 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Hyper-Initializer for All Network Architectures in Medical Image Analysis
Paper and Code
Jun 08, 2022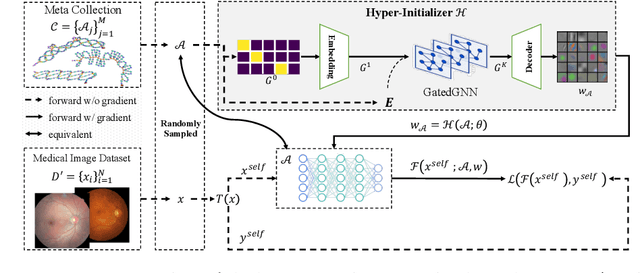
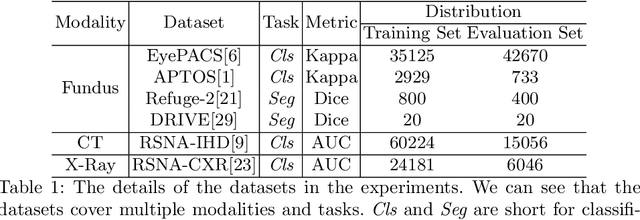
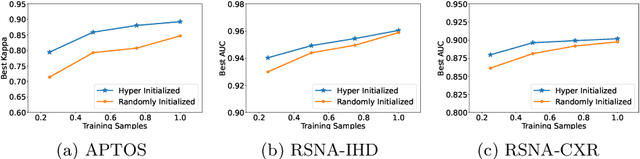
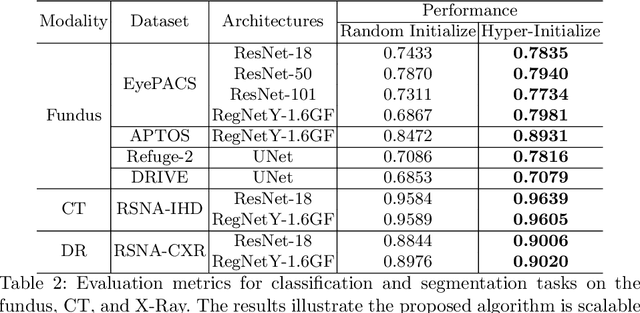
Pre-training is essential to deep learning model performance, especially in medical image analysis tasks where limited training data are available. However, existing pre-training methods are inflexible as the pre-trained weights of one model cannot be reused by other network architectures. In this paper, we propose an architecture-irrelevant hyper-initializer, which can initialize any given network architecture well after being pre-trained for only once. The proposed initializer is a hypernetwork which takes a downstream architecture as input graphs and outputs the initialization parameters of the respective architecture. We show the effectiveness and efficiency of the hyper-initializer through extensive experimental results on multiple medical imaging modalities, especially in data-limited fields. Moreover, we prove that the proposed algorithm can be reused as a favorable plug-and-play initializer for any downstream architecture and task (both classification and segmentation) of the same modality.