 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBBTv2: Pure Black-Box Optimization Can Be Comparable to Gradient Descent for Few-Shot Learning
Paper and Code
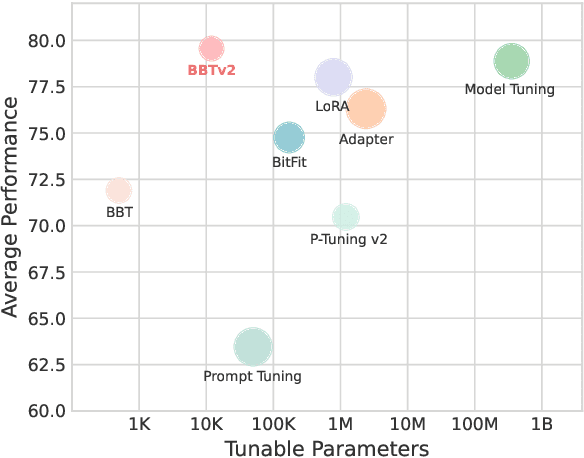
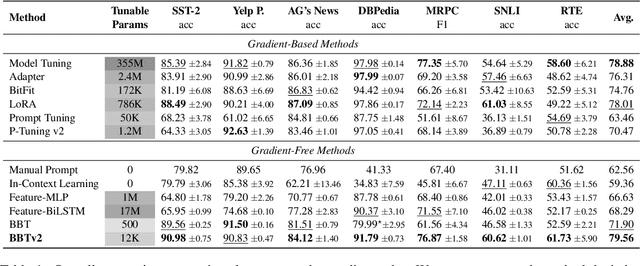
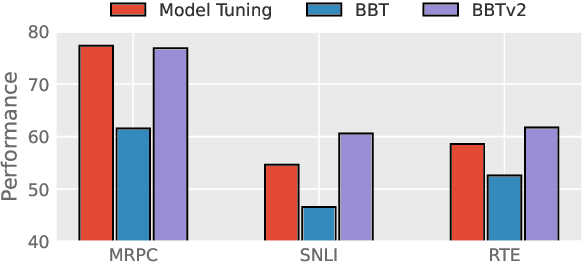
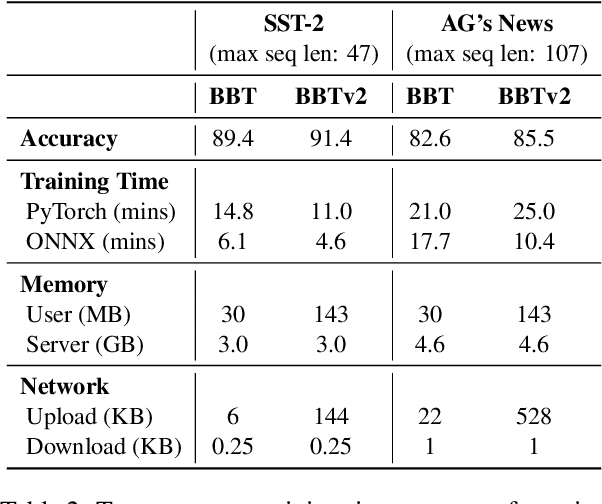
Black-Box Tuning (BBT) is a derivative-free approach to optimize continuous prompt tokens prepended to the input of language models. Although BBT has achieved comparable performance to full model tuning on simple classification tasks under few-shot settings, it requires pre-trained prompt embedding to match model tuning on hard tasks (e.g., entailment tasks), and therefore does not completely get rid of the dependence on gradients. In this paper we present BBTv2, a pure black-box optimization approach that can drive language models to achieve comparable results to gradient-based optimization. In particular, we prepend continuous prompt tokens to every layer of the language model and propose a divide-and-conquer algorithm to alternately optimize the prompt tokens at different layers. For the optimization at each layer, we perform derivative-free optimization in a low-dimensional subspace, which is then randomly projected to the original prompt parameter space. Experimental results show that BBTv2 not only outperforms BBT by a large margin, but also achieves comparable or even better performance than full model tuning and state-of-the-art parameter-efficient methods (e.g., Adapter, LoRA, BitFit, etc.) under few-shot learning settings, while maintaining much fewer tunable parameters.