 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Cross-Domain Speech Recognition with Self-Supervision
Paper and Code
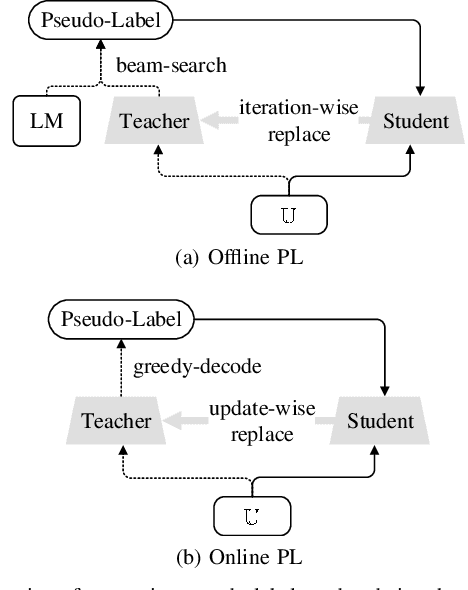
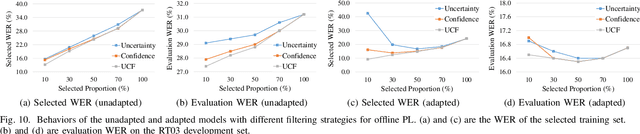
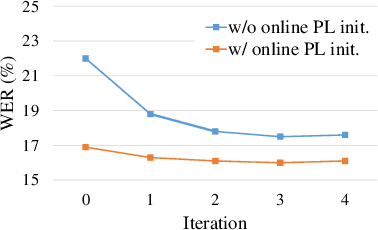
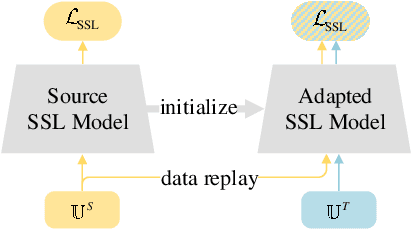
The cross-domain performance of automatic speech recognition (ASR) could be severely hampered due to the mismatch between training and testing distributions. Since the target domain usually lacks labeled data, and domain shifts exist at acoustic and linguistic levels, it is challenging to perform unsupervised domain adaptation (UDA) for ASR. Previous work has shown that self-supervised learning (SSL) or pseudo-labeling (PL) is effective in UDA by exploiting the self-supervisions of unlabeled data. However, these self-supervisions also face performance degradation in mismatched domain distributions, which previous work fails to address. This work presents a systematic UDA framework to fully utilize the unlabeled data with self-supervision in the pre-training and fine-tuning paradigm. On the one hand, we apply continued pre-training and data replay techniques to mitigate the domain mismatch of the SSL pre-trained model. On the other hand, we propose a domain-adaptive fine-tuning approach based on the PL technique with three unique modifications: Firstly, we design a dual-branch PL method to decrease the sensitivity to the erroneous pseudo-labels; Secondly, we devise an uncertainty-aware confidence filtering strategy to improve pseudo-label correctness; Thirdly, we introduce a two-step PL approach to incorporate target domain linguistic knowledge, thus generating more accurate target domain pseudo-labels. Experimental results on various cross-domain scenarios demonstrate that the proposed approach could effectively boost the cross-domain performance and significantly outperform previous approaches.