 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vocabulary-Free Multilingual Neural Tokenizer for End-to-End Task Learning
Paper and Code
Apr 22, 2022
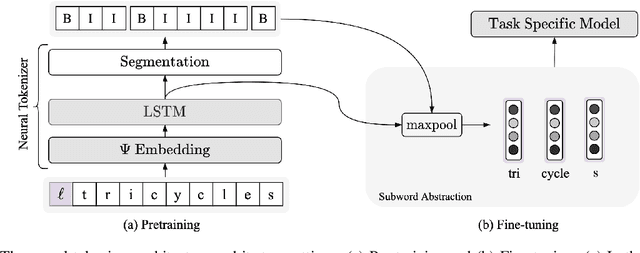
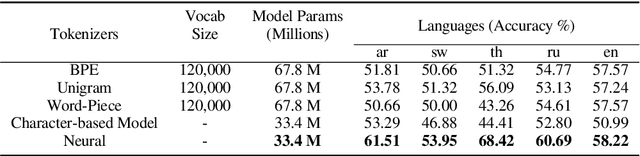

Subword tokenization is a commonly used input pre-processing step in most recent NLP models. However, it limits the models' ability to leverage end-to-end task learning. Its frequency-based vocabulary creation compromises tokenization in low-resource languages, leading models to produce suboptimal representations. Additionally, the dependency on a fixed vocabulary limits the subword models' adaptability across languages and domains. In this work, we propose a vocabulary-free neural tokenizer by distilling segmentation information from heuristic-based subword tokenization. We pre-train our character-based tokenizer by processing unique words from multilingual corpus, thereby extensively increasing word diversity across languages. Unlike the predefined and fixed vocabularies in subword methods, our tokenizer allows end-to-end task learning, resulting in optimal task-specific tokenization. The experimental results show that replacing the subword tokenizer with our neural tokenizer consistently improves performance on multilingual (NLI) and code-switching (sentiment analysis) tasks, with larger gains in low-resource languages. Additionally, our neural tokenizer exhibits a robust performance on downstream tasks when adversarial noise is present (typos and misspelling), further increasing the initial improvements over statistical subword tokenizers.