 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Spatial-Temporal and Appearance Modeling with Transformer for Multiple Object Tracking
Paper and Code
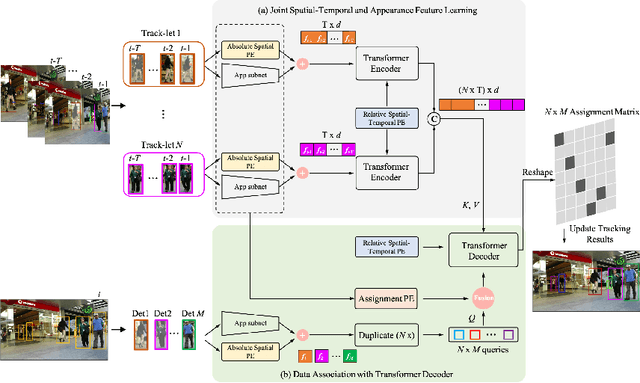

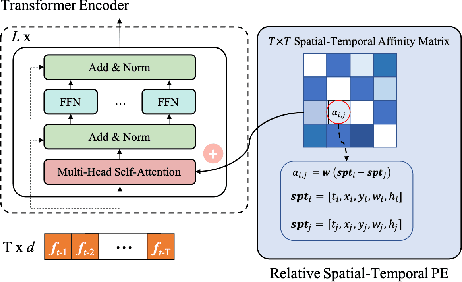
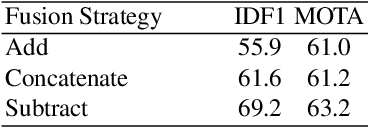
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. In this paper, we propose a novel solution named TransSTAM, which leverages Transformer to effectively model both the appearance features of each object and the spatial-temporal relationships among objects. TransSTAM consists of two major parts: (1) The encoder utilizes the powerful self-attention mechanism of Transformer to learn discriminative features for each tracklet; (2) The decoder adopts the standard cross-attention mechanism to model the affinities between the tracklets and the detections by taking both spatial-temporal and appearance features into account. TransSTAM has two major advantages: (1) It is solely based on the encoder-decoder architecture and enjoys a compact network design, hence being computationally efficient; (2) It can effectively learn spatial-temporal and appearance features within one model, hence achieving better tracking accuracy. The proposed method is evaluated on multiple public benchmarks including MOT16, MOT17, and MOT20, and it achieves a clear performance improvement in both IDF1 and HOTA with respect to previous state-of-the-art approaches on all the benchmarks. Our code is available at \url{https://github.com/icicle4/TranSTAM}.