 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMAE: Single Model Masked Pretraining on Images and Videos
Paper and Code
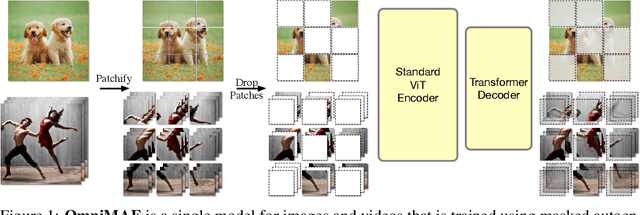

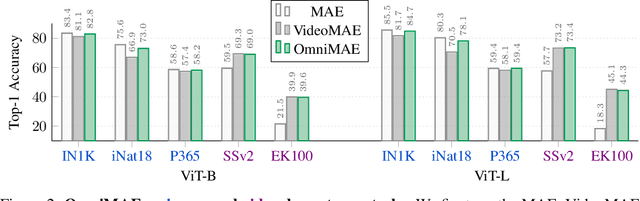
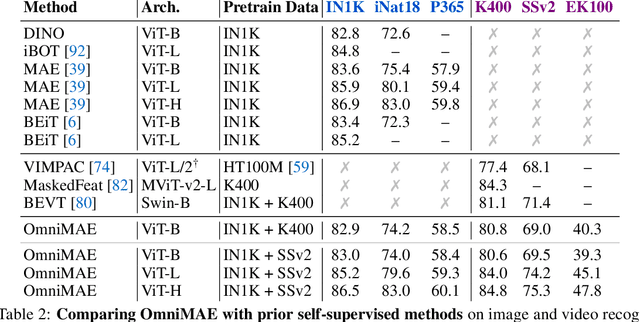
Transformer-based architectures have become competitive across a variety of visual domains, most notably images and videos. While prior work has studied these modalities in isolation, having a common architecture suggests that one can train a single unified model for multiple visual modalities. Prior attempts at unified modeling typically use architectures tailored for vision tasks, or obtain worse performance compared to single modality models. In this work, we show that masked autoencoding can be used to train a simple Vision Transformer on images and videos, without requiring any labeled data. This single model learns visual representations that are comparable to or better than single-modality representations on both image and video benchmarks, while using a much simpler architecture. In particular, our single pretrained model can be finetuned to achieve 86.5% on ImageNet and 75.3% on the challenging Something Something-v2 video benchmark. Furthermore, this model can be learned by dropping 90% of the image and 95% of the video patches, enabling extremely fast training.