 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Calibration for Question Answering
Paper and Code
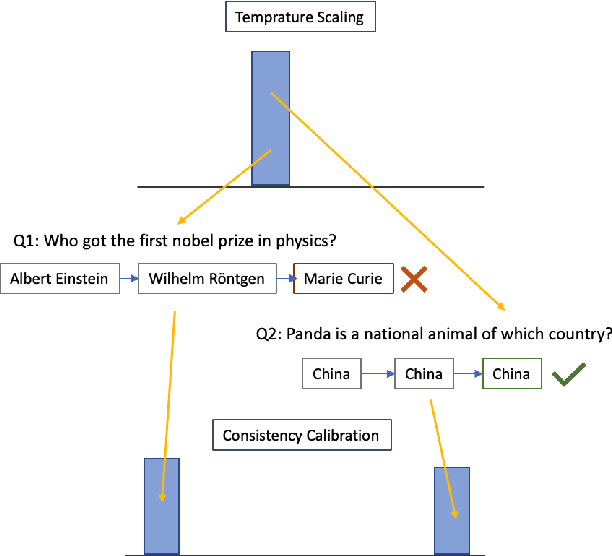
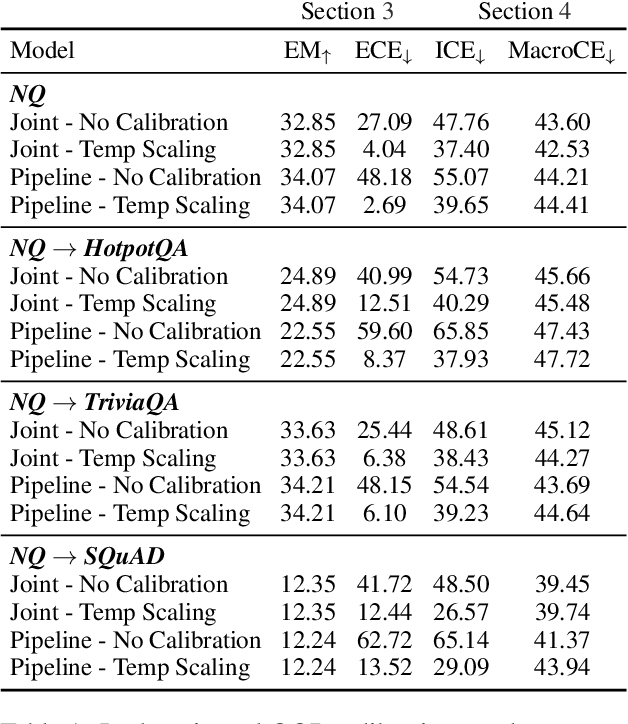
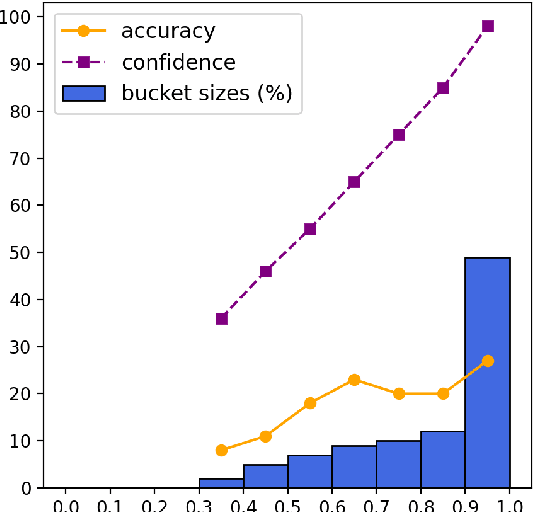
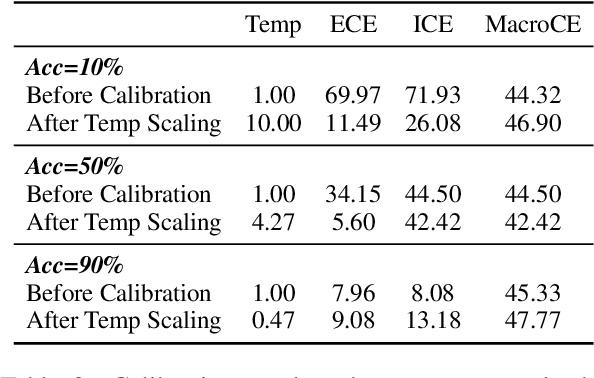
Model calibration aims to adjust (calibrate) models' confidence so that they match expected accuracy. We argue that the traditional evaluation of calibration (expected calibration error; ECE) does not reflect usefulness of the model confidence. For example, after conventional temperature scaling, confidence scores become similar for all predictions, which makes it hard for users to distinguish correct predictions from wrong ones, even though it achieves low ECE. Building on those observations, we propose a new calibration metric, MacroCE, that better captures whether the model assigns low confidence to wrong predictions and high confidence to correct predictions. We examine various conventional calibration methods including temperature scaling, feature-based classifier, neural answer reranking, and label smoothing, all of which do not bring significant gains under our new MacroCE metric. Towards more effective calibration, we propose a new calibration method based on the model's prediction consistency along the training trajectory. This new method, which we name as consistency calibration, shows promise for better calibration.