 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Can See: Plugging Visual Controls in Text Generation
Paper and Code
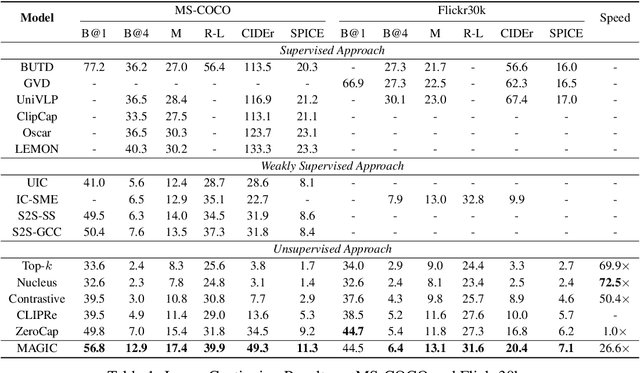

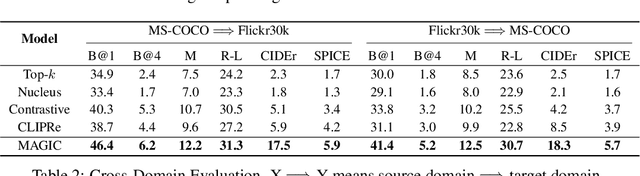

Generative language models (LMs) such as GPT-2/3 can be prompted to generate text with remarkable quality. While they are designed for text-prompted generation, it remains an open question how the generation process could be guided by modalities beyond text such as images. In this work, we propose a training-free framework, called MAGIC (iMAge-Guided text generatIon with CLIP), for plugging in visual controls in the generation process and enabling LMs to perform multimodal tasks (e.g., image captioning) in a zero-shot manner. MAGIC is a simple yet efficient plug-and-play framework, which directly combines an off-the-shelf LM (i.e., GPT-2) and an image-text matching model (i.e., CLIP) for image-grounded text generation. During decoding, MAGIC influences the generation of the LM by introducing a CLIP-induced score, called magic score, which regularizes the generated result to be semantically related to a given image while being coherent to the previously generated context. Notably, the proposed decoding scheme does not involve any gradient update operation, therefore being computationally efficient. On the challenging task of zero-shot image captioning, MAGIC outperforms the state-of-the-art method by notable margins with a nearly 27 times decoding speedup. MAGIC is a flexible framework and is theoretically compatible with any text generation tasks that incorporate image grounding. In the experiments, we showcase that it is also capable of performing visually grounded story generation given both an image and a text prompt.