 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Causal Relational Reasoning for Event-Level Visual Question Answering
Paper and Code
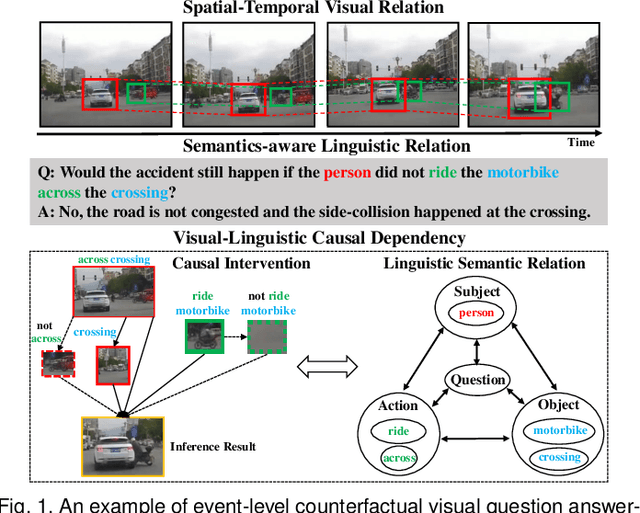
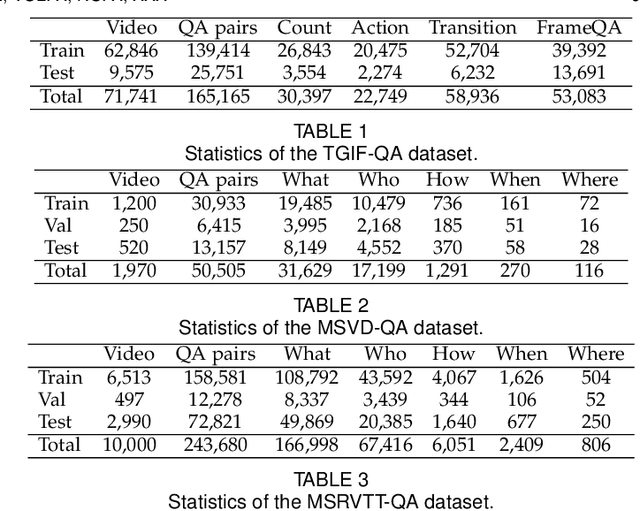
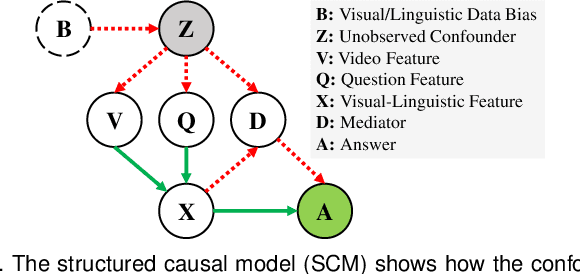
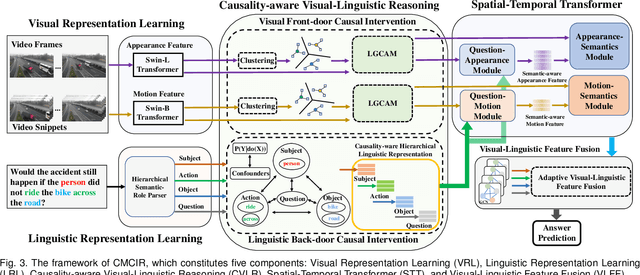
Existing visual question answering methods tend to capture the spurious correlations from visual and linguistic modalities, and fail to discover the true casual mechanism that facilitates reasoning truthfully based on the dominant visual evidence and the correct question intention. Additionally, the existing methods usually ignore the complex event-level understanding in multi-modal settings that requires a strong cognitive capability of causal inference to jointly model cross-modal event temporality, causality, and dynamics. In this work, we focus on event-level visual question answering from a new perspective, i.e., cross-modal causal relational reasoning, by introducing causal intervention methods to mitigate the spurious correlations and discover the true causal structures for the integration of visual and linguistic modalities. Specifically, we propose a novel event-level visual question answering framework named Cross-Modal Causal RelatIonal Reasoning (CMCIR), to achieve robust casuality-aware visual-linguistic question answering. To uncover the causal structures for visual and linguistic modalities, the novel Causality-aware Visual-Linguistic Reasoning (CVLR) module is proposed to collaboratively disentangle the visual and linguistic spurious correlations via elaborately designed front-door and back-door causal intervention modules. To discover the fine-grained interactions between linguistic semantics and spatial-temporal representations, we build a novel Spatial-Temporal Transformer (STT) that builds the multi-modal co-occurrence interactions between visual and linguistic content. Extensive experiments on large-scale event-level urban dataset SUTD-TrafficQA and three benchmark real-world datasets TGIF-QA, MSVD-QA, and MSRVTT-QA demonstrate the effectiveness of our CMCIR for discovering visual-linguistic causal structures.