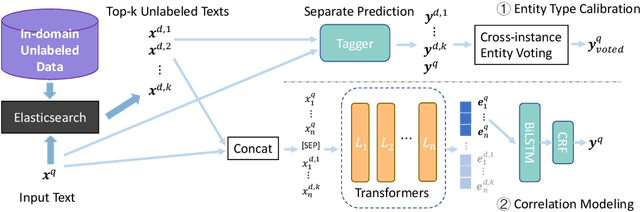
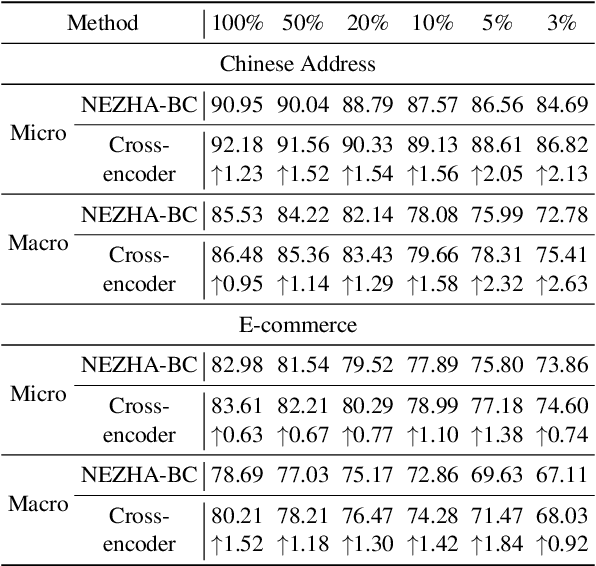
Successful Machine Learning based Named Entity Recognition models could fail on texts from some special domains, for instance, Chinese addresses and e-commerce titles, where requires adequate background knowledge. Such texts are also difficult for human annotators. In fact, we can obtain some potentially helpful information from correlated texts, which have some common entities, to help the text understanding. Then, one can easily reason out the correct answer by referencing correlated samples. In this paper, we suggest enhancing NER models with correlated samples. We draw correlated samples by the sparse BM25 retriever from large-scale in-domain unlabeled data. To explicitly simulate the human reasoning process, we perform a training-free entity type calibrating by majority voting. To capture correlation features in the training stage, we suggest to model correlated samples by the transformer-based multi-instance cross-encoder. Empirical results on datasets of the above two domains show the efficacy of our methods.