Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Source Separation with Generative Flow
Paper and Code
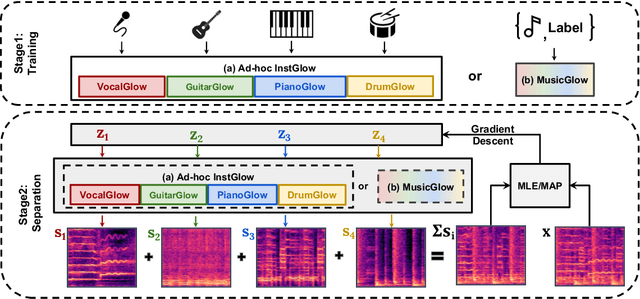
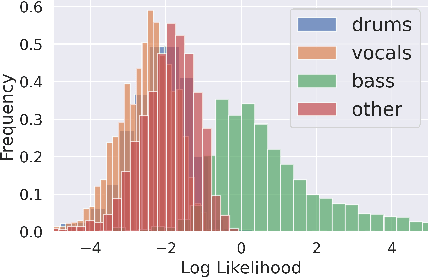
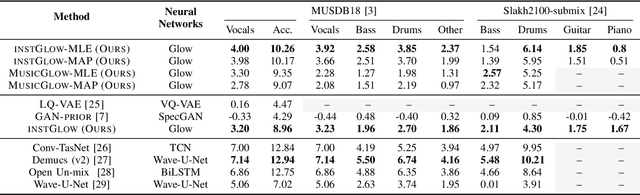
Full supervision models for source separation are trained on mixture-source parallel data and have achieved superior performance in recent years. However, large-scale and naturally mixed parallel training data are difficult to obtain for music, and such models are difficult to adapt to mixtures with new sources. Source-only supervision models, in contrast, only require clean sources for training; They learn source models and then apply these models to separate the mixture.
View paper on