 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Contrastive Learning for Self-supervised Action Recognition
Paper and Code
Apr 28, 2022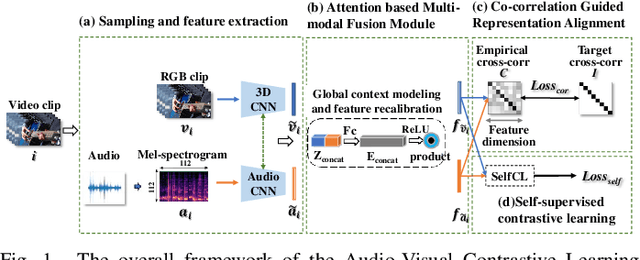


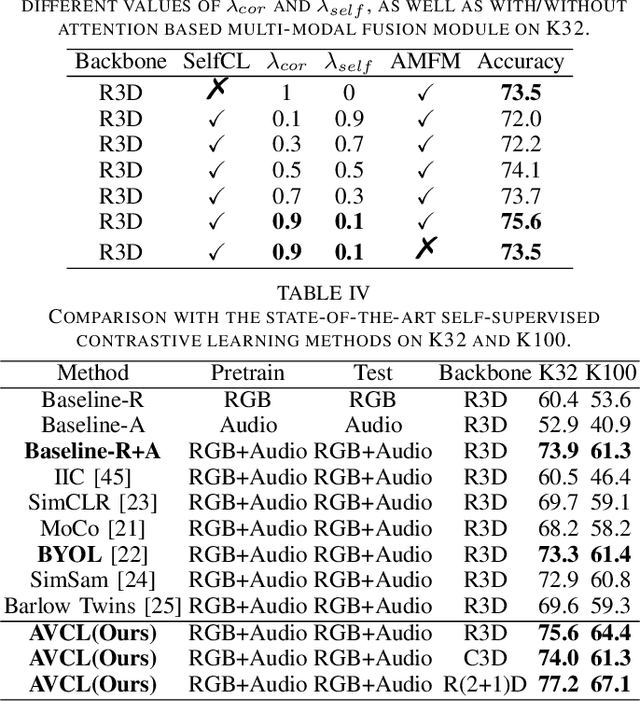
The underlying correlation between audio and visual modalities within videos can be utilized to learn supervised information for unlabeled videos. In this paper, we present an end-to-end self-supervised framework named Audio-Visual Contrastive Learning (AVCL), to learn discriminative audio-visual representations for action recognition. Specifically, we design an attention based multi-modal fusion module (AMFM) to fuse audio and visual modalities. To align heterogeneous audio-visual modalities, we construct a novel co-correlation guided representation alignment module (CGRA). To learn supervised information from unlabeled videos, we propose a novel self-supervised contrastive learning module (SelfCL). Furthermore, to expand the existing audio-visual action recognition datasets and better evaluate our framework AVCL, we build a new audio-visual action recognition dataset named Kinetics-Sounds100. Experimental results on Kinetics-Sounds32 and Kinetics-Sounds100 datasets demonstrate the superiority of our AVCL over the state-of-the-art methods on large-scale action recognition benchmark.