 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPED: A Large-Scale Chinese Personalized and Emotional Dialogue Dataset for Conversational AI
Paper and Code
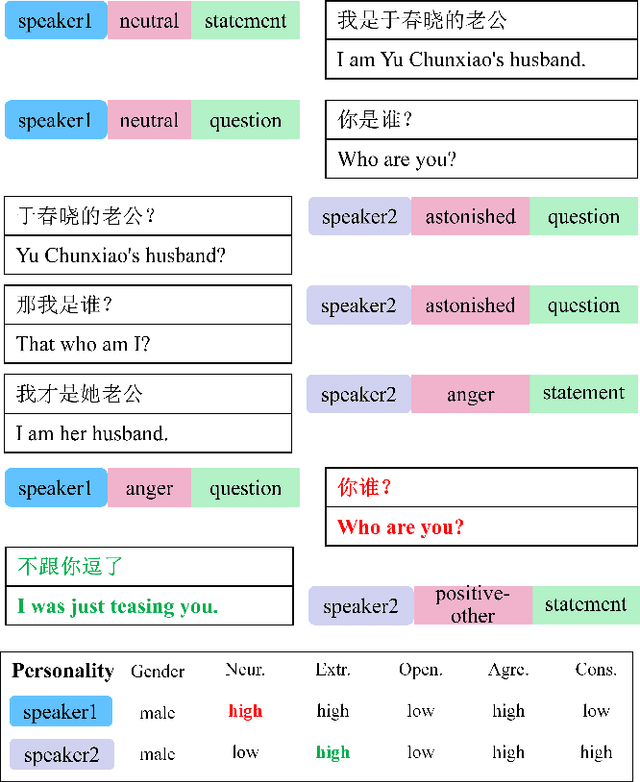

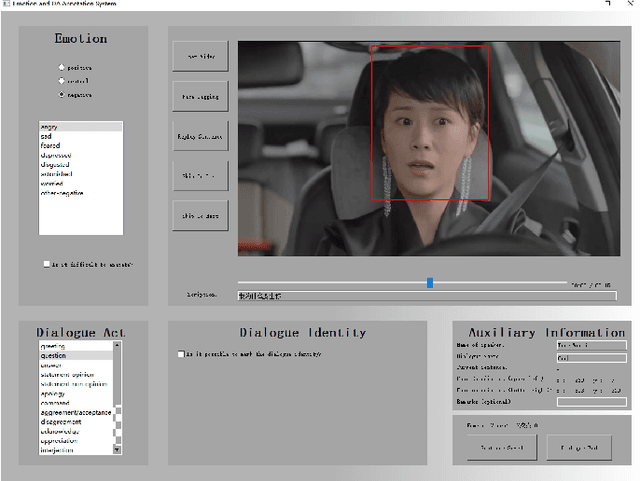
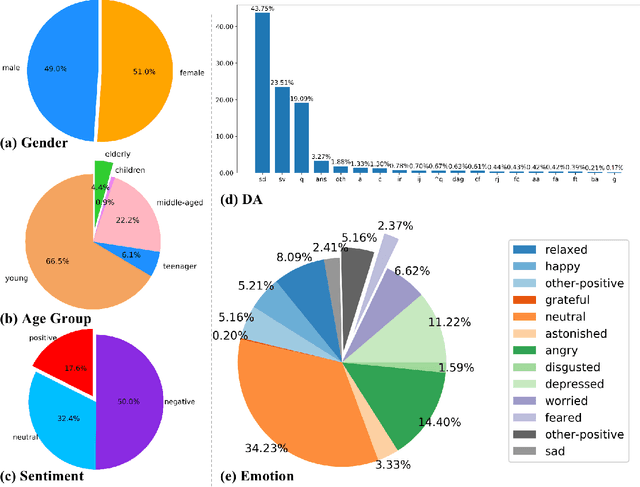
Human language expression is based on the subjective construal of the situation instead of the objective truth conditions, which means that speakers' personalities and emotions after cognitive processing have an important influence on conversation. However, most existing datasets for conversational AI ignore human personalities and emotions, or only consider part of them. It's difficult for dialogue systems to understand speakers' personalities and emotions although large-scale pre-training language models have been widely used. In order to consider both personalities and emotions in the process of conversation generation, we propose CPED, a large-scale Chinese personalized and emotional dialogue dataset, which consists of multi-source knowledge related to empathy and personal characteristic. These knowledge covers gender, Big Five personality traits, 13 emotions, 19 dialogue acts and 10 scenes. CPED contains more than 12K dialogues of 392 speakers from 40 TV shows. We release the textual dataset with audio features and video features according to the copyright claims, privacy issues, terms of service of video platforms. We provide detailed description of the CPED construction process and introduce three tasks for conversational AI, including personality recognition, emotion recognition in conversations as well as personalized and emotional conversation generation. Finally, we provide baseline systems for these tasks and consider the function of speakers' personalities and emotions on conversation. Our motivation is to propose a dataset to be widely adopted by the NLP community as a new open benchmark for conversational AI research. The full dataset is available at https://github.com/scutcyr/CPED.